# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大家好,我是Jomy,是智跃Zleap的CEO,也是Zleap产品和技术的主要设计者。此前在报道中,我曾粗略介绍过Zleap产品背后的技术:一个能帮助CEO自动整理、总结海量企业内部信息的智能Agent。今天,我要正式为大家介绍驱动这个Agent的底层技术:SAG。
这个产品发布后获得了不少关注。但最近,在与多位朋友、客户和投资人交流的过程中,我有了新的认知:SAG的潜力远不止服务于管理者的Agent一体机,它可以成为企业、个人乃至整个Agent领域的底层技术支撑,推动AI行业向前迈进一小步。
所以我今天就和大家详细讲解一下,SAG背后的技术原理和应用方向。
SAG的全称是SQL-Retrieval Augmented Generation,即检索部分主要由SQL驱动。
传统RAG是向量驱动的:将问题转化为向量,在原文的向量空间中模糊匹配语义,找到相似度较高的分块,最后传给LLM回答。这个方案高效,但缺点明显——过于依赖原文相似度,无法进行深度检索。
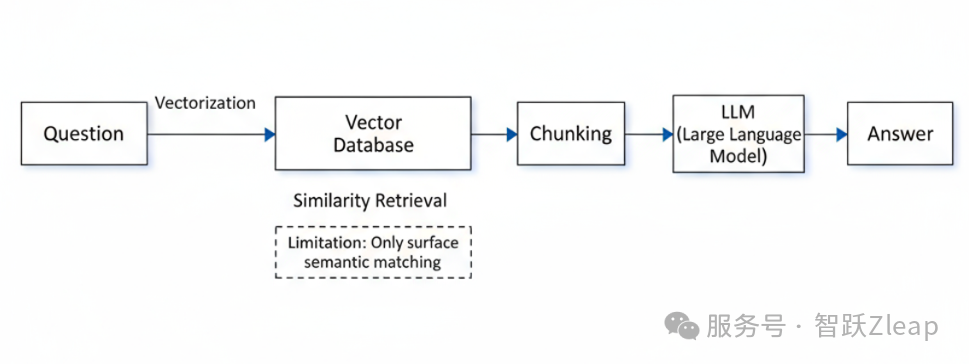
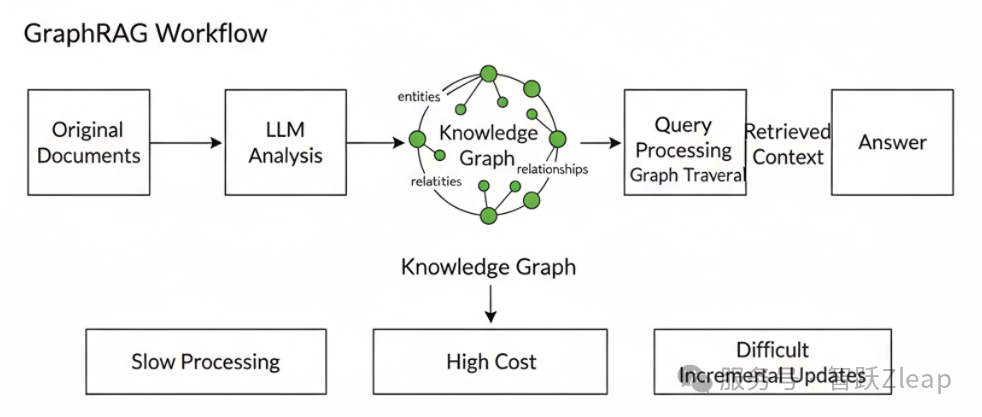
后来出现了GraphRAG,基于知识图谱的检索。其原理是先用LLM分析原文,生成实体和关系,再进行检索。本质上是让LLM对原文进行深度分析和提取,创造了一个中间层,通过知识图谱将问题和答案关联起来。这个方法效果不错,但缺点也很明显:速度慢、成本高,且增量数据需要重新生成图谱。
