# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在推荐系统迈向多模态的今天,如何兼顾数据隐私与个性化图文理解?悉尼科技大学龙国栋教授团队联合香港理工大学杨强教授、张成奇教授团队,提出全新框架 FedVLR。该工作解决了联邦环境下多模态融合的异质性难题,已被人工智能顶级会议 AAAI 2026 接收为 Oral Presentation。
在当今的推荐系统中,利用图像和文本等多模态信息来辅助决策已是标配。然而,当这一需求遭遇联邦学习 —— 这一要求「数据不出本地」的隐私保护计算范式时,情况变得极其复杂。
现有的联邦推荐往往面临两难:要么为了保护隐私而放弃繁重的多模态处理,仅使用 ID 特征;要么采用「一刀切」(One-size-fits-all)的粗暴融合策略,假设所有用户对图文的偏好一致。
但现实是残酷的:用户的「融合偏好」天生具有极大的异质性。 购买服装时,用户可能更依赖视觉冲击;而挑选数码产品时,详尽的参数文本可能才是关键。这种偏好的差异,在数据不可见的联邦环境下,极难被捕捉。
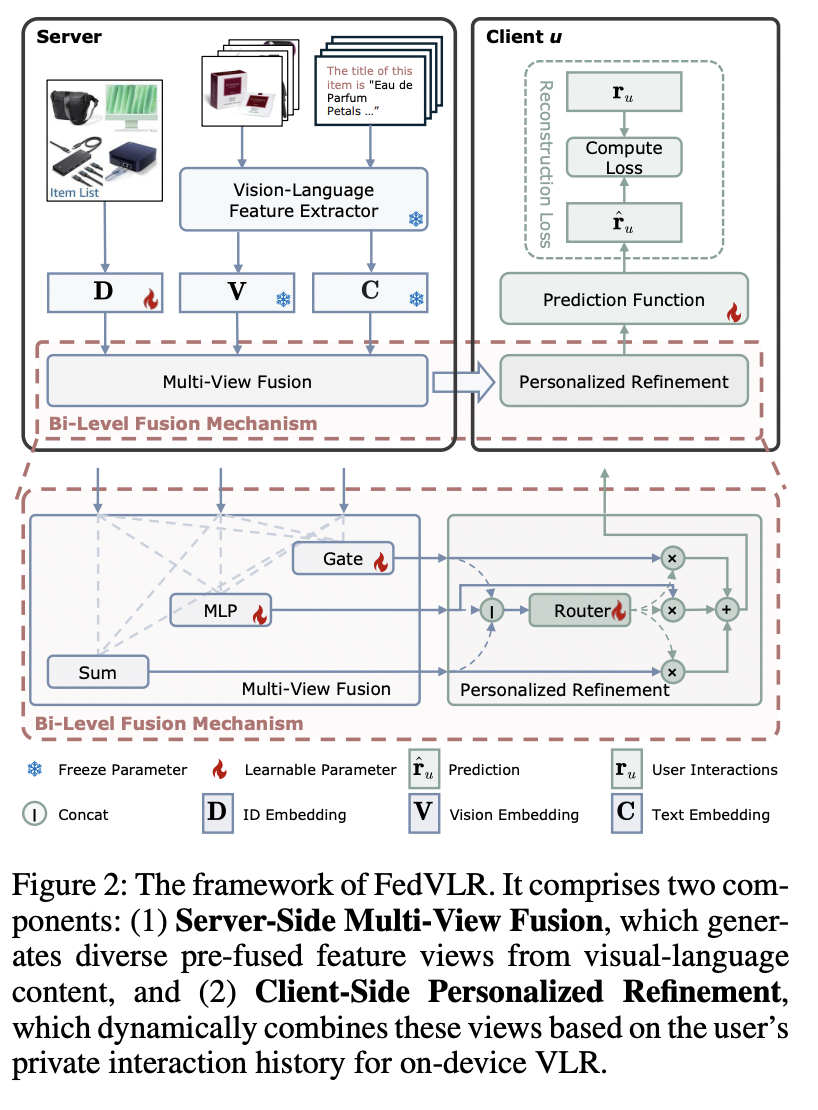
为了打破这一瓶颈,悉尼科技大学龙国栋教授团队,联合香港理工大学人工智能高等研究院杨强院长、香港理工大学深圳研究院张成奇院长推出了 FedVLR 框架。其核心洞见在于重构了多模态融合的决策流:将重计算的特征预处理留给服务器,而将决定「怎么看」的融合决策权,通过轻量级路由机制彻底下放给用户端侧。

在传统的中心化训练中,模型可以肆无忌惮地访问所有交互数据,轻松学习到图文融合的最佳权重。但在联邦学习中,服务器看不见用户的行为数据,也就无法得知:对于用户 A 来说,到底是图片重要还是文字重要?
这种「信息不对称」导致了现有方法的局限性:

FedVLR 创新性地提出了一种双层融合机制,巧妙地解耦了特征提取与偏好融合。
FedVLR 将繁重的计算任务锁定在服务器端。利用强大的预训练视觉 - 语言模型,服务器不直接下发原始特征,而是通过多种预设的融合算子,将物品的图像、文本和 ID 信息加工成一组「候选融合视图集」。
可以把这理解为服务器预先准备了多种口味的「半成品」:
这些视图包含了高质量的内容理解,却无需消耗客户端的算力来生成。
第二层:客户端的「个性化精炼」——MoE 路由机制,实现千人千面
当这些「半成品」视图下发到用户设备(如手机)后,FedVLR 引入了一个极其轻量的本地混合专家模块。
这个路由器的作用至关重要:它利用本地私有的交互历史,动态计算出一组个性化权重。如果本地数据显示用户偏爱看图,路由器就会赋予「视觉侧重视图」更高的权重。
这一过程完全在本地发生,确保了用户的偏好数据从未离开设备。
FedVLR 的设计哲学不仅仅是提出一个新模型,更是提供一种通用的增强方案。
它被设计为一个可插拔的层,具有极高的工程落地价值:

研究团队在电商、多媒体等多个领域的公开数据集上进行了严苛的测试。
实验结果表明:
FedVLR 的价值不仅限于推荐系统本身,它更为联邦基础模型的落地提供了一种极具启发性的范式。
在端侧算力受限、而云端大模型能力日益增强的背景下,如何在不传输原始数据的前提下,让边缘设备低成本地享受到大模型的通用知识,是业界亟待解决的难题。
FedVLR 实际上展示了一种「云端大模型编码 + 端侧微调适配」的高效协同路径。它证明了我们无需在每个终端都部署庞大的多模态模型,只需通过精巧的架构设计,将云端的通用内容理解能力与端侧的私有偏好解耦。
这种思路极大地降低了联邦学习的通信与计算门槛,为未来将更复杂的视觉 - 语言模型甚至生成式 AI 引入隐私敏感场景铺平了道路,是构建下一代「既懂内容、又懂用户、且严守隐私边界」的智能系统的关键一步。
目前,该论文代码已开源,欢迎社区关注与试用。
李志伟,悉尼科技大学博士生,研究方向为联邦推荐系统。
龙国栋、江静,悉尼科技大学副教授,专注于联邦学习。
张成奇,香港理工大学深圳研究院院长,在数据挖掘、人工智能理论与应用方面具有广泛影响力。
杨强,香港理工大学人工智能高等研究院院长、国际人工智能领域领军人物,提出迁移学习与联邦学习多项奠基性成果。
文章来自于“机器之心”,作者 “李志伟、龙国栋、江静、张成奇、杨强”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
