# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
全模态大模型(Omnimodal Large Models, OLMs)能够理解、生成、处理并关联真实世界多种数据类型,从而实现更丰富的理解以及与复杂世界的深度交互。人工智能向全模态大模型的演进,标志着其从「专才」走向「通才」,从「工具」走向「伙伴」的关键点。
然而,如何在一个模型中同时兼顾强大的多模态理解与高质量生成,如何构建高效而统一的模型架构,如何设计合理的训练方法和数据配比方案,仍是当前学术界与工业界共同的挑战。
近日,哈工大深圳计算与智能研究院 Lychee 大模型团队,在 2023 年研发的「立知」大语言模型基础上(工信部和网信办双认证),基于 2024 年 5 月提出的原创 Uni-MoE 全模态大模型架构,正式发布第二代「立知」全模态大模型 Uni-MoE-2.0-Omni。
该模型以大语言模型为核心,通过渐进式模型架构演进与训练策略优化,将稠密大语言模型拓展为混合专家架构驱动的高效全模态大模型,实现了从「语言理解」到「多模态理解」,再到「理解与生成兼备」的跨越式升级!团队围绕以语言为核心的通用人工智能,通过引入全模态 3D RoPE 位置编码、设计动态容量 MoE 架构以及全模态生成器等关键技术,有效打破了不同模态之间的壁垒,在维持高效计算性能的同时,实现了对图像、视频、文本与语音的统一理解、推理与生成。
值得一提的是,Uni-MoE-2.0-Omni 在图像理解、视频推理、音频理解、语音生成、图像生成与编辑等 85 项基准上取得高度竞争性或领先的表现,在 76 项可对比评测中,Uni-MoE-2.0-Omni(75B Tokens)超越 Qwen2.5-Omni(1.2T Tokens)逾 50 项任务,不仅在视频理解和全模态交互上取得显著突破,更在长语音生成、多模态语音交互和可控图像生成与编辑方面树立了新标杆。

