# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

AI模型大战 - Gemini 3 Pro对阵GPT-5.1-Codex-Max对阵Claude Sonnet 4.5 (图片来源:本图片由 OpenAI 的 DALL·E 生成)
💡 2025年11月,前沿AI竞赛进入白热化。48小时内,谷歌发布Gemini 3 Pro宣称跑分第一,OpenAI立即反击推出GPT-5.1-Codex-Max,这是一款能连续工作24小时以上的专业编码模型。
前沿AI竞赛在2025年11月达到高潮。48小时内,谷歌推出Gemini 3 Pro宣称在主要推理基准测试中领先,而OpenAI立即用GPT-5.1-Codex-Max反击,这是一款专门训练用于通过创新"压缩"(compaction)技术自主工作超过24小时的专业编码模型[43]。加上Claude Sonnet 4.5已确立的编码统治地位和激进的安全过滤器,开发者面临前所未有的选择:三种真正不同的AI辅助开发方法,每种都有独特优势和令人沮丧的局限。
对专业人士来说,最重要的问题不是要不要用AI,而是该用哪个模型、何时切换、如何绕过它们的限制。即使采用率飙升超过80%,对AI准确性的信任却跌至令人担忧的低点。营销承诺与生产现实之间的鸿沟从未如此之大。
OpenAI的GPT-5.1-Codex-Max于11月19日发布,仅比Gemini 3 Pro晚一天,代表了向专业化模型而非通用系统的战略转变[43]。标题能力是"压缩"(compaction),这是一种允许模型跨越多个上下文窗口运行的技术,当接近上下文限制时自动总结并保留关键状态[43]。
实际影响相当可观。OpenAI内部评估显示,Codex-Max在单个任务上独立工作超过24小时,迭代修复测试失败并完善实现,无需人工干预[43]。这解决了困扰所有前沿模型的"上下文腐烂"问题。Codex-Max不是随着上下文填满而失去连贯性,而是用压缩的进度摘要重置。

Codex-Max压缩技术原理图 (图片来源:本图片由 OpenAI 的 DALL·E 生成)
在SWE-bench Verified上,Codex-Max在超高推理努力下达到77.9%的准确率,略微领先Gemini 3 Pro的76.2%[45]。更令人印象深刻的是,它在达到这一性能时使用的思考token比前任GPT-5.1-Codex少30%,直接转化为大量用户更低的API成本[46]。速度提升同样可测量,编码任务执行速度比之前的模型快27%到42%[46]。
陷阱在于:Codex-Max仍然是专业化的。OpenAI明确警告,它应该"仅用于Codex或类Codex环境中的代理编码任务",而不是作为通用模型[42]。这种专业化反映了更广泛的行业趋势:万能模型的时代似乎正在结束,被在狭窄领域表现出色的特定任务变体所取代。
压缩背后的架构仍然有些不透明。与简单地增加上下文窗口大小不同,压缩涉及模型在工作时主动决定保留哪些信息、丢弃哪些信息[43]。这需要对长期任务进行训练,模型学习什么对任务完成很重要,什么可以安全遗忘的模式。这种方法是否比基于RAG的检索或大规模静态窗口更可靠,将在很大程度上决定下一代AI开发工具的走向。
Claude Sonnet 4.5是目前最强大的编码模型,在真实软件工程任务上达到业界顶尖水平,幻觉率也是竞品中最低的[1]。但它同时也是限制最多的模型,实施了宪法式AI(Constitutional AI),将伦理原则硬编码进系统,即使"用户似乎有正当理由"也会主动拒绝请求[2]。

Claude宪法式AI架构图 (图片来源:本图片由 OpenAI 的 DALL·E 生成)