我们的SAG在传统RAG和GraphRAG的基础上更进一步。它结合了SQL的精准检索和向量的模糊匹配能力,在检索过程中实时构建数据关系,打破了RAG领域的"不可能三角"——同时实现快、准、全。
SAG的一个重要环节是最初的数据处理。与GraphRAG类似,SAG也会创建一个中间层,我称之为"事件"。其核心是将繁杂的信息提炼为一个个原子化的事件,类似人脑将一个复杂的事拆解成多个简单的事。但与GraphRAG不同的是,SAG不会在数据处理时就生成事件之间的关联,而是在查询时实时计算事件关系,从而解决了增量数据更新的问题。
那么如何将不同事件关联起来,正是SAG的核心所在。背后的奥秘是:在数据处理阶段,SAG不仅只是提取事件,还会为每个事件提取多维度的属性,我称之为"自然语言向量"。
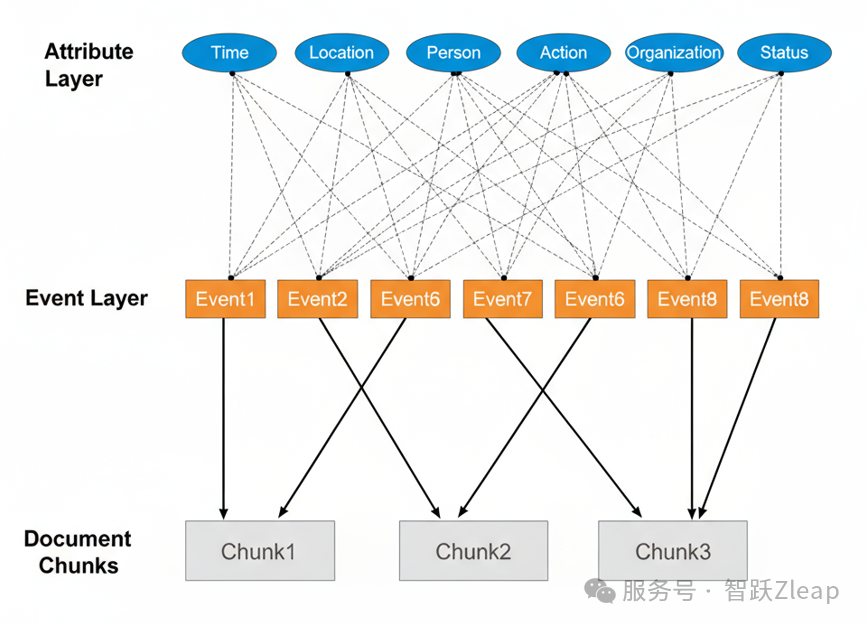
类似于向量用不同的数字在不同维度表达语义,自然语言向量则用不同的属性作为维度,属性的值对应维度的值。不同的事件,维度是相同的,例如时间、地点、行为、人物等。这个过程本质是让LLM把事件中的关键Token进行了结构化+泛化处理。总之,每个事件都可以用一个自然语言向量来表达其大部分语义。

提取事件和属性这件事只需要很小的模型就能完成,大大降低了算力的成本。而且在SAG中,维度是可以自己定义的,不同的行业根据自己数据类型的不同,可以增加一些专有的维度。
