# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Claude 近期发布的 Skills 功能很火,不少开发者都在尝试、试用。
简单来说,Claude Skills 就像是为 AI 设计的标准化「技能包」,能够把完成复杂任务的指令打包成像「操作手册」一样的简单文件夹。
相比于 MCP,Skills 更进一步,让 LLM 长出「手脚」,能够更高效地外部知识和工具。
不过,本文作者「言午」(前 Manus 研究员)认为,Skills 背后的信息分层设计哲学,才是真正为所有 Agent 开发者带来的、可以被广泛借鉴的关键突破。
「言午」以《塞尔达传说》等 3D 游戏为例,在游戏开发过程中,通常采用细节分层 (LOD, Level of Detail) 、按需加载 (On-demand Loading) 的方式。那 AI Agent 开发也能采用「信息分层」的信息调用方式,像人一样,先看索引,再看摘要,最后有需要才去查原文。
这种信息分层设计,让 Agent 在处理复杂任务时,能够节省高达 95% 的 Token,同时提升决策质量和响应速度。
Claude Skills 的发布,无疑是 2025 年 AI Agent 领域的一颗重磅炸弹。尽管 Anthropic 的有些主张颇受指责,但你可以永远相信这个团队在 LLM 以及 Agent 领域的思考和实践,在模型之外的引领是远超于 OpenAI。Claude Skills 则是他们在 MCP 之后推出的又一个新范式。
那么,什么是 Claude Skills? 简单来说,它是一种 Agent 能力扩展机制,通过将指令、脚本和资源组织成文件夹(即一个 Skill 目录),让 Agent 能够动态发现和加载这些专业知识,从而将通用 Agent 转化为特定任务的专家。每个 Skill 的核心是一个 SKILL.md 文件,其中包含 YAML frontmatter 定义的元数据(如名称、描述),Agent 在启动时会预加载这些元数据作为第一层信息。当 Agent 判断某个 Skill 相关时,会按需加载完整的 SKILL.md 内容作为第二层信息。例如:
---
name: PDF
description: Manipulate PDF documents, fill forms
---
# 以下是PDF Skill的详细指令和使用说明(核心内容,约2000 tokens)
## 功能
- 填写PDF表单
- 提取PDF文本
...
对于更复杂的场景,Skill 目录内还可以包含其他引用文件,作为第三层(或更多层)的详细信息,供 Agent 按需查阅。这种渐进式的信息披露是其高效的关键。
很多人都在讨论 Claude Skills用自然语言定义复杂工作流的强大能力,惊叹于它将 Markdown 作为「技能 SDK」的简洁优雅,以及巧妙利用文件系统和 grep 等 CLI 工具的返璞归真。这些设计确实令人振奋,它们共同提升了 Agent 的构建效率和可扩展性。