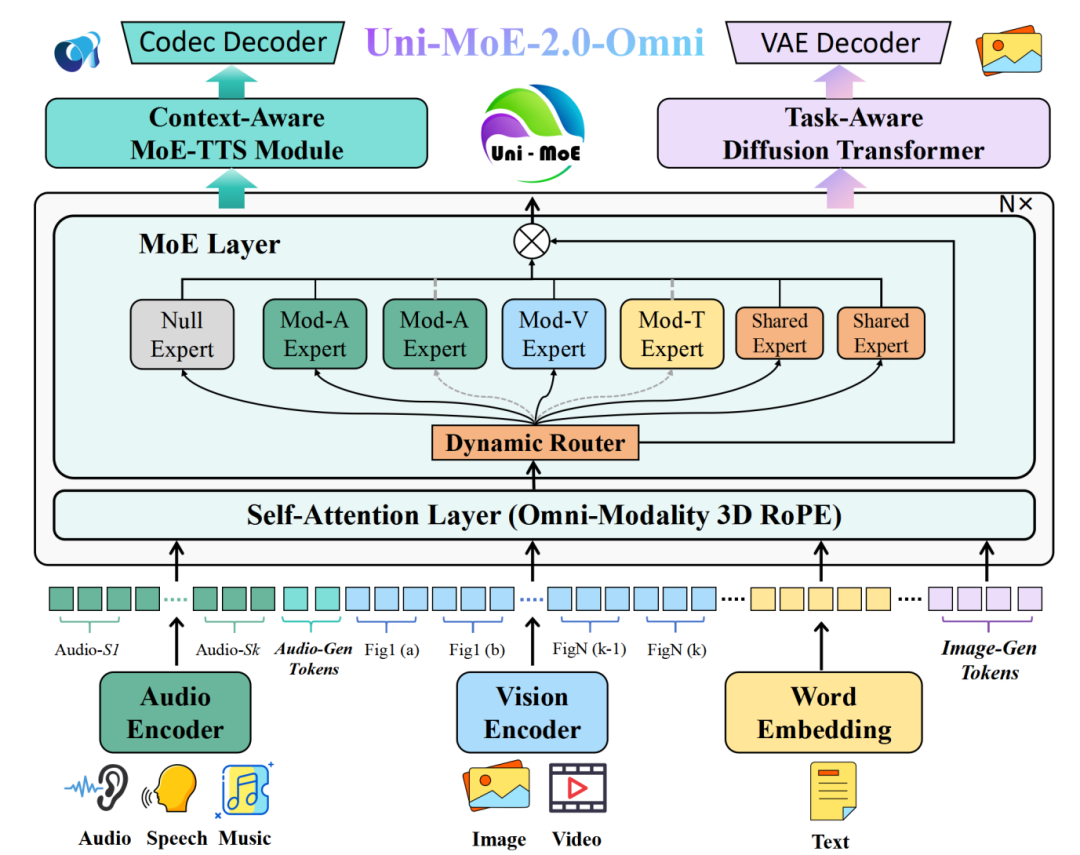
Uni-MoE-2.0-Omni 以语言核心(LLM),通过统一的感知(Uni-Perception)与生成(Uni-Generation)模块,实现对文本、图像、视频、音频等多模态信号的全链路处理。这一架构由统一模态编码、动态 MoE 以及全模态生成器三大核心组件构成,旨在打破模态间的壁垒,实现从感知到生成的全链路统一。
1. 统一模态编码:为实现真正的多模态统一表示,Uni-MoE-2.0-Omni 采用了统一的 Token 化策略。在视觉方面,模型借助 SigLIP 编码器处理任意分辨率的图像与高帧率视频,并通过滑动窗口编码实现能力的平滑迁移;在音频方面,基于 Whisper-Large-v3 将 30 秒音频压缩为仅 200 个 Token,显著提升了长语音的理解效率。