# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

继轻量级强化学习(RL)框架 slime 在社区中悄然流行并支持了包括 GLM-4.6 在内的大量 Post-training 流水线与 MoE 训练任务之后,LMSYS 团队正式推出 Miles——一个专为企业级大规模 MoE 训练及生产环境工作负载设计的强化学习框架。
Miles 从 slime 分叉(fork)而来,在继承其轻量级与高可定制性基因的基础上,针对新一代硬件(如 GB300)与大规模 MoE 进行了深度优化。它引入了 Infrastructure-level 的 True On-Policy(严格在线策略)、投机训练(Speculative Training)以及更极致的显存管理机制,旨在为追求高可靠性与大规模部署的团队提供流畅且可控的 RL 训练体验。
千里之行,始于足下。Miles 的发布标志着 LMSYS 团队在构建生产级 AI 基础设施道路上迈出的关键一步。
Miles 的起点源于 slime——一个在开源社区与 LMSYS 内部备受推崇的轻量级框架。slime 因其优雅的设计原则,已成为众多模型科学家探索算法的首选工具。Miles 完整继承了这些核心优势:
Miles 的诞生,正是基于 LMSYS 和 SGLang 社区的真实反馈,是将开放协作转化为工程实践的典范。
在保留 slime 灵活性的同时,LMSYS 团队在 Miles 中注入了针对企业级应用和新一代硬件(GB300)的“强心剂”。以下是 Miles 近期实施的关键技术升级:
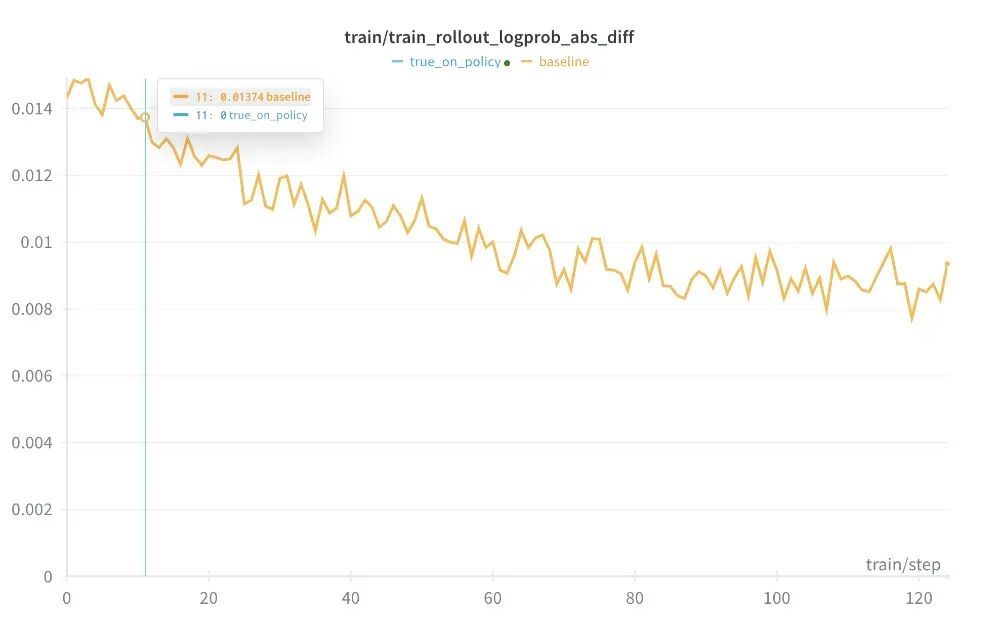
为了追求极致的算法正确性,Miles 除了支持现有的确定性(Deterministic)采样外,还进一步通过 kernel 层面的优化实现了True On-Policy,训练与推理之间的 mismatch 被精确地降至零。
具体实现上,团队利用了 Flash Attention 3、DeepGEMM以及来自 Thinking Machines Lab 的 Batch invariant kernels,并结合 torch compile 技术。此外,团队还对训练和推理过程中的数值运算细节进行了严格对齐,确保了结果的位级一致性(bit-wise consistence)。
为了在不触发 OOM(显存溢出)的前提下最大限度地榨取 GPU 性能,Miles 进行了一系列显存管理升级:
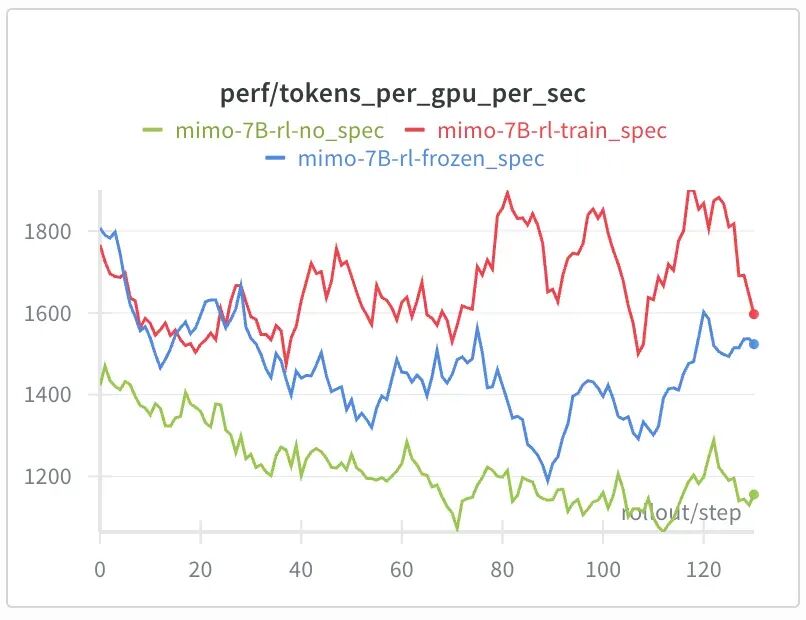
在强化学习场景中,如果 Draft Model(草稿模型)保持冻结,它将无法跟随 Target Model(目标模型)的策略变化,导致接受长度(Accept Length)下降,从而削弱加速效果。
为此,Miles 创新性地在 RL 过程中对 Draft Model 进行在线 SFT(Online SFT)。
LMSYS 团队表示,Miles 的发布仅仅是一个开始。为了进一步支持企业级 RL 训练,未来的开发路线图包括:
Miles 的存在离不开 slime 作者群及广泛的 SGLang/RL 社区的贡献。LMSYS 团队诚邀研究人员、初创公司及企业团队试用 Miles,共同打造高效、可靠的强化学习生产环境。
原文链接:https://lmsys.org/blog/2025-11-19-miles/
文章来自于“Z Potentials”,作者 “LMSYS Org”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