实际影响最严重的是专业人士。Claude不会提供个性化医疗诊断或具体法律建议,总是用大量免责声明把用户引向持证专业人士。GPT-5.1和Gemini虽然也有类似政策语言,但它们会提供详细信息加上免责声明,而不是直接拒绝[3]。这个差异很关键:Claude的做法保护了责任风险,却给讨论饮食失调的医学教育者、编写奇幻暴力场景的游戏开发者、分析漏洞的网络安全研究员制造了麻烦。
CBRN(化学、生物、放射、核威胁)过滤器问题比大多数人想象的更深。Claude Sonnet 4.5在ASL-3(AI安全级别3)保护下运行,配备专门的分类器来阻止CBRN威胁信息[4]。实际上,这些基于关键词的触发器会拦截合法的科学研究。有记录的案例显示:Claude Research拒绝回答关于有毒蘑菇的问题,以违反使用政策为由阻止了一位药理学研究员[5]。模型无法区分恶意意图和学术探究。
测试显示,非专家用户仍然可以在超过四分之一的情况下触发不安全的CBRN响应,专家用户的成功率接近一半[6]。这表明Claude的激进过滤制造了误报,却没有完全解决底层安全挑战。对于从事生物安全、制药研究或防御性网络安全的专业人士来说,这些限制严重限制了实用性。
Anthropic的做法反映了一个深思熟虑的哲学选择:宪法式AI用明确的伦理原则训练模型,这些原则来自联合国人权宣言、苹果服务条款以及非西方文化视角[7]。这创造了可预测、一致的行为,Claude会反复拒绝同一请求,但对合法的边缘案例毫无灵活性。企业用户可以协商调整政策,但消费者和API用户面对的是全部限制。
OpenAI今年的方向完全相反,系统性地放宽了限制。GPT-5.1的11月12日发布带来了自适应推理,根据任务复杂度动态调整思考时间[6][7]。模型现在允许公众人物图像,允许在教育场景中使用仇恨符号,并将从12月开始让经过验证的成年用户访问成人内容[9]。
对专业使用来说,GPT基于政策的方法创造了实际优势。虽然使用条款禁止医疗或法律工作的"需要执照的定制建议",但测试显示ChatGPT继续提供大量指导加上责任免责声明[10]。律师报告经常用它做文档分析和合同起草,接受自己验证输出的责任,而不是被完全阻止。
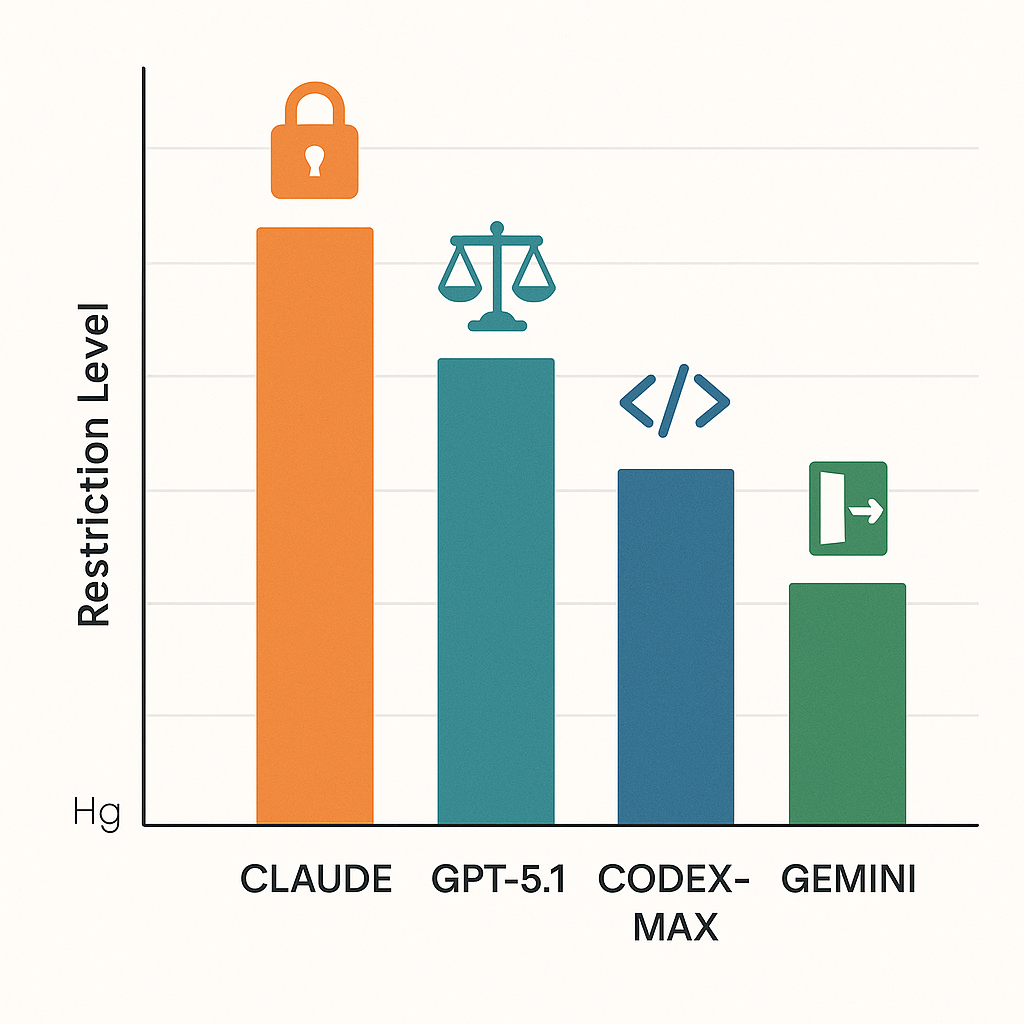
AI模型限制程度对比 (图片来源:本图片由 OpenAI 的 DALL·E 生成)
缺点是:当存在干扰因素时,GPT模型的幻觉率更高,生成自信但错误的响应而不是放弃[11]。最近研究显示,即使是专门的法律AI系统,幻觉错误信息的比例也在六分之一到三分之一之间[12]。ChatGPT愿意提供答案,创造了与Claude谨慎不同的风险特征。
GPT-5.1 Pro于11月19日与Codex-Max同时发布,取代了仅在三个月前发布的GPT-5 Pro,日落期仅90天[42]。对于刚发布三个月的模型来说,这是一个非常快的弃用周期。这种快速迭代反映了OpenAI的策略:持续增量改进,而不是等待重大架构突破。
集成仍然是GPT最强的优势。GitHub Copilot同时添加了Claude Sonnet 4.5和GPT-5.1-Codex-Max,承认了竞争的存在,但GPT变体仍然是数百万开发者环境的默认选择[44]。生态系统很重要:原生VS Code集成、广泛的IDE支持、最大的开发者社区创造了单靠技术能力无法克服的网络效应。
谷歌的Gemini 3 Pro在GPT-5.1发布仅两天后推出,声称在通用推理基准上领先,并提供100万token的最大广告上下文窗口[14]。实际情况更微妙。虽然Gemini在快速原型设计上表现出色,成本只是竞品的零头(大约是Claude Sonnet 4.5价格的二十分之一),但它生成的代码需要更多调试,缺乏Claude的结构组织[15]。
上下文窗口军备竞赛制造了更多困惑而非清晰。Gemini在某些配置中宣传高达200万token,但研究揭示了广告容量与可用容量之间的巨大差距。声称大规模窗口的模型通常在大约60%到70%的广告容量时就变得不可靠[16]。"迷失在中间"效应在所有模型中持续存在,埋在长上下文中间深度的信息,其检索效果远不如开头或结尾的内容[17]。