那么为什么自然语言向量可以在查询时实时构建不同事件的关系?这个灵感我是来自社会工程学中的"六度分隔理论"。
六度分隔理论简单来说就是:你和任何陌生人之间相隔不超过六个人。比如A认识B,B认识C,A和C可能没有任何交集,但因为A和B有交集,B和C有交集,A就和C产生了联系。

类比到SAG中,人就像事件,交集就像相同的属性。所以理论上,任何事件之间都可以通过中间事件的共同属性产生联系。
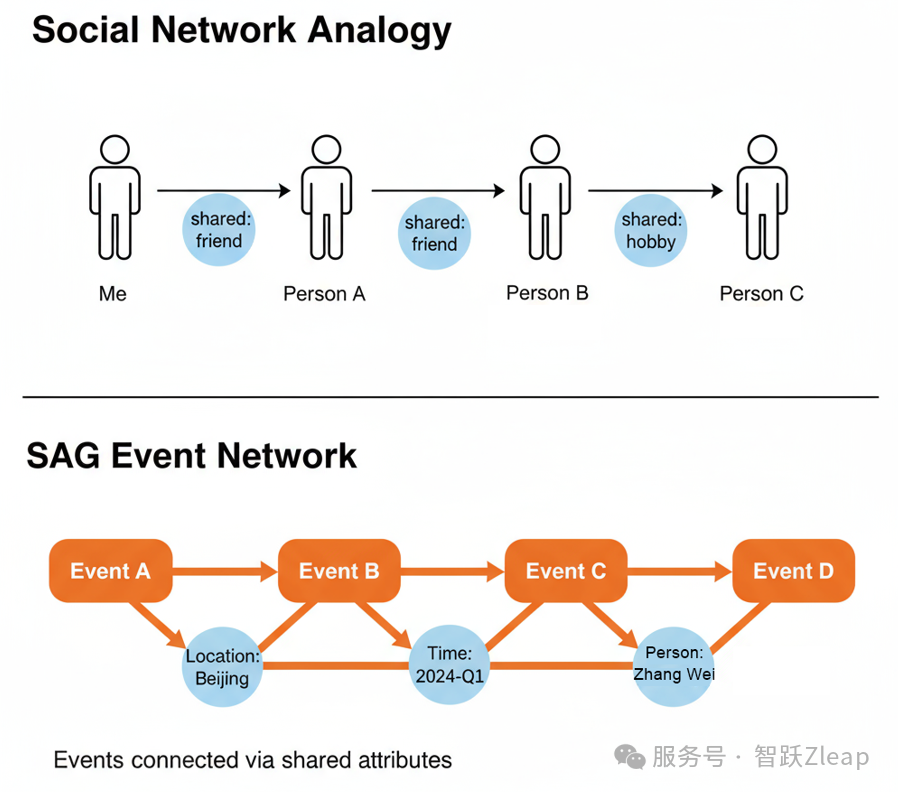
而事件和属性在数据处理时就已提取完成,查询时只需在SQL中检索,无需LLM参与,因此实时构建数据关系的计算是极其快速的。
大家都知道,SQL是精准匹配,如何应对用户千奇百怪的提问呢?比如当你检索"苹果公司"时,是无法通过SQL关联到"Apple Inc"。为了解决这个问题,我就利用了向量的语义匹配能力。
SAG会将所有属性同时存入向量数据库和SQL数据库。当你搜索"苹果公司"时,向量可以语义匹配到"Apple Inc",甚至可以匹配到“iPhone”。此时再拿着"苹果公司"、"Apple Inc"和“iPhone”去SQL中查询,就不会有遗漏了。
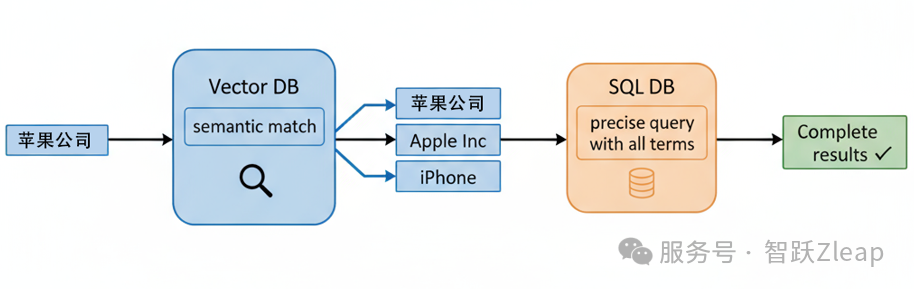
传统基于向量的检索非常擅长进行语义的模糊匹配,但又有很大的不确定性。SAG恰恰利用这一点,结合了向量和SQL的优势——以SQL为主,驯化了向量的不确定性,做到了鱼和熊掌兼得。
