# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在自动驾驶领域,VLA 大模型正从学术前沿走向产业落地的 “深水区”。近日,特斯拉(Tesla)在 ICCV 的分享中,就将其面临的核心挑战之一公之于众 ——“监督稀疏”。
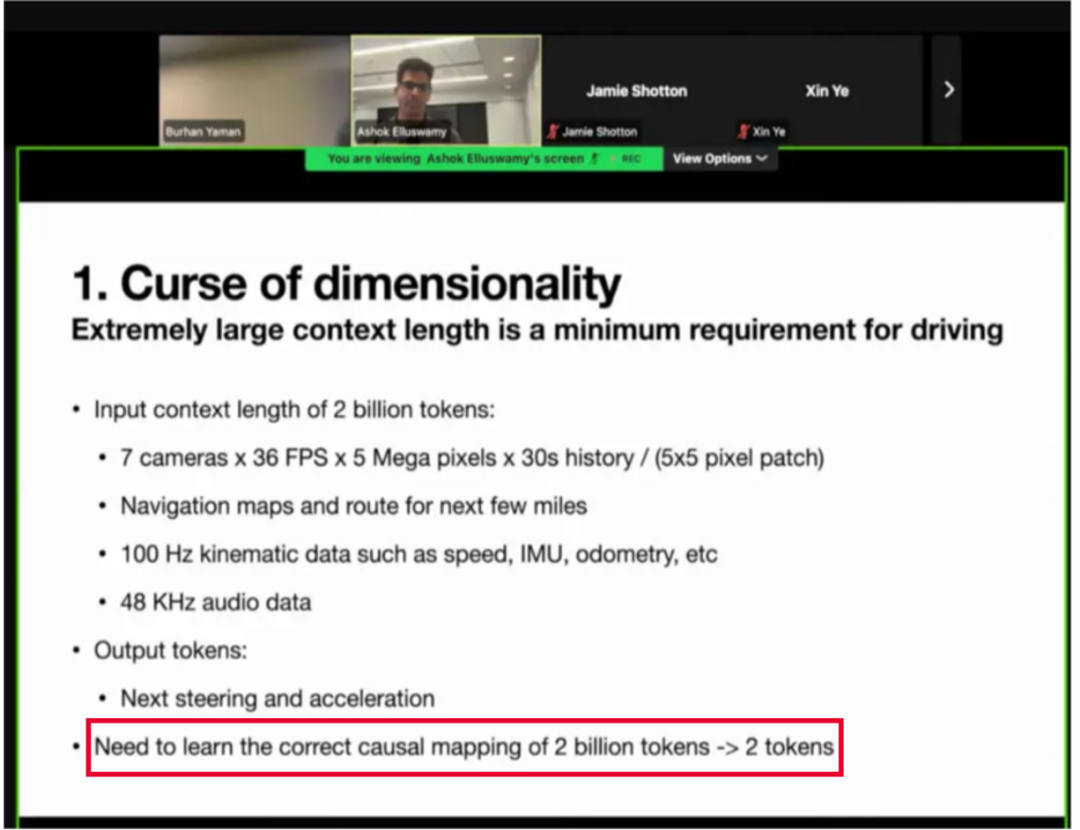
这一问题直指当前 VLA 模型的 “七寸”:其输入是高维、稠密的视觉信息流,但其监督信号却往往是低维、稀疏的驾驶动作(如路径点)。那么即便使用 PB 级的海量数据,VLA 模型的巨大潜力也无法被有效释放。
正当业界热议这一瓶颈时,一支来自国内顶尖学术机构与华为合作的团队,已经悄然给出了破解这一难题的 “锦囊”。一篇名为 《DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving》 的新工作,为解决这一 “监督稀疏” 提供了极具洞见的解决方案。该研究提出,世界模型(World Model)是解锁 VLA 数据规模定律(Data Scaling Law)的关键钥匙。

自动驾驶领域的研究者普遍希望复现 Data Scaling Law 在 LLM 上的成功:通过扩大模型参数和数据规模,实现自动驾驶性能的飞跃。
但 DriveVLA-W0 指出,VLA 模型面临着与 LLM 截然不同的困境:“监督赤字”(Supervision Deficit)。