广告宣传vs实际上下文窗口性能 (图片来源:本图片由 OpenAI 的 DALL·E 生成)
真实测试证明了这个问题:开发者尝试在Gemini驱动的工具中附加10到15个Python文件作为上下文时,遇到"上下文窗口限制"警告,尽管远低于广告最大值[18]。当上下文确实工作时,处理时间变得令人望而却步。一项研究发现,当上下文超过某些阈值时,响应延迟从不到2秒跃升至近60秒,表明模型进入了成本显著更高的处理模式[19]。
Gemini在5月的安全过滤器故障是平衡保护与实用性挑战的典型例子。一个关键失败阻止用户即使为合法专业应用也无法禁用内容过滤器。帮助性侵幸存者的支持工作者发现事件报告被阻止为"不安全内容"或"非法色情内容",迫使幸存者在录入会话中看到错误消息[20]。这不是恶意设计,而是实施失败,揭示了安全系统如何可能阻止它们应该服务的用户。
模型的优势在于多模态能力和Google Workspace集成。Gemini可以从截图和模型生成代码,分析视频和音频,并与Docs、Sheets和Slides原生协作。对于已经嵌入谷歌生态系统的团队来说,这种无缝连接证明了克服Gemini不太精致的编码输出是值得的。"新UI之王"的称号反映了前端和视觉设计工作的真正优势[21]。
百万token上下文窗口代表的是营销多于实际能力。虽然三个模型都声称支持大幅扩展的上下文,但来自多个来源的研究揭示了被称为"上下文腐烂"的系统性能退化:即使在简单任务上,模型也表现出随着输入长度增加而可靠性下降[22]。
复杂工作的有效上下文远低于广告值。GPT-4 Turbo声称的容量显示检索性能在远未达到最大长度时就降至大约一半有效性[23]。Gemini的大规模窗口,当测试语义理解而不是字面文本匹配时,有效上下文以千而非百万token为单位[24]。Claude的实现似乎更保守但在其声明限制内更可靠。
这对这些窗口实现的主要用例至关重要:分析整个代码库。Claude Sonnet 4.5报告的能够处理超过75,000行代码的能力代表真正的能力,但有注意事项。复杂软件工程任务的准确性随着上下文增长而急剧下降,从中等上下文的大约30%到最大规模的大约3%[25]。模型可以"看到"整个代码库,但难以在其中保持连贯推理。

上下文腐烂效应 - 代码库规模与准确率下降 (图片来源:本图片由 OpenAI 的 DALL·E 生成)
成本考虑在规模上复合。处理数十万token需要几分钟的预填充时间才能开始生成,使得交互使用不切实际[26]。定价层反映了这一点:Anthropic对超过标准窗口的提示收取更高费用,而企业用户报告当上下文优化失败时,月成本从数千欧元激增至数万欧元[27]。基础设施要求严苛,百万token上下文仅为键值缓存就需要大量GPU内存,迫使系统跨GPU、CPU内存和NVMe驱动器使用分层存储[28]。
架构现实表明,尽管上下文窗口扩大,RAG(检索增强生成)仍然有价值。仔细选择相关信息优于将所有内容倒入上下文,无论是质量还是成本。研究共识:保持一致性能的较小窗口模型通常比遭受上下文腐烂的大规模窗口更有用[29]。
Codex-Max的压缩方法代表了与简单扩展上下文窗口根本不同的策略。模型不是在内存中维护每个token,而是主动修剪其历史记录,同时保留任务完成所需的关键信息[43]。这用完美回忆换取了更长时间尺度上的持续连贯性。
架构影响是重大的。传统上下文窗口遇到"内存墙",维护数十亿键值对在计算上变得难以承受[46]。处理数十万token需要几分钟的预填充时间才能开始生成,使得交互使用不切实际[26]。成本在规模上爆炸,企业用户报告当上下文优化失败时,月账单从数千欧元跃升至数万欧元[27]。
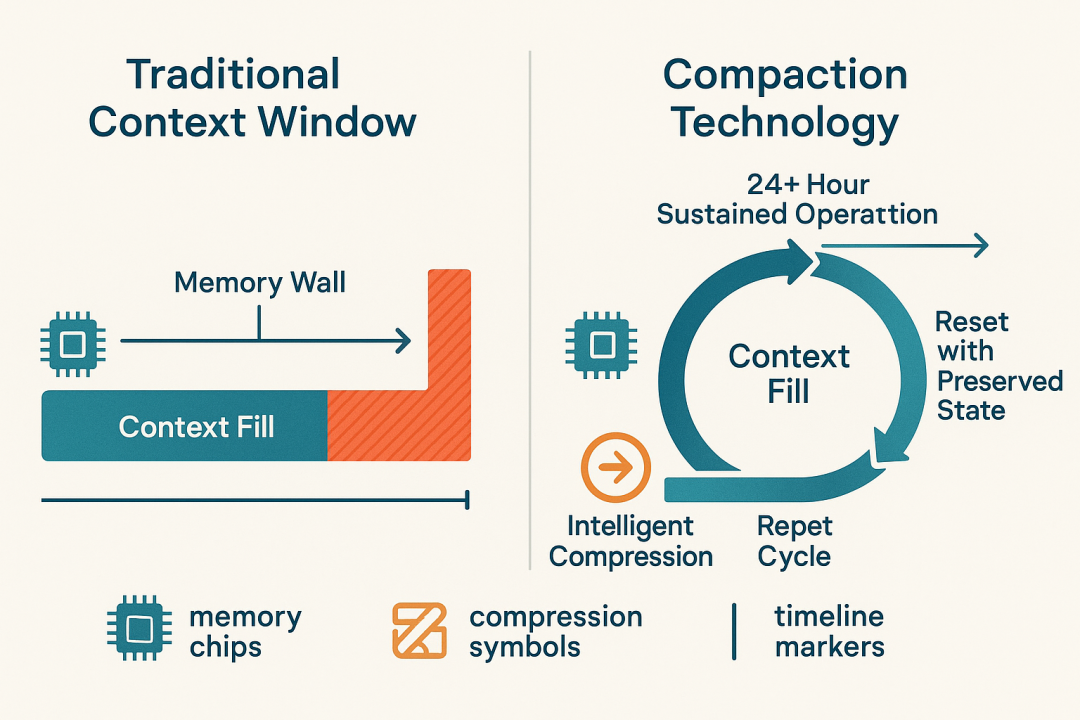