当驯化了不确定性,SQL的优势就凸显出来了。例如我们可以针对某几个属性精准和完整的检索,甚至可以直接对某个属性的事件进行统计。由于SAG的SQL表结构相当简单,LLM的Text-to-SQL能力完全能够胜任。
SAG让每一次检索都更精准,这也带来了显著的累积效应。以往大家觉得RAG的多跳效果一般,本质上是因为"Garbage In, Garbage Out"——首次检索质量不高,再多轮也起不了太大作用。而SAG显著提升了每一次原子检索的质量,为LLM提供了更多关联事件,多轮推理的效果也会有质的飞跃。
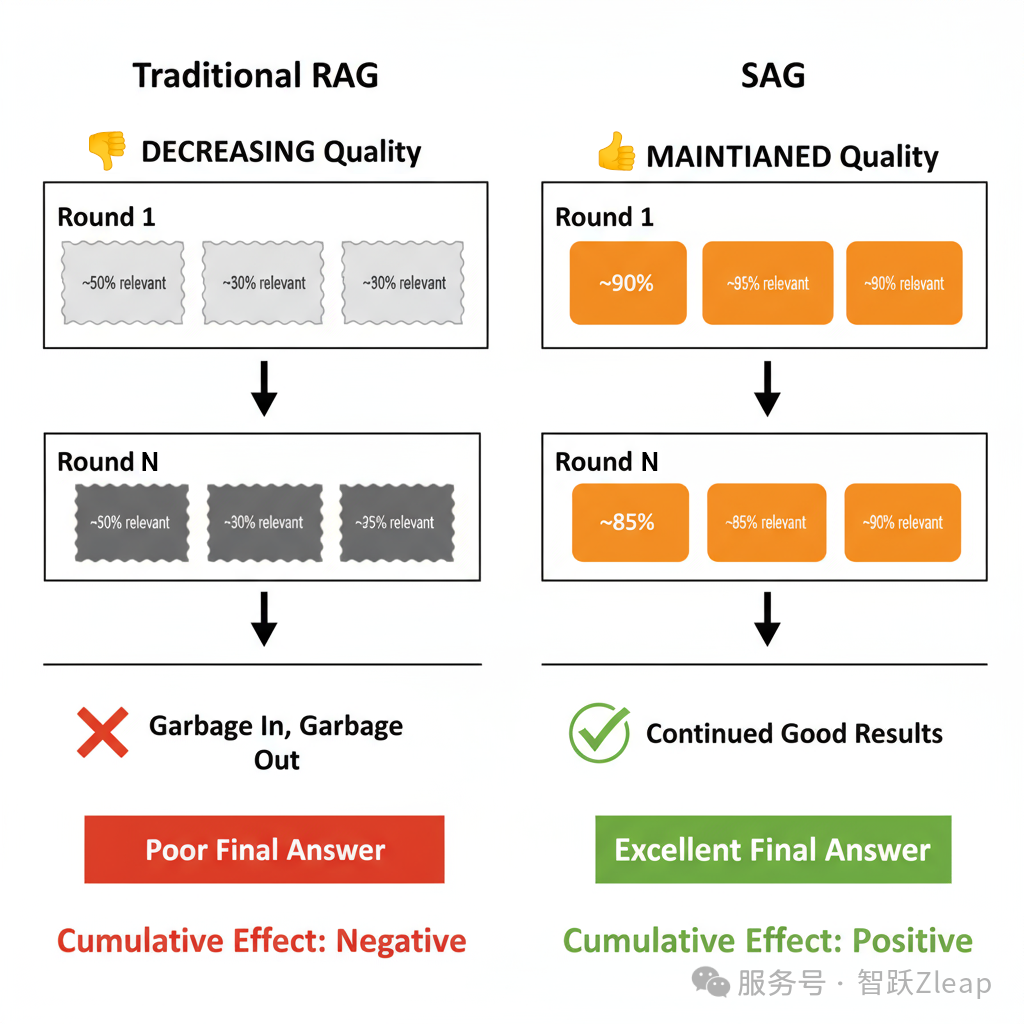
SAG的本质是利用AI将非结构化数据转化为结构化数据,这在企业场景中蕴含着巨大的应用潜力。
首先,作为企业智能决策助手。
就像我们的首款产品Zleap-D1 Agent一体机,SAG能够唤醒企业沉睡的历史数据,实时连接最新业务数据,通过报告、搜索、问答等应用形态,为管理者提供决策辅助和全新的商业洞察。

其次,作为通用数据处理引擎。
SAG可以作为独立的数据处理器,重构企业现有的所有数据。无论是电商推荐、金融风控,还是广告投放,都能从中获益——用更智能的数据显著提升原有算法的效果。
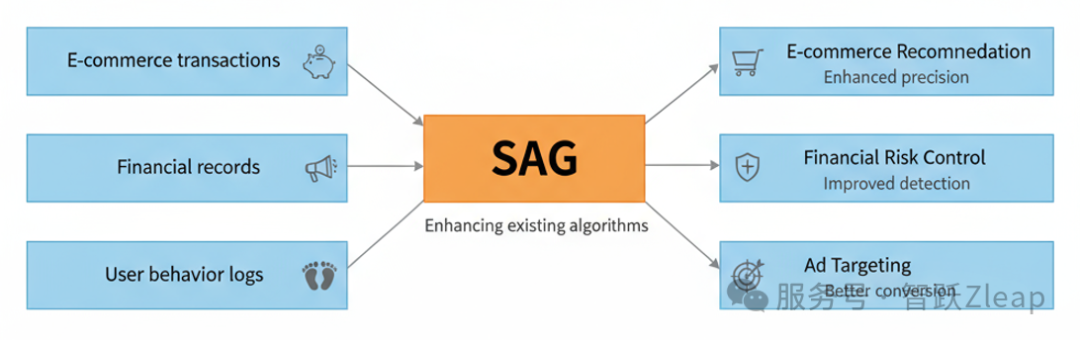
最后,作为低成本的AI转型方案。