一个数十亿参数的 VLA 模型,其输入是高维、稠密的视觉信息流,但其监督信号却往往是低维、稀疏的驾驶动作(如路径点)。模型的大部分表征能力被浪费,导致其无法充分学习驾驶环境的复杂动态。
研究团队的实验证实了这一点:在稀疏的动作监督下,VLA 模型的性能会随着数据量的增加迅速饱和,Data Scaling Law 的效应在此大打折扣。
如何填补这一 “赤字”?DriveVLA-W0 的答案是:与其依赖稀疏的 “动作”,不如让模型学习稠密的 “世界”。
研究团队创造性地引入了世界模型,将 “预测未来图像” 作为一项稠密的自监督训练任务。
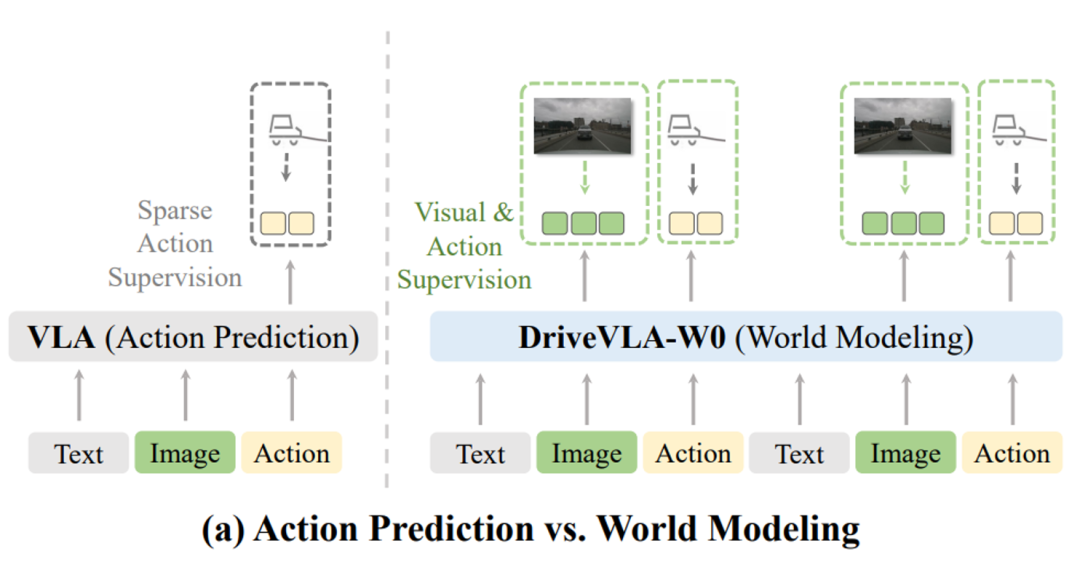
传统 VLA(左)仅依赖稀疏的动作监督。DriveVLA-W0(右)则额外引入了稠密的视觉预测任务,迫使模型理解环境。
当模型被要求去预测下一帧的完整视觉画面时,它必须去学习和理解这个世界的真实运行规律 —— 例如,其他车辆的运动趋势、行人与车辆的交互关系等。
这一设计为 VLA 模型提供了远比 “动作” 更丰富和稠密的学习信号,从根本上缓解了 “监督赤字” 问题。
如果说解决 “监督赤字” 是这项工作的起点,那么其更核心的贡献在于发现了:世界模型能够显著 “放大”(Amplifies)数据规模定律。
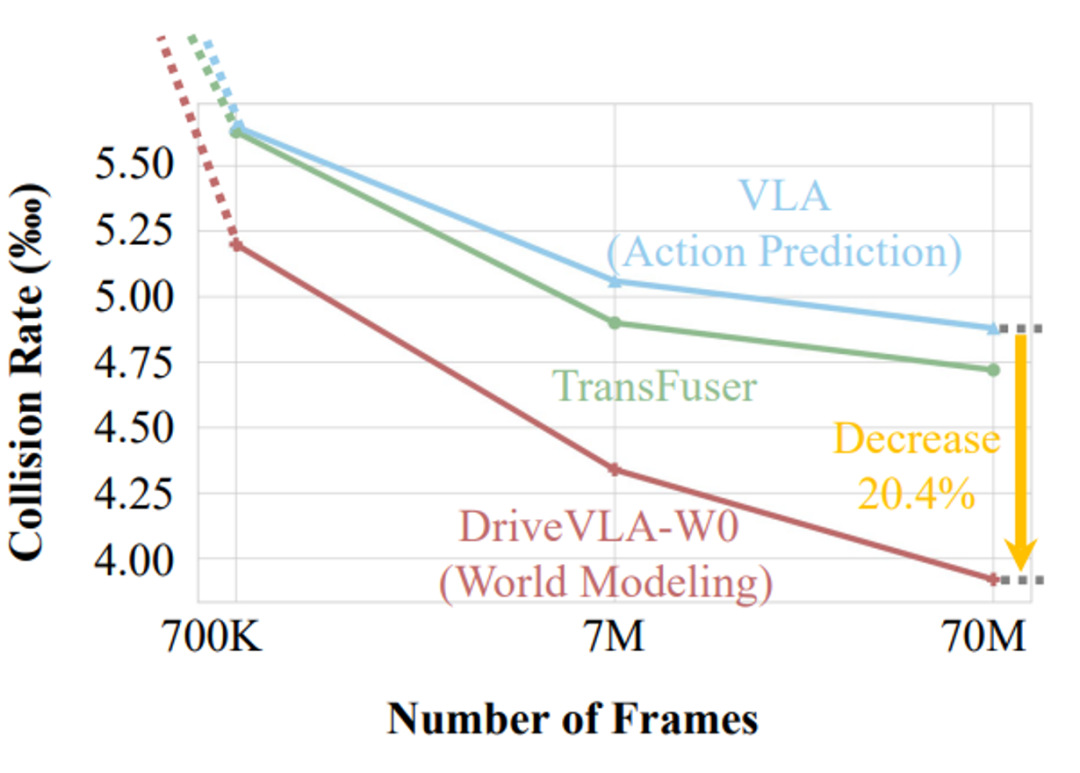