压缩技术vs传统上下文窗口 (图片来源:本图片由 OpenAI 的 DALL·E 生成)
压缩通过定期用智能总结重置上下文来回避这个问题。OpenAI报告Codex-Max在超过24小时的会话中保持连贯工作,远超任何静态上下文窗口能可靠处理的范围[43][47]。权衡:模型的压缩历史可能会丢失对特定边缘案例重要的细节。
压缩是否比RAG(检索增强生成)或大规模静态窗口更可靠仍是一个悬而未决的问题。RAG系统从向量数据库中仔细选择相关信息,以额外基础设施的成本保持精度。静态窗口承诺完整性,但受到注意力稀释和计算限制的困扰。压缩试图获得两者的优势:最初使用完整上下文工作,然后在会话延长时智能压缩。
对软件开发来说,这些模型之间存在有意义的差异。Claude Sonnet 4.5主导生产代码生成,通过在真实GitHub问题上的卓越性能赢得地位[30]。开发者描述它是第一个"无需告知就考虑提高代码质量"的模型,像高级工程师一样在没有明确提示的情况下考虑架构、测试和文档[31]。
GPT-5.1-Codex-Max针对不同用例:需要持续关注数小时或数天的长期、项目规模重构[43]。模型通过测试失败自主工作并迭代改进实现的能力解决了"懒惰代理"问题,即模型随着对话长度增加而退化[46]。对于复杂迁移、大规模重构或需要协调的多文件更改,Codex-Max的耐力可能超过Claude每次交互的卓越代码质量。
Gemini 3 Pro在光谱的另一端表现出色:快速原型设计和实验工作[33]。它的速度优势很大,开发者报告在几秒而不是几分钟内重写大量token[32]。模型"碾压氛围编码",直觉地填充骨架指导中的空白。对于MVP、副项目和初步探索,Gemini的成本效益和迭代速度超过了不太有组织的输出。
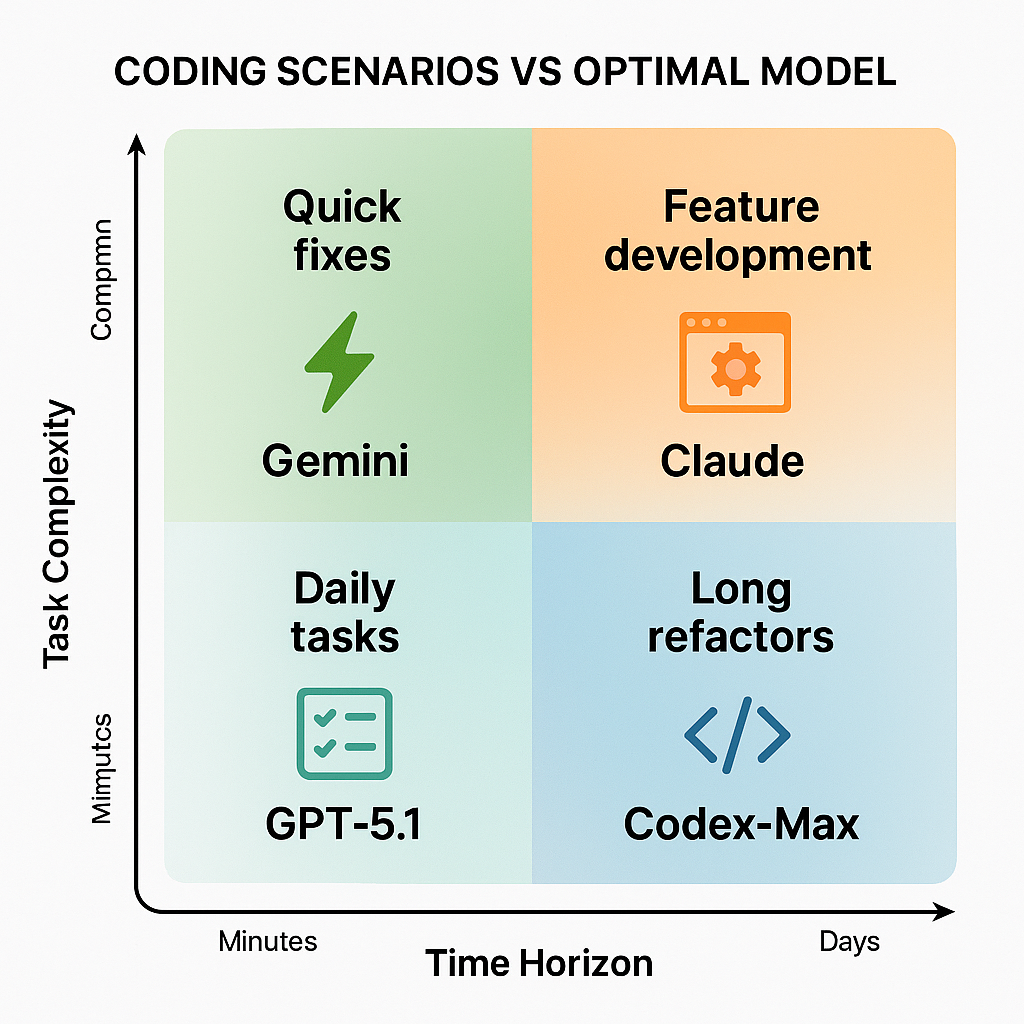
编码场景与最佳模型选择矩阵 (图片来源:本图片由 OpenAI 的 DALL·E 生成)
有争议的发现值得认真考虑:在熟悉代码库上工作的经验丰富的开发者使用AI工具可能实际上更慢[34]。显示近20%减速的研究与广泛认知相矛盾。"几乎正确"问题,即代码工作但有微妙问题,比从头开始创造更多调试工作。
成本优化策略:对于中国团队来说,成本控制至关重要。建议采用四层策略:生产代码用Claude确保质量,长期重构用Codex-Max节省人力成本,日常开发和快速迭代用Gemini控制API开支,需要生态集成时选择GPT-5.1。国内可以考虑使用通义千问、文心一言等大模型处理中文场景,成本更低且中文理解更好。特别是对于技术债务清理和大规模代码迁移项目,Codex-Max的24小时持续工作能力可以显著降低人力投入。

中国开发者成本效益分析 (图片来源:本图片由 OpenAI 的 DALL·E 生成)
监管合规考虑:中国的AI应用需要遵守《生成式人工智能服务管理暂行办法》等法规。Claude的宪法式AI虽然限制多,但其可预测的拒绝行为反而有利于合规审计。建议企业用户建立AI使用日志系统,记录模型选择、提示内容和输出结果,以应对可能的监管检查。
团队协作模式:对于多人协作的研发团队,统一模型选择标准很关键。建议建立"模型路由机制":根据任务类型自动推荐使用哪个模型。例如,代码审查用Claude、文档生成用GPT、UI原型用Gemini。这样既能发挥各模型优势,又能降低团队学习成本。
技术债务防范:过度依赖AI生成的代码可能积累技术债务。建议:一是强制代码审查环节,AI生成的代码必须有人工Review;二是建立代码质量基线,AI辅助的代码质量不能低于人工编写标准;三是定期技术债务清理,重构AI生成但设计不佳的代码。
专业用户得出了明确结论:没有单一模型主导所有用例。开发者社区和专业工作流中出现的模式涉及维护对多个模型的访问,并根据任务要求切换[36]。