然而,在这些显性优势之下,潜藏着一个更深刻、更普适,却被大多数人所忽略的核心设计哲学。我们认为,这才是 Claude Skills 真正为所有 Agent 开发者带来的、可以被广泛借鉴的关键突破。
这个核心思想就是——信息分层设计哲学。正是它,让 Claude Skills 在 Token 效率上实现了惊人的飞跃,不仅节省了高达 95% 的 Token,更显著提升了 Agent 的决策质量和响应速度。
这个『信息分层』的概念听上去颇有些学术,但它的核心思想,你几乎每天都在电子游戏中体验。从早期的《反恐精英(CS)》,到如今的《塞尔达传说》,几乎所有 3D 游戏都离不开这项核心技术。

《塞尔达传说》那广袤而无缝的世界之所以能在 Switch 几乎可以说是孱弱的硬件上流畅运行,其秘诀就藏在两大设计智慧之中:细节分层 (LOD) 与 按需加载。它们共同构成了我们所要探讨的核心——一种普适的「信息分层设计哲学」。
LOD (Level of Detail),即「细节层次」,是 3D 游戏渲染中的一项核心技术。它的基本思想是:一个物体离你越远,展示的细节就应该越少。
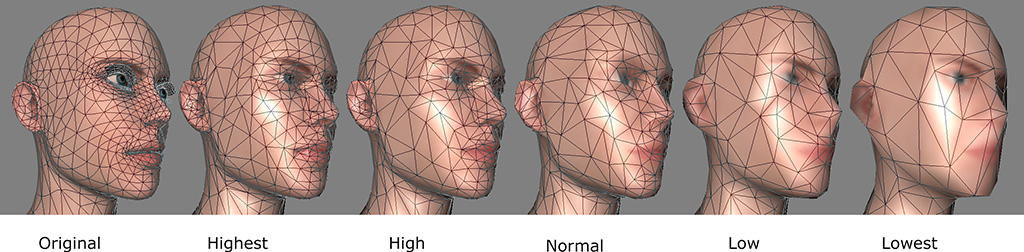
想象一下,你正从高处眺望并逐渐接近一个怪物营地:
•极远处:你首先注意到的,可能只是地平线上一个冒着烟的、模糊的岩石轮廓。游戏此时只为你渲染了一个低多边形模型(Low-Poly Model),它仅由少量几何面构成,只为勾勒出物体的基本轮廓,因此几乎不消耗计算资源,却提供了最关键的元信息:「那里有一个值得探索的地点」。
这就像 Agent 启动时,只看到每个 Skill 的名称和一句话描述,知道「它在哪儿」。
• 中距离:当你飞近一些,现在无需任何特殊工具,就能看清营地的木制哨塔、篝火、敌人的大致数量和类型,甚至能分辨出显眼的红色爆炸桶。这些核心信息足以让你制定一个完整的战术计划。
这恰好对应 Agent 读取一个 Skill 的核心文档,足以支撑它制定出完整的行动计划。
• 近距离:当你潜行到营地边缘,现在能看清每个敌人手中武器的具体样式、篝火上烤肉的纹理、以及它们盔甲上的划痕。游戏为你加载了最高精度的模型,以支持你最精准的操作。
这便是 Agent 在需要精准执行时,按需查阅的、最详尽的原始信息。
LOD 技术通过「在需要时才提供必要信息」,极大地节省了硬件资源,使得在有限的机能上呈现广阔无垠的世界成为可能。
LOD 决定了「加载什么精度」的信息,而按需加载(On-demand Loading)则解决了「在哪个时刻」加载这些信息的问题。
最好的例子,莫过于进入一座古代神庙:
• 门外:当你站在神庙外,游戏为你渲染了精美的外部结构,但神庙内部复杂的谜题和机关,对系统来说是完全「不存在」的。引擎没有为这个你「可能不会进入」的地方浪费一丝一毫的内存。
• 进入:在你与大门互动,确认「进入」的那一刻,游戏执行了一次「按需加载」。屏幕上出现短暂的过渡动画,在此期间,引擎将神庙内部全新的、完整的场景数据调入内存,同时「卸载」掉暂时看不见的外部世界数据。