更重要的是,模型引入了 Omni-Modality 3D RoPE 机制,构建了一个覆盖文本(时间)、图像(空间)、视频(时空)和音频(绝对时间)的统一坐标系。这一设计彻底解决了跨模态位置编码不一致的问题,为高精度视频理解与视听对齐奠定了坚实基础。
2. 动态混合专家:Uni-MoE-2.0-Omni 的核心架构升级为新型的 Dynamic-Capacity MoE。不同于传统混合专家架构的固定路由,该架构支持动态专家数,即根据 Token 的难易程度自动分配算力,实现轻重缓急的自适应处理。同时,模型创新性地引入了三类专家角色:负责特定模态知识的路由专家、促进跨模态知识迁移的共享专家,以及用于跃层加速的空专家。配合路由梯度估计(Routing Gradient Estimation)技术,该架构有效解决了离散选择无法反向传播的痛点,在降低训练与推理算力的同时,显著提升了模型的稳定性与记忆管理能力。
3. 全模态生成器:Uni-MoE-2.0-Omni 通过特殊的控制 Token,将所有理解与生成任务统一纳入语言模型的语义空间,实现了理解即生成的无缝流转:在语音生成方面,其上下文信息驱动的 Uni-MoE-TTS 可以实现两分钟以上的语音回复,支持中英三种音色。在视觉生成方面:引入任务感知的扩散模型,通过深度融合视觉、任务与内容信号来联合驱动图像生成与编辑,显著提升了图像编辑和复原的准确性。
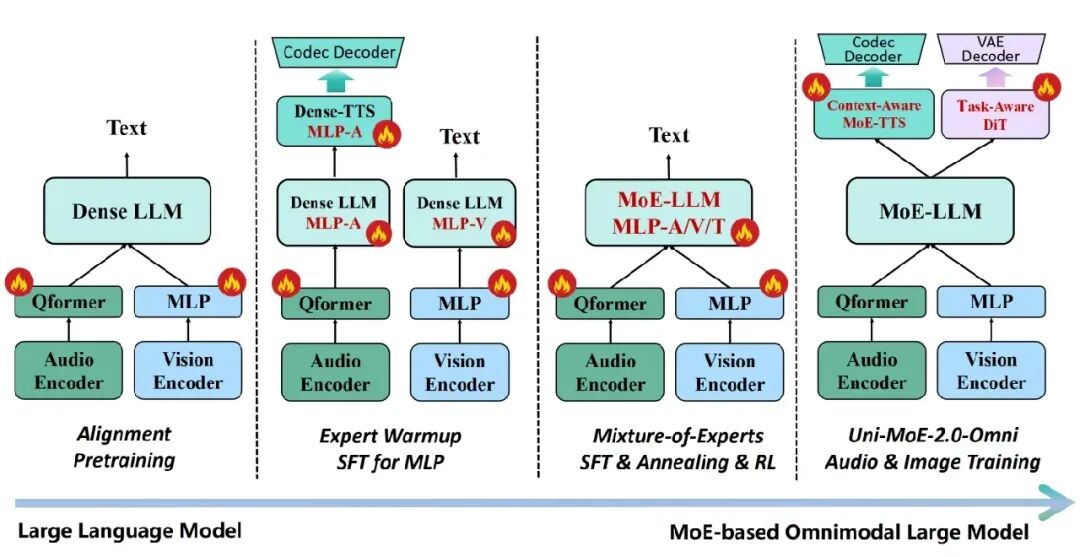
针对混合专家架构在全模态大模型训练中易出现不稳定的问题,该团队设计了渐进式训练策略,依次推进:跨模态对齐→专家预热→MoE 微调与强化学习→生成式训练。该渐进式的模型演进和训练流程能够以较少的数据量(75B),将稠密大语言模型 (Qwen2.5-7B) 高效扩展为全模态大模型,并保障在全模态数据环境下强化训练的收敛稳定性。