演进的分配策略:
这种多模型方法创造了开销,学习不同的提示风格、管理订阅、决定哪个工具适合每个任务,但反映了真正的专业化。用户报告平均尝试大约四个不同模型,专业人士同时维护两到三个付费订阅[37]。

四模型协作工作流策略 (图片来源:本图片由 OpenAI 的 DALL·E 生成)
信任悖论使一切复杂化。采用率继续飙升,而对AI准确性的信任度降至令人担忧的低点[38]。用户同时采用和怀疑这些工具,创造了"信任但验证"文化,AI加速人类然后仔细审查的工作。这代表成熟方法:AI作为需要监督的增强,而不是做决策的自主代理。
选择Claude Sonnet 4.5,当代码质量、生产就绪性和低幻觉率证明溢价定价合理时。对需要架构决策的复杂功能以及文档密集型工作流至关重要。接受权衡:激进的安全过滤器偶尔会阻止合法工作。最适合高级开发者和可靠性超过成本的企业团队。
选择GPT-5.1-Codex-Max,用于需要持续关注的长期编码任务:项目规模重构、依赖项迁移或跨越数小时的调试会话。压缩技术使得超出传统上下文限制的工作成为可能。接受它是为代理编码工作流而非通用协助而专门化的。最适合处理技术债务或大规模代码库转换的团队。
选择GPT-5.1(通用),用于需要多模态能力、对话优雅和广泛生态系统集成的多功能日常工作流。在前端开发和一般协助中更优。接受更高的幻觉率需要验证。最适合跨多样化任务的平衡性能。
选择Gemini 3 Pro,用于快速原型设计、大规模成本意识开发以及需要大规模上下文或紧密Google Workspace集成的工作。在UI工作和迭代速度比代码组织更重要的实验项目中表现出色。接受不太精致的结构需要更多调试。最适合初创公司和关注计算成本的学习环境。
框架简化为专业化:Claude求质量,Codex-Max求耐力,GPT求多功能,Gemini求速度。但现实更深,内容政策不同,上下文窗口过度承诺,编码性能因任务类型差异巨大。
证据表明,AI编码工具的生产力增益因开发者经验水平和任务类型而异,远超模型选择的影响。初级开发者看到大幅加速,在不熟悉领域的经验丰富开发者有意义受益,但在熟悉代码库上工作的高级工程师,当诚实测量包括调试的总时间时,可能发现AI让他们变慢[39]。
"70%问题"捕获了这个模式:AI快速让你达到70%,然后最后30%成为收益递减的练习[40]。对于缺乏调试心智模型的用户来说,最后这段尤其令人沮丧。代码最初工作,看起来对,然后在边缘案例测试或集成期间揭示微妙问题。AI生成的信心,使复杂任务感觉可处理,实际上可能减慢那些需要建立基础理解的人的学习。
这不是反对使用这些工具的论点,而是主张现实期望和深思熟虑的技能发展。使用AI加速样板工作、探索不熟悉的框架、生成初稿,但投资于理解它产生的代码。成功使用AI工具的开发者保持工程基础,同时在真正有帮助的地方利用加速。
快速发布节奏,七周内三个前沿模型,将继续。预计上下文窗口继续扩展,即使现有窗口的有效利用仍不完整。预计安全过滤器变得更复杂,同时仍产生误报。预计基准分数改善,而基准与真实性能之间的差距持续存在。
架构比原始能力更重要。GPT-5.1的自动计算分配式自适应推理、Claude的基于原则的安全式宪法AI、Gemini的稀疏注意力式专家混合机制代表了同一挑战的不同方法:构建同时有能力、安全和高效的模型。
AI模型发展路线图至2026年及以后 (图片来源:本图片由 OpenAI 的 DALL·E 生成)
对于专业人士,这意味着保持灵活性。主导你今天工作流的模型可能在几个月内成为二线。在一个平台上阻止工作的限制可能不适用于竞品。现在合理的成本可能随着定价压力加剧而改变。构建可以在不完全重建的情况下切换模型的工作流。发展跨平台转移的提示工程技能。最重要的是,保留无论使用哪个AI助手都仍然必不可少的工程基础和批判性思维。