这个「进入」的动作,就如同 Agent 在决策后,发出指令去加载某个 Skill 的完整细节,实现了上下文的精准控制。
按需加载避免了一次性将整个世界(包括所有神庙的内部)都塞进内存,从而实现了高效的资源管理和无缝的场景切换。
《塞尔达传说》的流畅体验,正是建立在这两大智慧之上:LOD 负责管理信息的精度,按需加载负责管理信息的时机。
这种「在需要时才提供必要信息」的设计哲学,不仅是游戏优化的关键,也正是我们在构建高效 AI Agent 时所要遵循的核心原则。它告诉我们,一个优秀的 Agent 系统,不应该在启动时就背负所有知识的重量,而应该学会如何快速浏览摘要,按需加载细节,从而在广阔的「问题世界」中,实现轻盈而精准的探索。
游戏世界的直观体验,为我们揭示了一套强大的设计哲学。现在,让我们将其正式化,提炼出一个所有 Agent 开发者都能直接应用的经典模型——信息分层三层架构。这套架构由信息层级和访问工具共同组成,两者深度耦合,缺一不可。
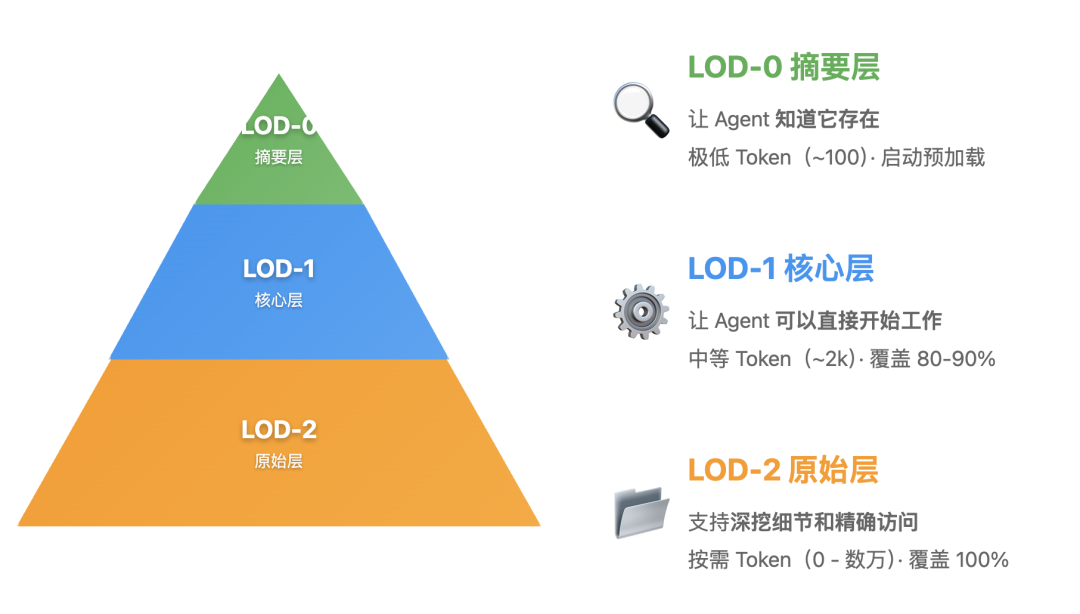
• 目的:让 Agent 知道它存在。这是全局的索引,用于快速浏览和判断相关性。
• 对应《塞尔达》:这就是远方神庙的发光轮廓,或怪物营地的一缕青烟。
• 内容:最精简的元信息,如名称、一句话描述、核心特征。
• 示例:
Skill: pdf.fillForm - 填写 PDF 表单字段
数据: 2025_Q1_sales.xlsx - 一季度销售数据,10k 行
• 加载时机:总是在 Agent 启动时预加载,构建全局认知。
• Token 消耗:极低(每个约 20-50 tokens)。
• 目的:让 Agent 可以直接开始工作。
• 对应《塞尔达》:这就是神庙的完整外部结构,或怪物营地的哨塔与敌人布局。
• 内容:足以完成 80-90% 常规任务的核心信息,如完整的函数签名、参数说明、使用示例、数据表的统计摘要和样本。
• 示例:
Skill: 完整的 SKILL.md,包含所有参数、返回值和常用示例。
数据: 表结构 + 统计摘要(总额、均值、分布)+ 前 5 行样本。
• 加载时机:当 Agent 根据 LOD-0 判断某个资源相关时,按需加载。
• Token 消耗:中等(约 1-3k tokens)。
• 目的:支持深挖细节和精确访问,处理剩余 10-20% 的复杂或特殊场景。
• 对应《塞尔达》:这就是神庙内部的完整谜题,或敌人手中武器的精确纹理。
• 内容:完整的、未经删减的原始信息。
• 示例:
Skills: SKILL.md 中引用的扩展文档(如 forms.md, examples/)。
数据: 完整的 10,000 行原始数据,通过 SQL 或脚本按需查询。
• 加载时机:当 Agent 发现 LOD-1 的信息不足以解决问题时,按需加载或查询。
• Token 消耗:按需(可能为 0,也可能数万 tokens)。
