# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在过去五年,AI领域一直被一条“铁律”所支配,Scaling Law(扩展定律)。它如同计算领域的摩尔定律一般,简单、粗暴、却魔力无穷:投入更多的数据、更多的参数、更多的算力,模型的性能就会线性且可预测地增长。无数的团队,无论是开源巨头还是商业实验室,都将希望孤注一掷地押在了这条唯一的救命稻草上。

今天的开发者和研究者们普遍感到一种深刻的焦虑:Scaling Law是否已接近其经济与物理的尽头? 我们正面临计算资源的瓶颈,以及越来越微弱的边际效益。如果我们只期待这条定律能带领我们抵达AGI的彼岸,那么我们可能正在走向一个昂贵且平庸的死胡同。
突破这一魔咒,成为了通往下一代通用智能的关键命题。
MiroMind团队的重磅论文 MiroThinker v1.0,正是对这一命题的一次大胆且成功的回答。它并未选择在参数或上下文的军备竞赛中继续内卷,而是另辟蹊径,提出了一个被长期忽视的、决定智能上限的 “第三维度”交互深度(Interaction Depth)。


MiroThinker证明:智能的进化,需要的不再是更巨大的静态脑容量,而是更高效、更深层的“动觉”和“行动力”。在衡量通用AI助手的黄金标准GAIA基准测试中,MiroThinker的72B版本取得了81.9% 的得分,超越了此前的开源霸主,甚至逼近并略高于顶尖商业模型的对标成绩(例如GPT-5-high约76.4%)。
为了理解MiroThinker的核心突破,我们需要先回顾一下当前LLM的局限性。
传统的大模型测试(Test-time Scaling)往往是在真空中进行的。模型接收一个问题,然后在内部进行推理(CoT),最后输出答案。这就像一个被关在密室里的学生,只能靠死记硬背的知识来答题。一旦遇到知识盲区,或者推理链条中途断裂,它就无计可施,只能开始“胡编乱造”。
MiroThinker引入了 “交互式扩展”(Interactive Scaling) 的概念。

想象一下,如果允许那个密室里的学生上网查资料、运行代码验证自己的猜想、甚至在发现思路错误时推倒重来,他的解题能力会发生什么变化?
研究团队通过强化学习,让MiroThinker-v1.0能够在在一个任务中执行高达600次的工具调用,这种极长的推理轨迹,允许模型:
通过实验数据证实,交互深度和频率的增加,与智能体性能的提升之间存在清晰的、可预测的关联,这被称之为“交互式扩展律”。这不仅是一个工程实现,更是一种新的理论发现,它为突破参数规模的限制带来了一种新的可能。
看到这里,资深的AI工程师可能会提出一个尖锐的问题:上下文窗口(Context Window)怎么办?
一个600轮的复杂交互,伴随着网页抓取的长文本、Python代码的报错信息、海量的搜索结果,会瞬间撑爆任何现有的上下文窗口(即使是256K也不够用)。如果简单的截断历史,模型就会“失忆”;如果保留全部,成本和显存都无法承受。
MiroThinker给出了一个极其优雅的工程解法:基于新近度的上下文保留(Recency-Based Context Retention)。
研究团队发现了一个有趣的认知规律:决策依赖于逻辑流,而非陈旧的观察结果。
当人类在解决问题时,我们能清晰地记得“我五分钟前尝试过这个方法,但是失败了”(这是Thought和Action),但我们通常记不清“那个失败的方法具体报错的几百行日志是什么”(这是Observation)。我们只需要知道它失败了,以及它为什么失败。

MiroThinker模仿了这种人类的记忆机制:

如果说架构是骨架,那么数据就是灵魂。MiroThinker之所以能超越同类,很大程度上归功于其构建的庞大合成数据集MiroVerse。
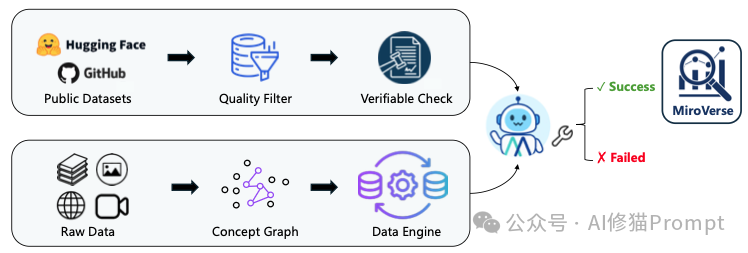
在构建训练数据时,团队面临一个经典难题:如何防止模型“作弊”?
在传统的QA数据集中,答案往往直接包含在文档中。模型只需要学会“关键词匹配”就能得分,这训练的是检索能力,而非推理能力。为了逼出模型的“深度思考”,MiroMind团队设计了一套名为 “约束混淆”(Constraint Obfuscation) 的绝妙机制。
让我们看一个例子:
在训练数据中,具体的时间(2002年)、地点(加州)、实体名称(马斯克)被系统性地替换成了间接的、需要推理的描述(temporal/spatial generalizations, referential indirection)。
这意味着,模型无法通过搜索“SpaceX成立时间”直接得到答案。它必须:
这种MultiDocQA Synthesis(多文档问答合成) 流程,强迫模型走出舒适区,通过跨文档的多跳推理(Multi-hop Reasoning) 来寻找答案。这就像是把模型送进了一个充满了谜题的迷宫,只有学会真正的逻辑推理,才能找到出口。
拥有了架构和数据,MiroThinker的最后一块拼图是训练方法。这也是它能实现“交互式扩展”的动力源泉。
MiroThinker的训练分为三个阶段:SFT(监督微调)、DPO(偏好优化)和RL(强化学习)。其中,Agentic Reinforcement Learning(智能体强化学习) 是最关键的一步。
在SFT阶段,模型只是在“模仿”人类专家的操作。但在RL阶段,团队使用了 GRPO(Group Relative Policy Optimization) 算法,让模型在沙箱环境中自由探索。
这里的核心在于奖励函数的设计(Reward Design)。
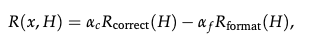
这个公式看似简单,却蕴含深意。