问题不是哪个模型赢,而是哪种模型组合,用于适当任务并进行适当验证,使你在实际工作中最有效。这个答案因人而异、因任务而异,并且随着能力以加速步伐演变而越来越多地因时间而异。
💡核心建议:不要追求"最佳"模型,而是建立"最佳组合"策略。根据任务特性智能路由模型选择,保持对新能力的关注,但始终验证输出质量。
[1]Anthropic: Claude Sonnet 4.5 announcement (https://www.anthropic.com/news/claude-sonnet-4-5)
[2]Anthropic: Constitutional AI documentation (https://www.anthropic.com/news/claudes-constitution)
[3]Artificial Lawyer: OpenAI policy analysis (https://www.artificiallawyer.com/2025/11/03/openai-stops-giving-legal-advice-but-has-it-really/)
[4]Skywork: Claude Sonnet 4.5 overview (https://skywork.ai/blog/claude-sonnet-4-5-free-chat-online/)
[5]Hacker News: Claude CBRN filter discussion (https://news.ycombinator.com/item?id=44780315)
[6]ActiveFence: CBRN testing report (https://www.activefence.com/blog/your-ai-agent-is-talking/)
[7]Anthropic: Claude's Constitution (https://www.anthropic.com/news/claudes-constitution)
[8]OpenAI: GPT-5.1 release announcement (https://openai.com/index/gpt-5-1/)
[9]TechCrunch: OpenAI image policy changes (https://techcrunch.com/2025/03/28/openai-peels-back-chatgpts-safeguards-around-image-creation/)
[10]Artificial Lawyer: OpenAI legal advice policy (https://www.artificiallawyer.com/2025/11/03/openai-stops-giving-legal-advice-but-has-it-really/)
[11]Chroma Research: Context rot study (https://research.trychroma.com/context-rot)
[12]Stack Overflow: Developer survey results (https://stackoverflow.blog/2025/07/29/developers-remain-willing-but-reluctant-to-use-ai-the-2025-developer-survey-results-are-here/)
[13]OpenAI: GPT-5.1 announcement (https://openai.com/index/gpt-5-1/)
[14]Google: Gemini 3 announcement (https://blog.google/products/gemini/gemini-3/)