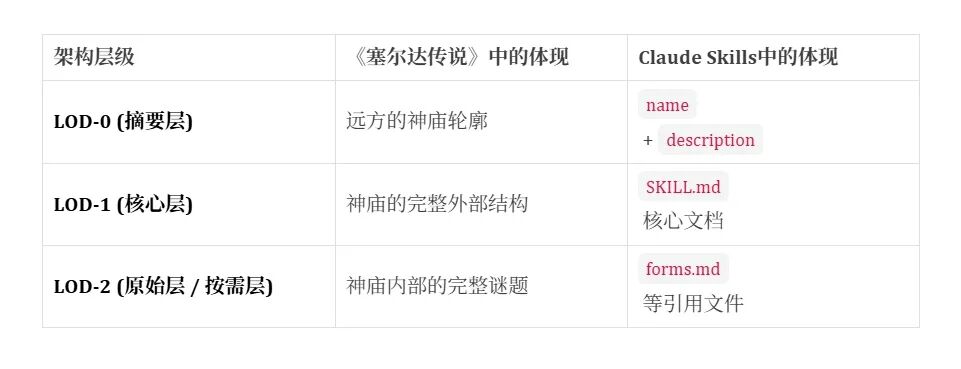
Agent收到任务
↓
1. 扫描所有资源的【LOD-0】,快速了解全局能力
↓
2. 识别出3-5个可能相关的资源
↓
3. 按需加载这些资源的【LOD-1】,制定核心计划
↓
4. 在LOD-1层面完成大部分任务(80-90%)
↓
5. 仅在需要时,通过工具从【LOD-2】按需获取精确数据(10-20%)
三层架构如此强大,是否意味着所有信息都需要被分为三层?并非如此。实际上,绝大多数我们日常接触的信息体,都是天然的「两层系统」。
• 两层系统:由 「元信息」(LOD-0)和「完整内容」(LOD-1) 构成。
LOD-0:文件名、文章标题、函数名。
LOD-1:文件内容、文章正文、函数实现。
• 适用场景:适用于那些 「小到可以一次性读完」 的信息体,通常是小于 5k Token 的单个文件、短文档或代码片段。对于这些信息,Agent 可以直接加载完整内容进行处理,无需一个额外的「核心摘要层」。
三层系统,是专门为解决「大到无法一次性读完」的复杂信息体而设计的。
• 判断标准:当一个信息体(如大型数据表、代码仓库、API 集合)大到必须通过过滤、查询或聚合才能有效使用时,三层架构就变得至关重要。它通过引入一个高质量的 LOD-1「核心摘要层」,避免了 Agent 在面对海量原始数据时「溺水」。
理解这一点,可以帮助我们避免过度设计,在合适的场景选择合适的架构。
值得注意的是,这套三层架构并非孤立存在,它的高效运作离不开与之深度耦合的工具系统。工具是 Agent 访问和利用不同信息层级的唯一途径。
•LOD-0 -> LOD-1 的工具:通常是简单的文件读取或元数据查询工具。例如,Agent 通过 cat SKILL.md 的指令来加载核心文档。
• LOD-1 -> LOD-2 的工具:这是体现架构优势的关键,通常是具备过滤和查询能力的工具。例如,Agent 通过 SQL 查询从数据库中精确获取所需数据,或通过 grep 从代码文件中定位特定函数实现。
核心原则:信息的组织方式,必须为查询工具服务。

这也解释了为什么 Claude Skills 的 SKILL.md 设计得如此巧妙:它不仅是一个 Markdown 文档,更是一个为 grep 等 CLI 工具优化过的、行协议式的信息结构。因此,在设计你自己的信息分层系统时,必须将信息如何组织与Agent 如何访问作为一个整体来系统性地思考。
理论终须实践。让我们通过一个 Agent 在实际工作中面临的场景——分析公司季度业绩——来亲身体验信息分层架构的巨大威力。
想象一下,你的 Agent 被部署在一个大型企业的数据环境中。这里有销售数据、客户数据、产品库存、市场活动记录等等,信息量庞大且分散。
Agent 首先接触到的,是公司数据资产的极简目录。这就像图书馆的卡片索引,只提供最基础的「书名」和「主题」,让你知道有哪些书,但不会告诉你书里具体写了什么。
数据资产目录:
- sales_2025_Q1.xlsx: 2025年一季度销售数据
- customer_profiles.db: 客户画像数据库
- product_inventory.csv: 产品库存清单
- marketing_campaigns.json: 市场活动记录
Agent 接到任务:「请分析公司一季度的销售业绩。」通过这个 LOD-0 概览,它能迅速判断出 sales_2025_Q1.xlsx 这个文件是最相关的。
Agent 在 LOD-0 层面识别出 sales_2025_Q1.xlsx 后,并不会直接加载这个文件全部的原始数据(假设它有 10,000 行)。相反,它会按需加载一份预先生成的高质量摘要——LOD-1 信息:
{
"file":"2025_Q1_sales.xlsx",
"size":"10,000行 × 15列",
"date_range":"2025-01-01 至 2025-03-31",
"summary":{
"总销售额":"¥5,234万",
"同比增长":"+15%",
"订单数":10000,
"平均订单额":"¥5,234"
},
"key_insights":{
"Top 5客户占比":"60%",
"最佳销售月":"3月(¥2,100万)"
},
"region_breakdown":{
"华东":"¥2,200万 (42%)",
"华南":"¥1,500万 (29%)",
"其他":"¥1,534万 (29%)"
},
"sample_orders":[
["2025-01-05","客户A","华东","¥12,500"],
["2025-01-05","客户B","华南","¥8,300"]
]
}
构建成本与价值:这份高质量的 LOD-1 摘要并非凭空而来。它需要我们预先编写分析脚本(用 Pandas 或 SQL)来从原始数据中提炼。这就像游戏开发时,美术师需要投入精力去制作低多边形模型一样。这是一种典型的「计算换 Token」策略:我们用一次性的、廉价的计算资源,换取了后续每一次 Agent 调用时昂贵的 Token 消耗和推理时间节省。
有了这份摘要,Agent 可以轻松回答 80-90% 的常规问题,例如:「一季度业绩如何?」、「哪个区域表现最好?」。
现在,我们提出一个更深入的任务:「分析华东区高价值客户的复购行为」。
这个任务,LOD-1 的摘要信息已经无法满足。此时,Agent 需要深入 LOD-2 的原始数据。但它不会加载全部 10,000 行,而是通过工具进行按需查询:
SELECT customer, order_date, amount
FROM sales
WHERE region = '华东' AND amount > 10000
ORDER BY customer, order_date;
这个查询可能只会返回几百行相关数据,而不是全部。Agent 只在需要时,才精确地获取它完成任务所需的最少信息。
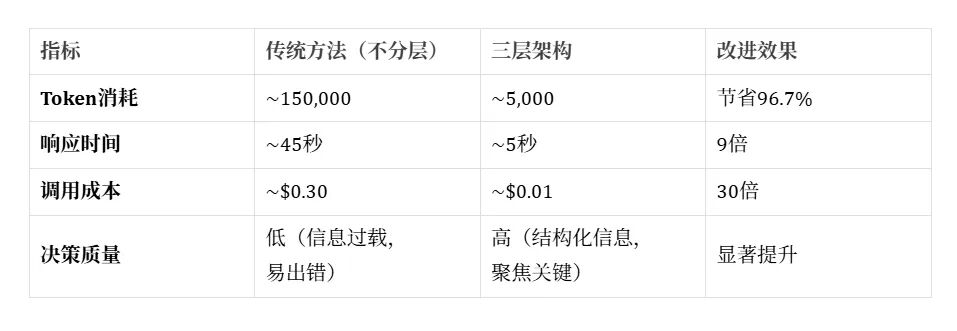