针对多模态理解与生成任务在训练中往往割裂的问题,该团队提出以语言生成任务为锚点的多模态理解与生成联合训练方式。通过将图像编辑与生成、语音合成等任务统一至语言生成框架,打破理解与生成之间的内在界限,实现两者能力的协同增强与双向赋能。
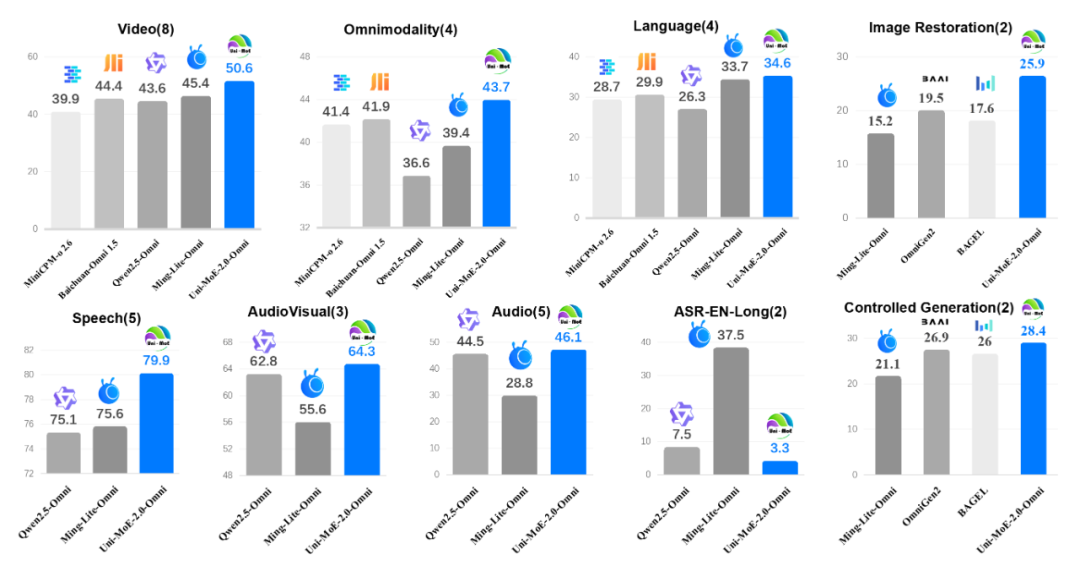
为了验证 Uni-MoE-2.0-Omni 的全能实力,研究团队在多达 85 个基准测试上进行了地毯式评估。结果显示,该模型在理解能力与生成质量上均取得了质的飞跃,不仅在35 个任务上达到最佳性能(SOTA),更在 50 个评估任务上全面超越了 1.2T Token 训练的 Qwen2.5-Omni,其中在 8 个视频评估基准和 4 个全模态理解基准较 Qwen2.5-Omni 提升 7%,展现了极高的数据利用效率与架构优势。
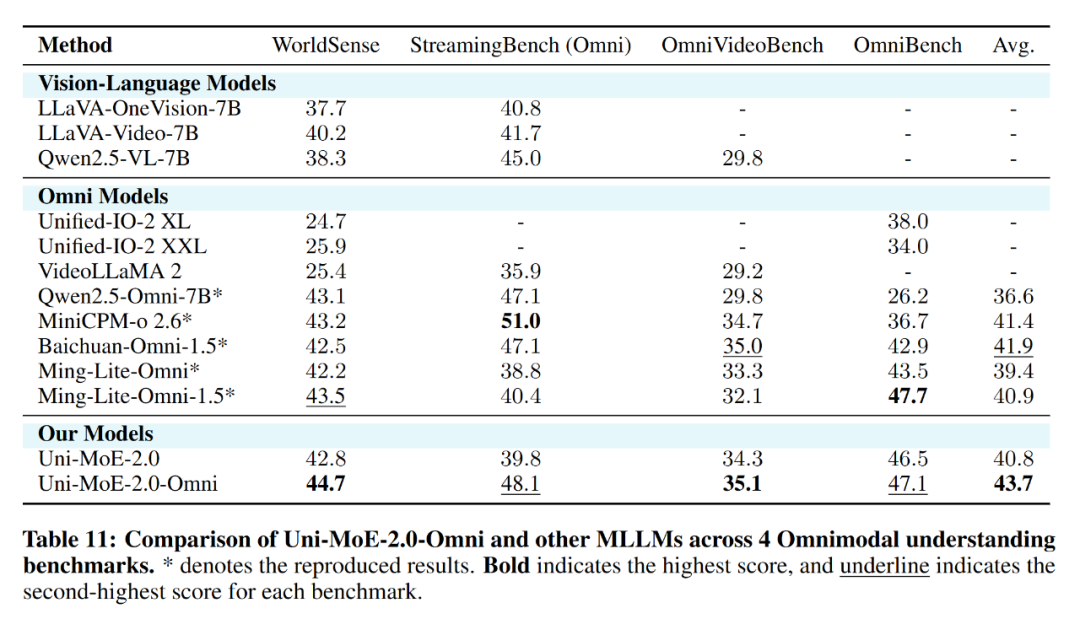
全模态理解