[15]Bind AI: Model comparison (https://blog.getbind.co/2025/11/19/gemini-3-0-vs-gpt-5-1-vs-claude-sonnet-4-5-which-one-is-better/)
[16]Chroma Research: Context rot study (https://research.trychroma.com/context-rot)
[17]Snorkel AI: Enterprise benchmarks (https://snorkel.ai/blog/long-context-models-in-the-enterprise-benchmarks-and-beyond/)
[18]GitHub: VSCode Copilot issues (https://github.com/microsoft/vscode-copilot-release/issues/8303)
[19]Demiliani: Performance degradation analysis (https://demiliani.com/2025/11/02/understanding-llm-performance-degradation-a-deep-dive-into-context-window-limits/)
[20]The Register: Gemini safety failure (https://www.theregister.com/2025/05/08/google_gemini_update_prevents_disabling/)
[21]TechRadar: Hands-on coding test (https://www.techradar.com/ai-platforms-assistants/i-tested-gemini-3-chatgpt-5-1-and-claude-sonnet-4-5-and-gemini-crushed-it-in-a-real-coding-task)
[22]Chroma Research: Context rot (https://research.trychroma.com/context-rot)
[23]Saplin: GPT-4 context analysis (https://dev.to/maximsaplin/gpt-4-128k-context-it-is-not-big-enough-1h02)
[24]Convert: Context windows analysis (https://www.convert.com/blog/ai/context-windows-structured-data/)
[25]Anthropic: 1M context announcement (https://www.anthropic.com/news/1m-context)
[26]Micron: Token context infrastructure (https://www.micron.com/about/blog/company/insights/1-million-token-context-the-good-the-bad-and-the-ugly)
[27]Daijobu: AI cost analysis (https://daijobu.ai/2025/05/19/millions-of-tokens-the-invisible-unit-of-measurement-shaping-modern-ai/)
[28]Micron: Infrastructure requirements (https://www.micron.com/about/blog/company/insights/1-million-token-context-the-good-the-bad-and-the-ugly)