正如数据所示,信息分层架构不仅极大地降低了成本,更重要的是,它通过提供结构化、高密度的信息,帮助 Agent 摆脱了「数据海洋」,能够更快速、更准确地进行分析和决策。
信息分层架构如此强大,是否意味着它是一颗「银弹」?答案是否定的。正如海拉鲁的宏大世界并非一日建成,这套架构的高效同样来自于对复杂性的精心管理和巨大的前期投入。在实践中,我们需要像游戏开发者一样,清醒地认识并权衡其「代价」。
游戏中最核心的低多边形模型(LOD-1),并非由高精度模型(LOD-2)自动、完美地生成。它需要专业的 3D 美术师投入大量时间和精力,手动进行「拓扑优化」,以最少的面数还原出模型的关键特征。
同样,我们的 LOD-1 摘要层也需要 「工程师」的汗水。无论是需要领域专家去精心撰写一份「开箱即用」的 SKILL.md,还是需要数据工程师开发复杂的脚本来生成一份高质量的统计摘要,这都构成了高昂的初始构建成本。
游戏开发者最头疼的问题之一,就是在更新游戏内容后,忘记更新相关的低模版本,导致玩家在远处看到的是旧的山脉,飞近了才「突然」变成新的。
这就是信息分层的维护成本。如果 LOD-2 的原始信息发生了变化(例如,底层代码更新、数据库结构变更),而 LOD-1 和 LOD-0 没有及时同步,就会产生「信息漂移」。Agent 拿着过时的「地图」(SKILL.md 或数据摘要),去探索一个全新的世界,必然会导致错误和失败。这需要我们建立自动化的更新机制或严格的同步规范来应对。
设计一个线性的、一本道的游戏关卡相对简单,但设计一个像海拉鲁这样,既能让玩家自由探索,又能通过不同层次的引导给予方向的开放世界,其设计复杂度是指数级增长的。
信息分层架构本质上也是用更高的设计复杂度,来换取更低的运行时成本。 它要求设计者从一个系统性的、全局的视角出发,具备很强的抽象能力,来界定每一层信息的边界和内容,并系统性地思考信息组织与查询工具的深度耦合。对于简单、不常访问的信息,强行分层反而会得不偿失,导致「为了分层而分层」的过度设计。
因此,决定是否采用信息分层架构,需要我们像一个真正的游戏制作人那样去思考:评估信息的规模、变化频率和访问模式,权衡「开发成本」与「玩家体验」(Token 效率),最终做出明智的决策。
现在,我们已经深入剖析了信息分层架构的原理、实践与挑战。是时候将这些洞察提炼为更普适的通用原则,并思考它们在更广阔的 Agent 设计领域中的应用。
这是信息分层架构的核心思想之一。它告诉我们,在 Agent 的决策初期,绝大多数情况下,Agent 并不需要完整的、原始的信息。相反,一个精心设计的元信息(Metadata)或摘要信息,就能提供足够的上下文来做出初步判断和规划。
• 数据分析:Agent 无需加载整个数据库,只需查看表头、字段类型、统计摘要(均值、方差、分布)和少量样本数据,就能理解数据结构和内容。
• API文档:Agent 无需阅读所有 API 的详细实现,只需查看 API 列表、每个Endpoint 的简要功能描述和核心参数,就能判断哪个 API 是当前任务所需的。