在 700K 到 70M 的数据规模上,DriveVLA-W0(红线)的性能提升斜率显著优于基线(蓝线),展现了更强的扩展潜力。
研究团队在高达 7000 万帧的内部大规模数据集上进行了严格的 Scaling 实验。结果清晰地显示:
基线模型(仅动作监督): 随着数据量增大,性能提升迅速放缓。
DriveVLA-W0(世界模型): 性能随着数据量增加,实现了持续且显著的提升,与基线模型的性能差距越拉越大。
在 70M 帧的规模下,世界模型的加入,使模型的碰撞率降低了 20.4%。这证明了世界模型带来的 “质变”,是单纯堆砌动作数据所无法企及的。
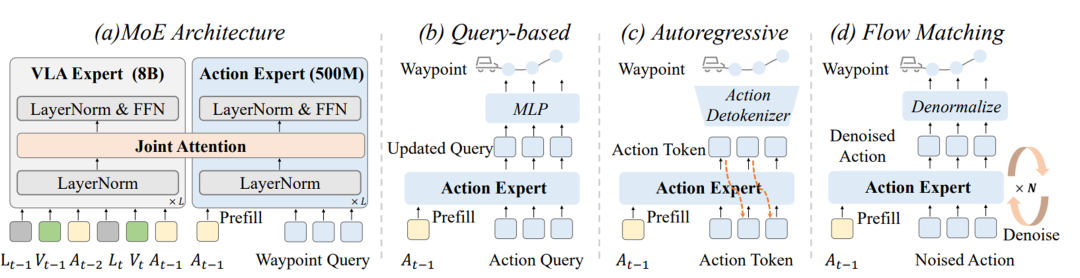
DriveVLA-W0 并非一个不考虑落地的 “学术模型”。针对 VLA 大模型在自动驾驶中面临的 “高延迟” 痛点,团队还提出了一种轻量级的 MoE “动作专家”(Action Expert)架构 。
该设计在不牺牲性能的前提下,显著降低了模型的推理延迟,仅为基线 VLA 的 63.1% ,为 VLA 模型的实时部署提供了可能。
这项研究工作不仅为特斯拉等行业先行者提出的 “真问题” 提供了清晰的解题思路,也为自动驾驶乃至整个具身智能领域,展示了世界模型在 “生成” 之外的另一条核心价值路径 —— 作为强大的自监督引擎,撬动 VLA 模型的 Data Scaling Law。
文章来自于“机器之心”,作者 “机器之心”。