[29]Chroma Research: Context rot findings (https://research.trychroma.com/context-rot)
[30]Anthropic: Claude Sonnet 4.5 (https://www.anthropic.com/news/claude-sonnet-4-5)
[31]Bind AI: Coding comparison (https://blog.getbind.co/2025/05/23/claude-4-vs-claude-3-7-sonnet-vs-gemini-2-5-pro-which-is-best-for-coding/)
[32]Index.dev: Gemini vs Claude testing (https://www.index.dev/blog/gemini-vs-claude-for-coding)
[33]OpenAI: GPT-4.1 announcement (https://openai.com/index/gpt-4-1/)
[34]METR: Developer productivity study (https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/)
[35]Medium: GitHub Copilot productivity (https://medium.com/@sahin.samia/can-ai-really-boost-developer-productivity-new-study-reveals-a-26-increase-1f34e70b5341)
[36]Creator Economy: Model comparison guide (https://creatoreconomy.so/p/chatgpt-vs-claude-vs-gemini-the-best-ai-model-for-each-use-case-2025)
[37]Stack Overflow: Developer survey (https://stackoverflow.blog/2025/07/29/developers-remain-willing-but-reluctant-to-use-ai-the-2025-developer-survey-results-are-here/)
[38]Stack Overflow: Developer survey (https://stackoverflow.blog/2025/07/29/developers-remain-willing-but-reluctant-to-use-ai-the-2025-developer-survey-results-are-here/)
[39]METR: Productivity study (https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/)
[40]Addy Osmani: The 70% problem (https://addyo.substack.com/p/the-70-problem-hard-truths-about)
安涛,悟智科技创始人,美国人工智能硕士。带领团队自主研发悟智AI平台,在智慧城市、司法服务、产业合规等领域服务多个省市级政府部门和央企国企。研究方向聚焦自然语言处理和知识图谱,致力于推动AI技术在政企场景真正落地。
文章来自于微信公众号 “悟智派”,作者 “悟智派”


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