• 代码仓库:Agent 无需阅读所有代码文件,只需通过目录树、文件命名约定和关键文件的注释,就能快速定位到相关模块。
第二个核心原则是关于信息的加载时机。它强调,只有当 Agent 明确需要某个特定信息来推进任务时,才去加载它。这避免了不必要的Token消耗和信息过载。
• 数据:Agent 不会一次性加载所有数据,而是通过 SQL 查询、数据过滤等工具,只获取与当前分析任务相关的子集。
• 文档:Agent 不会一次性加载所有文档,而是根据任务需求,精确地读取某个文档的特定章节或段落。
• 代码:Agent 不会一次性加载所有代码文件,而是通过代码搜索工具(如grep),按需定位到特定函数或类的实现细节。
这两个原则结合起来,最经典的体现就是文件系统,这也是 Anthropic 选择它作为Skills核心基础设施的重要原因。
文件系统本身就是一个天然的嵌套二层系统。一个文件名(LOD-0)和一个文件内容(LOD-1)构成了最基础的信息单元。一个好的文件名,如user_authentication_service.py,本身就是最好的 LOD-0,它清晰地告诉Agent这个文件的核心职责。
然而,当面临大量技能(例如 20 个 Skills)时,一个纯粹的二层系统会让 Agent 陷入「冷启动困境」:
方案 A(盲目):Agent 启动时只看到 20 个文件名(pdf.md, excel.md...),但文件名本身过于抽象,Agent 无法知道每个技能的具体能力,难以做出有效决策。
方案 B(沉重):Agent 启动时加载所有 20 个 SKILL.md 的完整内容,但这会消耗巨量的启动 Token(例如 20 * 2k = 40k tokens),而任务可能只需要其中一两个技能。
Anthropic 的巧思在于,他们利用 Markdown 已有的YAML frontmatter特性,零成本地在文件系统的二层结构之上,构建了一个轻量级的 LOD-0 全局索引。
---
name: PDF
description: Manipulate PDF documents, fill forms
---
# [2000 tokens的详细LOD-1内容...]
通过在启动时只提取所有技能的 name 和 description,Agent 可以用极低的成本(20 * 20 = 400 tokens)构建一个完整的全局能力视图,完美地解决了信息发现(Discovery)的难题。这就像为一座只有书架的图书馆,配备了一套完整的「卡片目录系统」,让找书的效率发生了质的飞跃。
当我们第一次看到 Claude Skills 的设计时,很多人的第一反应确实是:「这不就是 Markdown 文件和懒加载吗?有什么特别的?」这种直观的看法抓住了技术实现的一部分表象,非常合理。