这种自由度带来了惊人的行为涌现。 实验数据显示,经过RL训练后的模型(30B版本),其交互轨迹发生了质变。
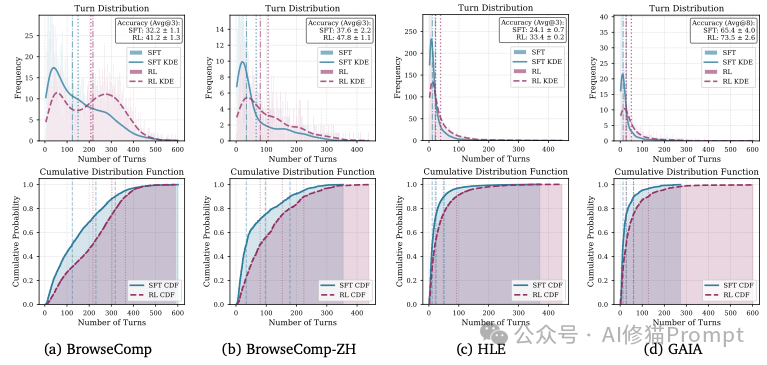
SFT模型往往倾向于尽早回答问题(这也是大模型的通病,急于求成)。而RL模型则表现得像一个“偏执”的科学家:它会花费大量的步骤去自我验证(Self-Verification),在得出结论前反复检查证据,甚至在发现搜索结果不理想时主动调整关键词重试。
正是这种通过RL涌现出来的“多想一步、多查一次”的特质,构成了交互式扩展的本质。
那么,这一套复杂的组合拳(交互扩展 + 新近度记忆 + 混淆数据 + GRPO),最终效果如何?
在多个权威基准测试中,MiroThinker交出了一份完美的成绩单:
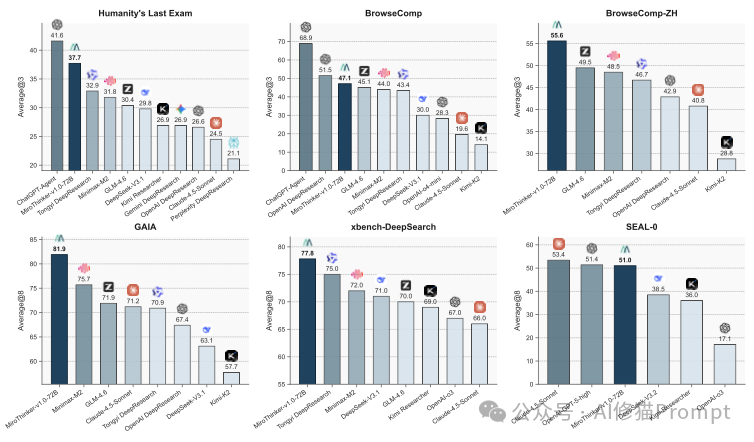
这些数据证明通过精细设计的交互机制和训练策略,72B参数的模型完全可以由“巧”取胜,在实际任务中通过深度推理弥补参数量的差距。
1. 工具使用的低效性 研究者坦诚地指出,RL虽然提升了效果,但也导致模型变得“啰嗦”,有时会为了交互而交互。如何在提升交互深度的同时保持工具调用的效率(Efficiency),将是下一个优化热点。
2. 语言混合问题 (Language Mixing) 在处理中文问题时,模型的内部推理(Thought)有时会夹杂英文,导致最终输出的中文质量受到影响(Chinglish 现象)。
3. 沙箱操作笨拙 模型虽然能写代码,但有时会忘记初始化沙箱,或者试图用Python代码去硬读取网页,而不是调用更高效的专用爬虫工具。
如果我们把AI的发展比作攀登珠峰,那么“模型规模”是北坡,“上下文长度”是南坡。这两条路虽然宽阔,但越往上走,空气越稀薄,边际效益越低。
MiroThinker向我们展示了第三条路,交互(Interaction)。通过RL鼓励模型“多交互、多验证”,可以在不增加模型参数的情况下显著提升复杂任务的推理能力。欢迎你来群里一起聊。
文章来自于“AI修猫Prompt”,作者 “AI修猫Prompt”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】ScrapeGraphAI是一个爬虫Python库,它利用大型语言模型和直接图逻辑来增强爬虫能力,让原来复杂繁琐的规则定义被AI取代,让爬虫可以更智能地理解和解析网页内容,减少了对复杂规则的依赖。
项目地址:https://github.com/ScrapeGraphAI/Scrapegraph-ai
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