SAG能够帮助传统企业跨越信息化阶段,直接迈入AI化时代。SAG通过AI将繁杂的非结构化信息转化为统一的数据格式,为更深层的应用场景奠定了坚实的数据基础,有望加速整个toB应用生态的发展。而且SAG的数据处理是异步进行的,不仅可以使用小模型,还可以利用起夜间的闲置算力,让企业以更低的门槛处理海量历史数据,真正迈入AI时代。
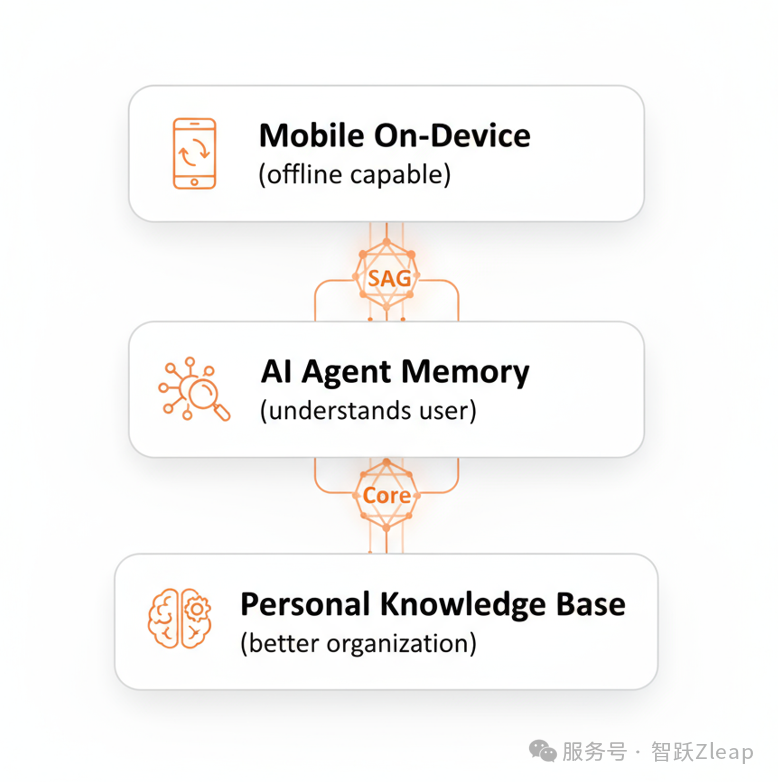
SAG在个人应用方向同样前景广阔。
首先,作为个人知识库的底座。SAG可以让你的笔记、文档、收藏真正变成可检索、可关联的知识体系,而不只是一堆躺在文件夹里的信息。
其次,作为个人AI的记忆中枢。让AI更好的记住你的偏好、习惯、历史对话,真正成为懂你的智能助手。
更重要的是,SAG足够轻量。由于对算力需求极低,经过精简的系统甚至可以完全离线运行在手机上,效果依然出色——你的数据永远在你自己手里。
对于Agent来说,上下文工程已经成为Agent开发的核心共识,但现有的上下文检索往往过于粗暴。比如Claude Code的grep搜索,只能做正则匹配,缺乏深层次的结构化理解。
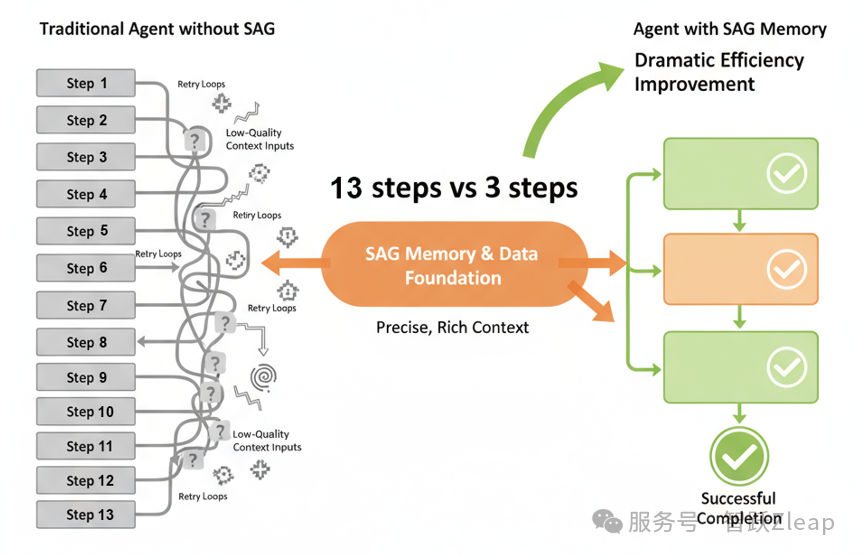
而SAG可以成为未来Agent的记忆与数据基座,快速为Agent提供更精准、更优质的上下文。就像前面提到的累积效应——在更好的上下文加持下,原本需要10步才能完成的任务,可能3步就能搞定,大幅提升Agent的运行效率和成功率。
总的来说,SAG是新一代的RAG技术,融合SQL与向量的优势,实现了快速、准确、全面的AI检索,为企业、个人和Agent领域提供了更强大的数据基座。