但它的真正威力在于,Anthropic 将这些看似简单的技术,系统化、范式化成了一套高效的信息架构哲学。就像乐高积木本身很简单,但用它来构建复杂的城堡就是一种系统工程。Skills 的创新不在于发明了新的「积木」,而在于提供了一套优雅的「城堡图纸」,将这些基础组件以最高效的方式组织起来,从而在 Agent 领域实现了革命性的 Token 效率和决策质量提升。
最后,一个更深层次的洞察是,这套三层架构并非是扁平的,而是可以递归嵌套的,形成一种分形结构。
• 向下看(展开):一个 LOD-2 的原始信息体,其内部可能又是一个完整的三层系统。
• 向上看(收起):一个完整的三层系统,对更高层的观察者来说,可以被抽象成一个简单的 LOD-0 元素。
想象一下 Agent 在探索一个庞大的公司数据系统:
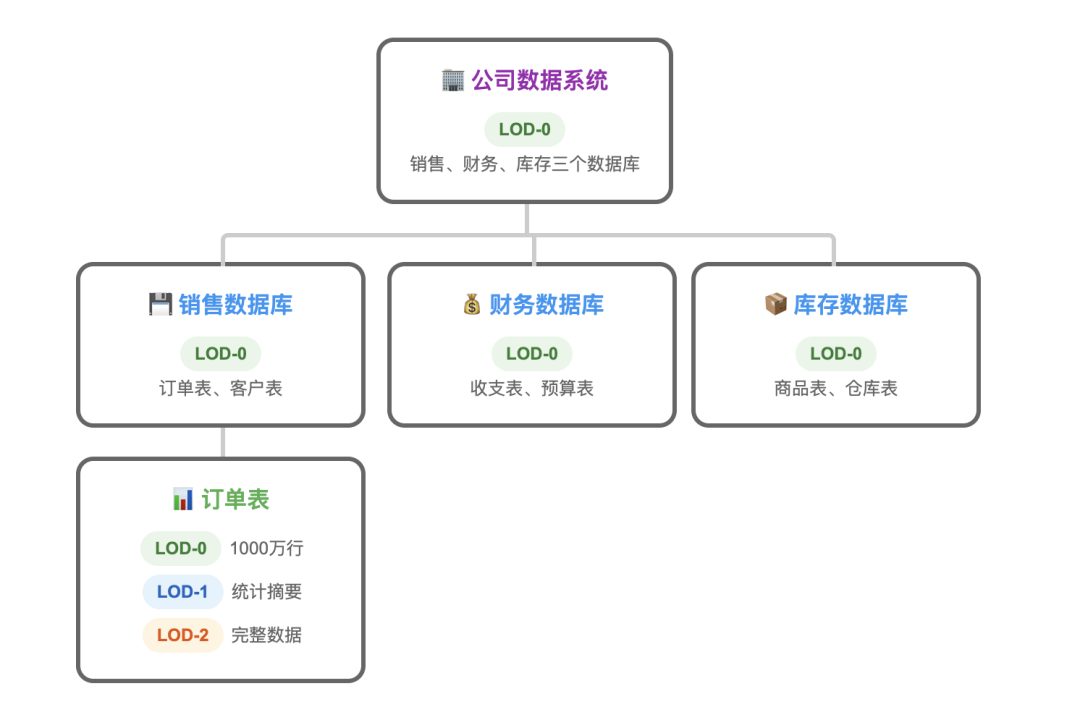
【公司级】
├─ LOD-0: "公司有销售、财务、库存三个数据库"
└─ LOD-2: 访问【销售数据库】
│
└─【数据库级】
├─ LOD-0: "销售库有订单表、客户表"
└─ LOD-2: 访问【订单表】
│
└─【表级】
├─ LOD-0: "订单表 - 1000万行"
├─ LOD-1: 统计摘要 + Schema
└─ LOD-2: 完整的1000万行数据
Agent 就像一个在信息世界中不断「推门而入」的探索者,每一扇门(LOD-2)背后,都可能是一个全新的、同样遵循三层架构的「房间」。这种分形特性,使得这套看似简单的架构,能够优雅地扩展到管理任意复杂度的信息系统。
Claude Skills 为我们揭示了构建高效 AI Agent 的两个核心智慧:
1. 用元信息替代完整信息:像游戏渲染中的 LOD,根据「距离」提供不同精度的信息。
2. 按需加载而非预加载:像游戏中的场景切换,只在需要时才加载必要的信息。
这两个原则,源自游戏开发的智慧,却普适于所有信息密集型系统。遵循信息分层设计哲学,你将能构建出更高效、更经济、更智能的 Agent。
文章来自于“Founder Park”,作者 “yan5xu”。


【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】OpenManus 目前支持在你的电脑上完成很多任务,包括网页浏览,文件操作,写代码等。OpenManus 使用了传统的 ReAct 的模式,这样的优势是基于当前的状态进行决策,上下文和记忆方便管理,无需单独处理。需要注意,Manus 有使用 Plan 进行规划。
项目地址:https://github.com/mannaandpoem/OpenManus
【开源免费】smart-excel-ai是一个输入你想要的Excel公式的描述,即可帮你生成对应公式的AI项目
项目地址:https://github.com/weijunext/smart-excel-ai
在线使用:https://www.smartexcel.cc/(付费)
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
