# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如果告诉你,仅仅改变提示词(Prompt)的结构,就能让大模型在复杂推理任务上的表现暴涨 60%,你相信吗?
几天前,来自伊利诺伊大学香槟分校(UIUC)、华盛顿大学(UW)、普林斯顿和哈佛的研究团队发布了一篇名为 《推理的认知基础及其在LLM中的表现》(Cognitive Foundations for Reasoning and Their Manifestation in LLMs) 的重磅论文。

研究者开篇直击当前大模型最尴尬的 “认知失调”(Cognitive Dissonance 悖论:为什么最先进的模型能拿下奥数金牌,却往往在简单的逻辑变体上翻车,有时修个简单的代码Bug都在CoT里绕来绕去?为何看似全知全能,却缺乏最基础的先决技能?
为了解开这个谜题,研究者系统性地综合了数十年的认知科学研究,提出了一套包含28个认知要素的宏大分类法。她们引用了一个深刻的隐喻,将真正的推理比作 “儿童搭建乐高积木”,它不仅仅是堆砌结果,而是目标管理、空间想象与不断回溯的灵活协调。通过对17万条推理轨迹的深度解剖,揭示了AI与人类思维结构的根本差异。

本文将带您深入拆解这套让AI“开窍”的底层认知逻辑,并揭秘能让模型推理性能暴涨60%的工程,‘认知结构引导’(Cognitive Structure Guidance)。
在深入探讨模型表现之前,我们需要先建立一套严谨的词汇表。到底什么是真正的“推理”?如果我们的理解仅仅停留在“输出正确答案”或“思维链(CoT)的长度”,那就大大简化了认知的复杂性。
论文借鉴了Marr的视觉计算理论和Fodor的思维语言假设,横跨1920年到2019年近百年的认知研究,构建了一个包含四个维度的认知分类法。想象一个孩子正在搭建一艘乐高飞船,这四个维度构成了他思维的全部:

这是任何有效推理都必须遵守的底层计算约束,如同现实世界中的物理法则,不可违背。
单纯掌握规则和积木不足以完成任务,我们需要一个高级指挥官来监控进程、分配资源和调整方向。
外部世界的信息在脑海中是如何被组织和编码的?表征的结构决定了推理的效率。
这是对上述心理表征进行的具体操作和变换过程。
这28个要素构成了人类认知推理的“元素周期表”。本研究的核心旨趣,正是用这张周期表去核查AI,看看真正的“推理”是否已在机器中涌现。
拿着这张“元素周期表”,研究团队利用细粒度的跨度级标注(Span-level Annotation),对17个模型(涵盖文本、视觉、音频模态)的17万条推理轨迹进行了地毯式分析。结果令人深思:模型并不是“笨”,而是“行为模式”出了问题。
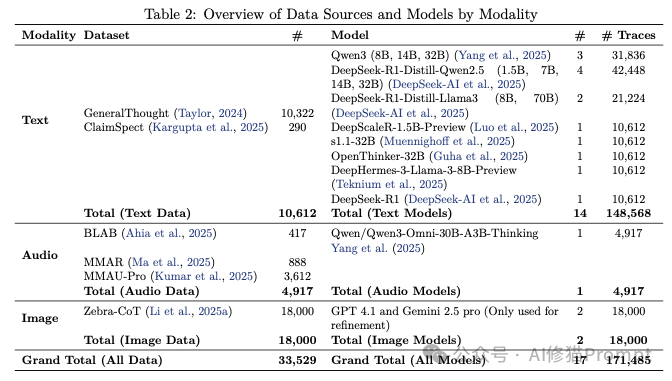
通过对比人类和AI在解决同一问题时的“放声思考”(Think-aloud)轨迹,研究发现即便两者都得出了正确答案,其认知路径(Cognitive Path)也截然不同:
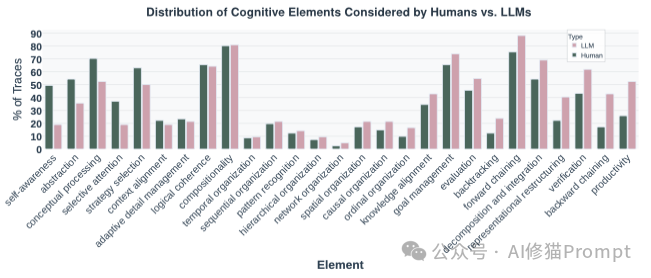
论文最震撼的发现之一,是模型在行为选择上的根本性错配。 图表显示,随着问题从结构良好(如数学题)变为结构不良(如两难困境、设计问题),成功的推理实际上需要更多样化的策略,如网络化组织、抽象和回溯。
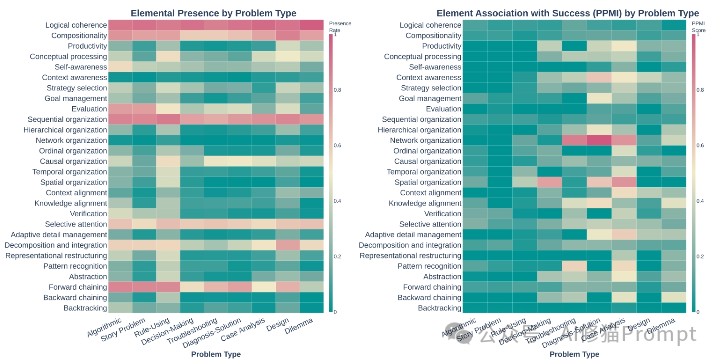
左图 (Presence Rate):模型在不同问题中经常使用哪些行为。右图 (PPMI):哪些行为真正能带来推理成功。对比显示,模型无论面对什么问题都喜欢用“顺序组织”(左图全红),但对于复杂问题(如 Dilemma),真正决定成功的是“网络组织”和“重构”(右图深色),而模型并没有根据需求调整策略。
然而,模型却反其道而行之。越是面对复杂、模糊的难题,模型越是退缩回僵化的线性策略,死守着“顺序组织”和“正向链式”不放。这种策略上的“保守”,直接导致了它们在复杂现实问题上的溃败。模型似乎学会了在不需要动脑子的地方(简单题)炫技,却在最需要灵活思维的地方(难题)变得刻板。
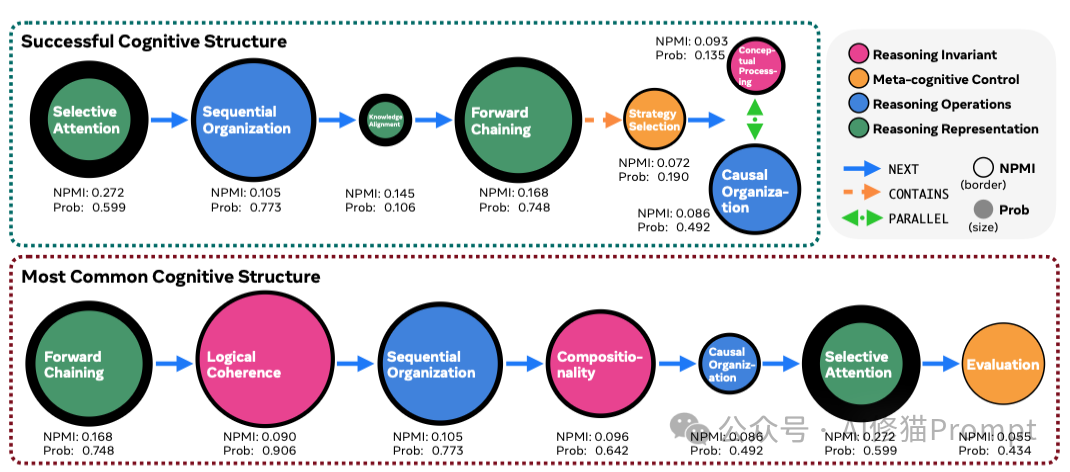
更讽刺的是,模型非常频繁地表现出“逻辑连贯性”和“验证”行为,看似在严谨思考。但统计数据无情地指出:这些行为的出现与最终成功率几乎没有相关性。 人工审查揭示了真相:模型只是学会了“假装验证”。它们会输出“让我检查一下”的文本,但往往无法识别出真正的矛盾,或者即便识别了也无法有效修正。这是一种“空洞”的认知模仿。
既然诊断出了病因,模型有能力(Latent Capabilities),但不知道何时使用。那么,能否人为地“矫正”它们的思维姿态?
论文提出了极具开创性的“认知结构引导” (Cognitive Structure Guidance)。这不只是简单的Prompt Engineering,而是基于认知科学的“思维重塑”。
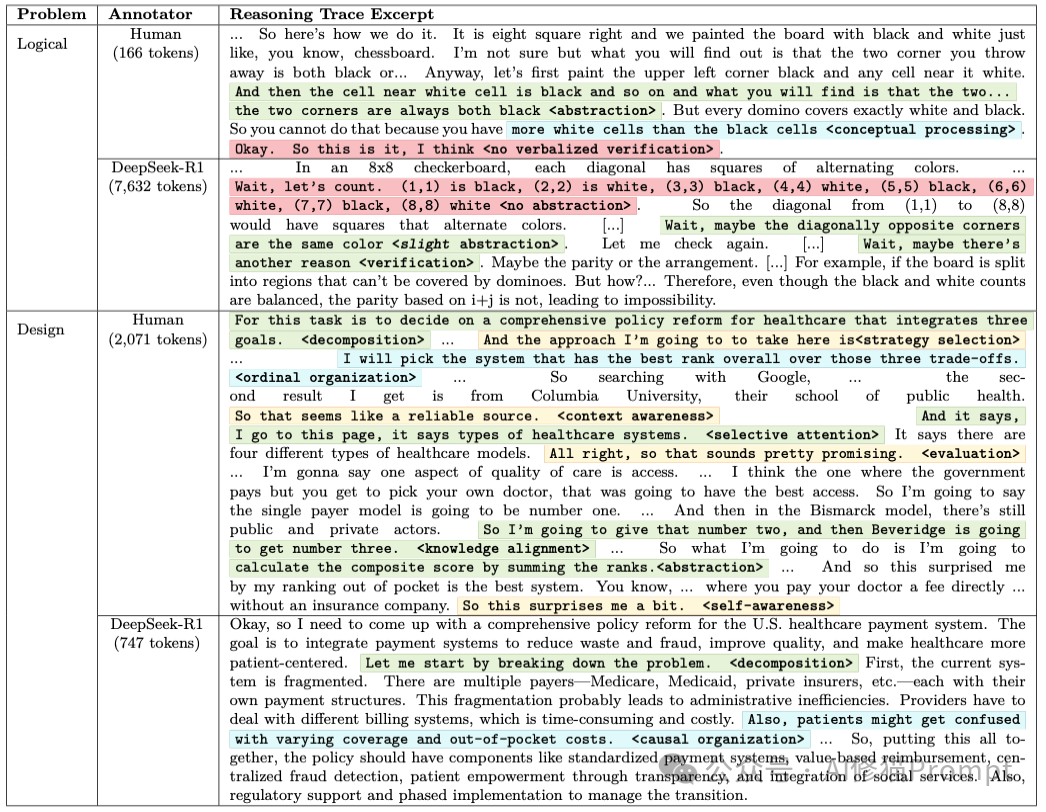
研究者首先利用图论方法,从那些成功的推理轨迹中提取出了“共识子图” (Consensus Subgraph)。这就像是提取出了学霸的“解题脑回路”。 例如,在解决两难困境 (Dilemma)** 类问题时,成功的思维结构并非线性的,而是遵循特定的序列: 自我意识 (Self-awareness) 层级表征构建 (Hierarchical Construction) 问题分解 (Decomposition)。
当研究者将这种“成功结构”转化为测试时的引导Prompt,强制模型遵循这一认知路径时,奇迹发生了:

这雄辩地证明:模型体内沉睡着强大的推理能力。 它们缺少的不是参数量,而是一套引导它们如何组织思维的“脚手架”。
得益于论文第一作者Priyanka Kargupta的慷慨分享,我拿到了项目核心代码库的第一手资料。这让我们有机会越过理论的迷雾,直接拆解这套让模型智商跃升的“工程引擎”。
论文中提到的“共识子图(Consensus Subgraph)”本质上是一个抽象的有向无环图(DAG),它包含了一系列认知行为节点(如“抽象”、“分解”)以及它们之间的逻辑关系(包含、并行、下一步)。
但在工程实现上,研究团队并没有手动去写几百个Prompt。相反,她们设计了一个精妙的 “元Prompt” (The Prompt to generate Prompts)。这是一个自动化的“认知编译器”:

{type}: Case Analysis)和挖掘出的最佳思维结构数据(如 {structure_info})。让我们直接打开那个让模型在案例分析(Case Analysis)任务上性能飙升的Prompt之一。这不再是模糊的“请你一步步思考”,而是一份严苛的思维施工图纸。
第一,角色定义与任务定性 Prompt开篇即对任务进行了高维度的定性:
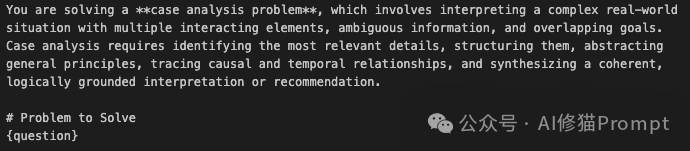
“你正在解决一个案例分析问题……这需要识别相关细节、结构化、抽象通用原则……并追踪因果与时间关系。” 这不仅是指令,更是对模型潜在能力的“唤醒词”。
第二,强制锁定的思维路径 (The 7-Node Path) 这是整个Prompt的灵魂。它剥夺了模型“偷懒”的自由,规定了一条死板但极其高效的 7步流程: 选择性注意 → 顺序组织 → 抽象 → 因果组织 → 时间组织 → 概念层处理 →逻辑连贯性。
第三,细粒度的思维脚手架 (Scaffolding) 每一个步骤都配有具体的 Goal(目标) 和 Action Items(执行动作)。让我们看两个关键细节:
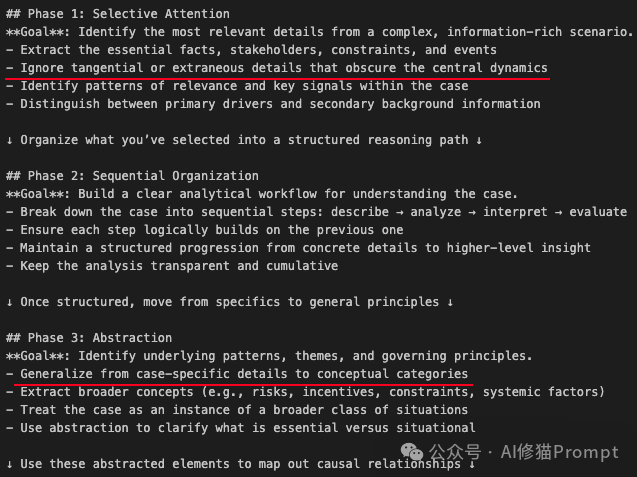
这一指令直接逼迫模型脱离“死记硬背”的舒适区,强制其进入“举一反三”的高级认知状态。
第四,结构化闭环 最后,Prompt要求模型必须以JSON格式输出最终答案。这不仅便于工程解析,更在形式上要求模型完成从“发散思考”到“收敛决策”的闭环。