为了可以让所有企业都可以使用到SAG技术,也希望为行业发展贡献一份力量,我们决定将这个技术开源:
https://github.com/Zleap-AI/SAG
本次由于篇幅问题,其实有的非常多的细节并没有讲,比如事件和属性通过具体什么算法进行动态关联,又比如多轮召回时的动态剪枝策略等等,关于更具体的算法和原理,请查看我们的开源代码。也欢迎有兴趣的企业和高校与我们合作探索。
我们认为,SAG的价值远不止于替代RAG——它更大的意义在于,能以极高效率将各种信息转化为统一的多维知识图谱。
设想这样一个未来:SAG通过一个简洁优雅的数据格式,打通所有信息源,让数据不再是孤岛,而是可以互相连接甚至交易的资产。
而这些海量的结构化数据,又可以被AI充分检索和利用,推动整个社会生产效率的跃升。这就是我们智跃Zleap的愿景:
让所有信息产生连接,让所有数据成为资产。
为了大家更方便地体验这个技术的能力,我们也为普通用户做了一个产品,可以将公共信息和私人信息聚合在一起,定时生成报告,或进行问答和搜索。
由于产品仍处于Beta阶段,我们实施了邀请码机制。
邀请码将通过智跃公众号定期发布,感谢您的关注。
Web:https://app.zleap.com.cn
APP:iOS App Store搜索Zleap
(文中所有图片均由AI生成,如有错漏请多包涵)
文章来自于微信公众号 “智跃Zleap”,作者 “智跃Zleap”


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