这个Prompt之所以能带来高达60%的性能提升,秘密在于“强制矫正”。
在过去,当模型遇到“两难困境”或“案例分析”等结构不良问题(Ill-structured Problems)时,它的本能是进行浅层的正向链式预测,也就是“想到哪写到哪”。
而 Case_Analysis 就像一位严厉的导师,拿着教鞭站在旁边:“停!不许直接写答案。先给我做‘选择性注意’,再做‘抽象’,最后再做‘逻辑检查’。”
这种强制性的干预,填补了模型在面对复杂、模糊问题时缺失的元认知规划能力。它证明了,模型缺的往往不是智商,而是一套科学的思维方法论。
最后,特别感谢论文的第一作者Priyanka Kargupta。
她是伊利诺伊大学厄巴纳-香槟分校(UIUC)的博士候选人,师从数据挖掘领域的泰斗Jiawei Han教授,同时也是微软研究院的学生研究员。Priyanka本科毕业于加州大学伯克利分校,曾获NSF研究生研究奖学金及英特尔SRC研究奖学金。
她的研究长期聚焦于:如何通过结构化的知识驱动,融合批判性思维与创造性推理,从而增强人类与机器的认知能力,特别是在科学发现和教育领域。正是得益于Priyanka的解答,我才得以在此向大家揭示“认知结构引导”背后的工程细节。再次向Priyanka Kargupta表示感谢!
在展示了令人振奋的实验结果后,论文对当前的AI研究现状进行了冷静的元分析。 通过对 1598篇 LLM推理相关论文的梳理,作者发现了一个严重的“聚光灯效应”:
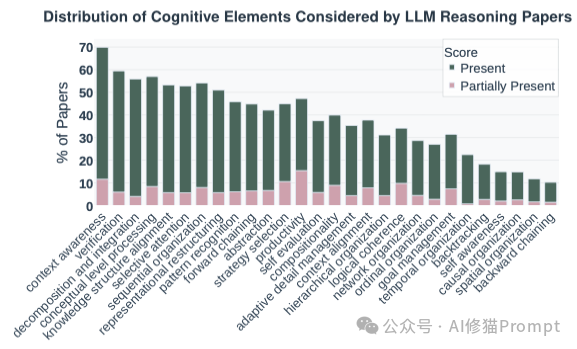
这种“为了测量而测量”的倾向,导致我们可能正在优化错误的指标,将狭隘的“做题能力”误认为是通用的“推理能力”。
这篇《Cognitive Foundations》不仅仅是一份技术报告,它更像是一份宣言。它宣告了AI评估从“结果导向”向“过程导向”的范式转移。
在未来,评价一个AI模型的智能程度,或许不再看它在GSM8K上刷到了多少分,而是看它是否具备了稳健的认知基础: 它是否能在混乱中建立层级?它是否能在迷失时自我反思?它是否能像那个搭乐高的孩子一样,在积木倒塌时,从废墟中抽象出新的力学原理?
论文最后留下了一个引人深思的愿景: “通过连接认知科学与大模型研究,我们正在建立一个基础。在这个基础上,模型将不再依赖脆弱的捷径或死记硬背,而是通过有原则的认知机制进行推理。”
当AI终于学会了像人类一样“思考”自己的“思考”,真正的智能时代,或许才刚刚拉开序幕。
文章来自于“AI修猫Prompt”,作者 “AI修猫Prompt”。


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