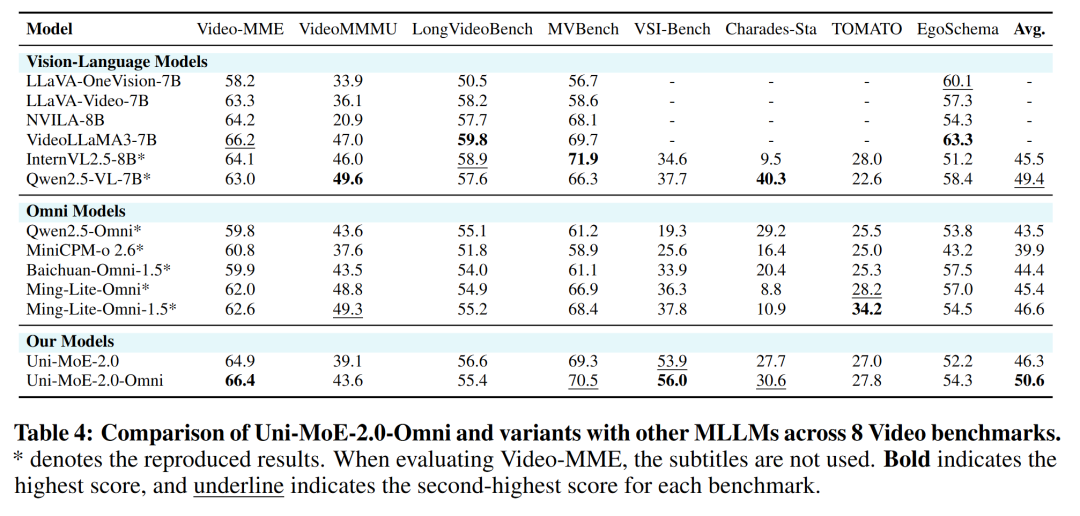
视频理解
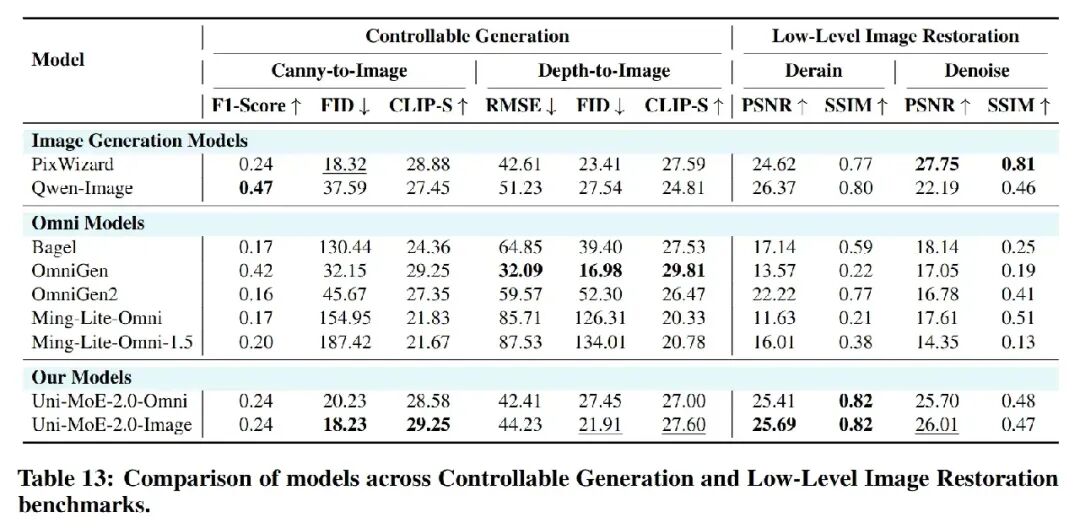
可控生成与图像复原
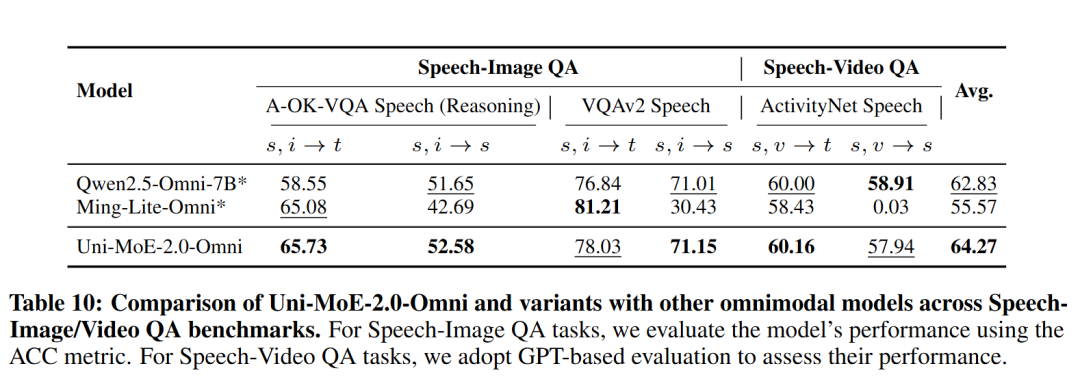
多模态语音交互问答
给它一个图表题,它不仅具备 OCR 能力,而且能基于 OCR 结果进行数学推理。

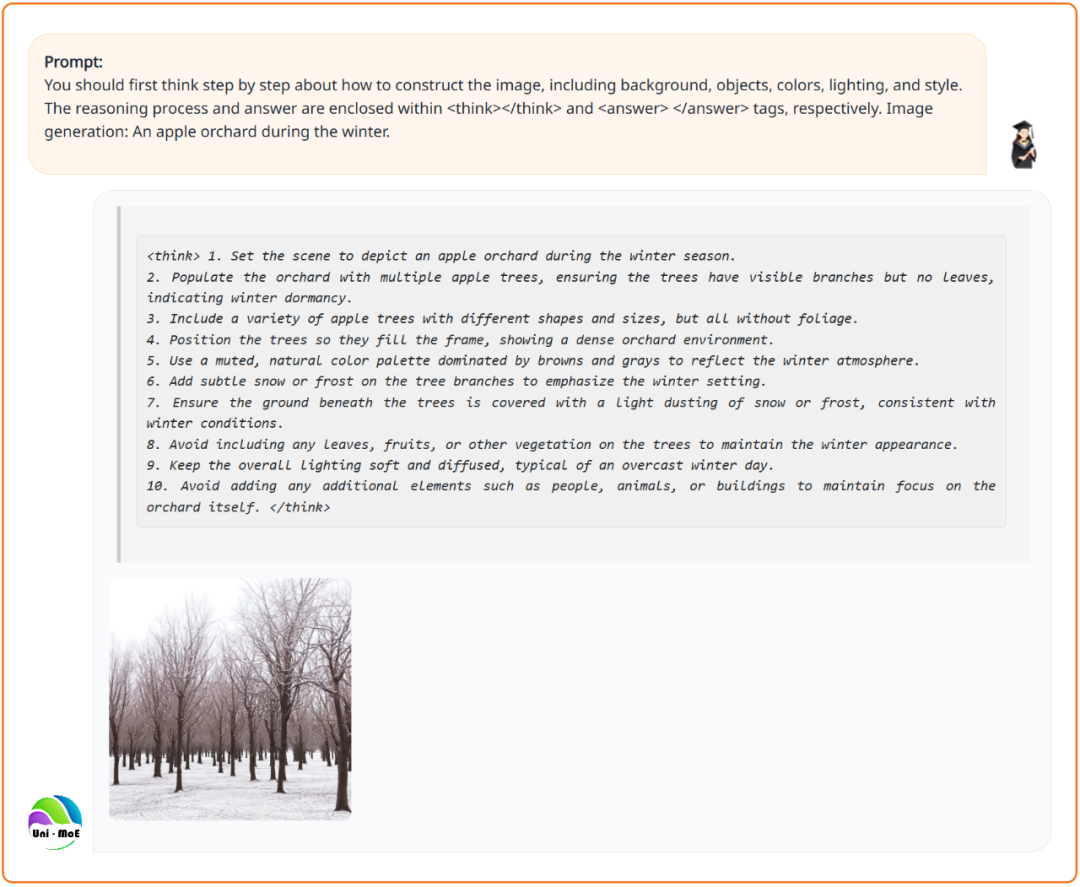
生成冬天的苹果园时,考虑季节因素,避免「画蛇添足」。

保持人物主体不变,根据指令修改图片。
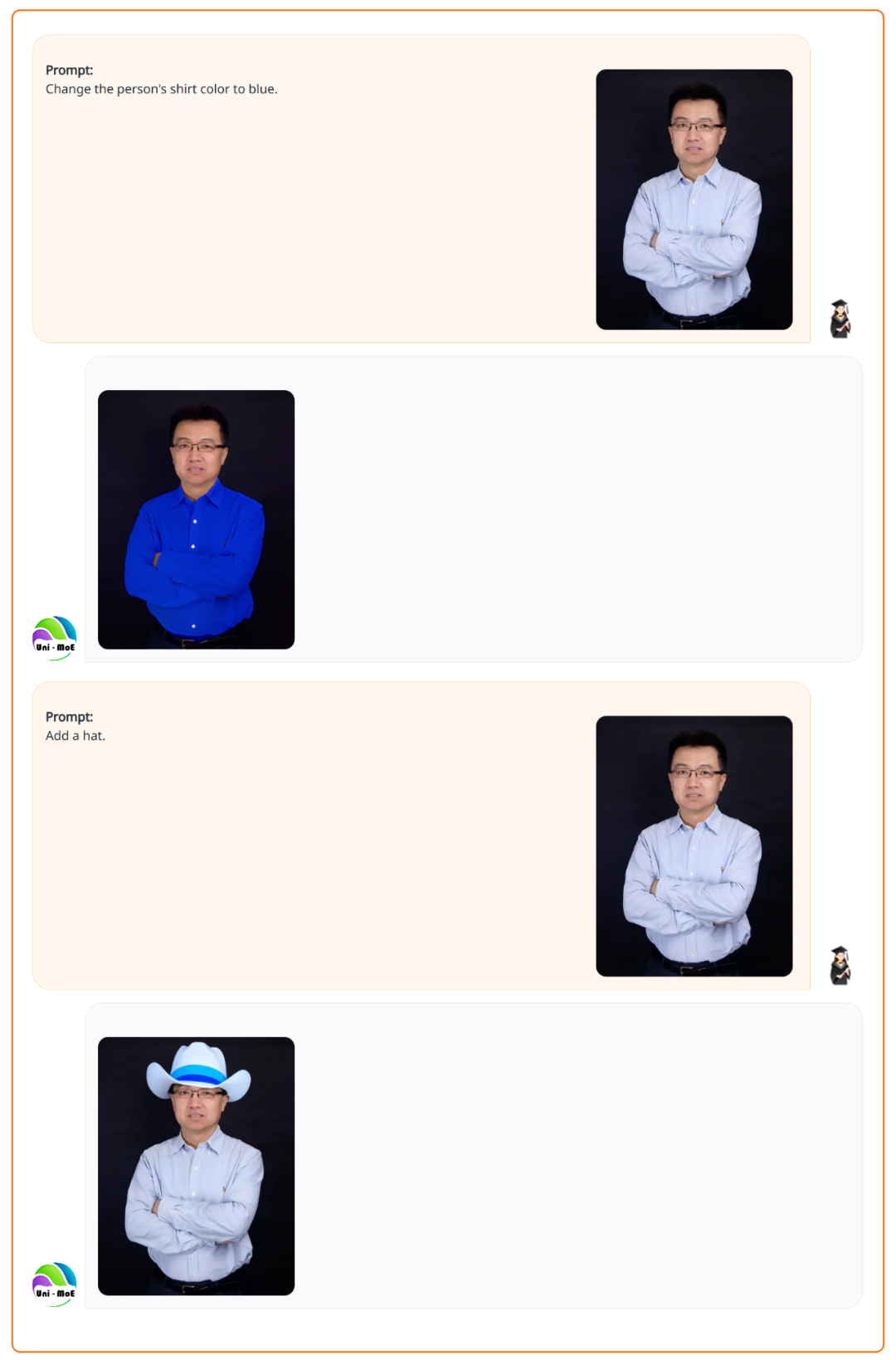
给它雨 / 雾 / 雪 / 暗等低质量图片,秒变清晰原图。

给它一张照片,精确定位旅游景点。
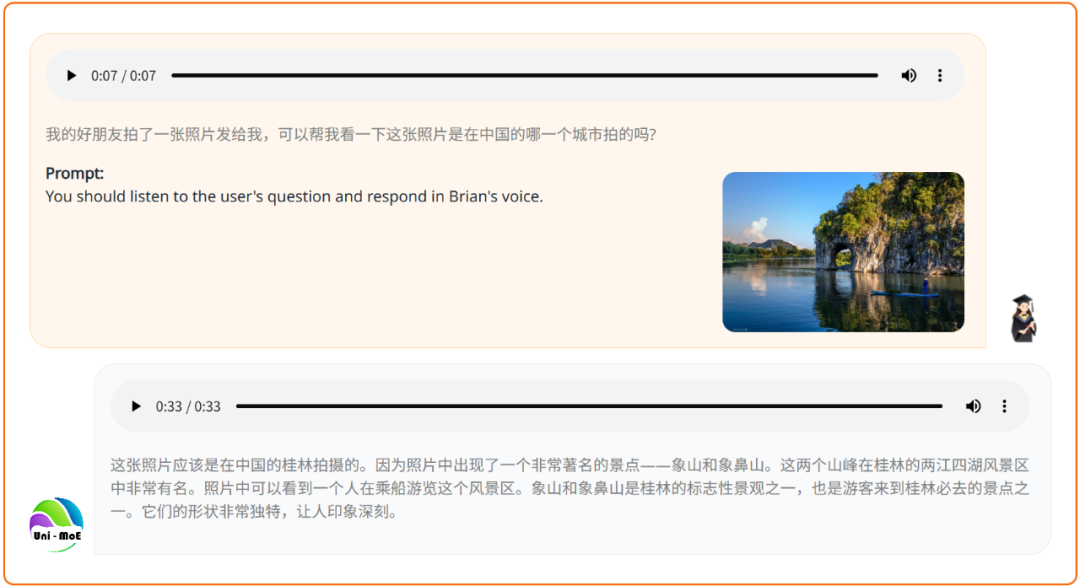
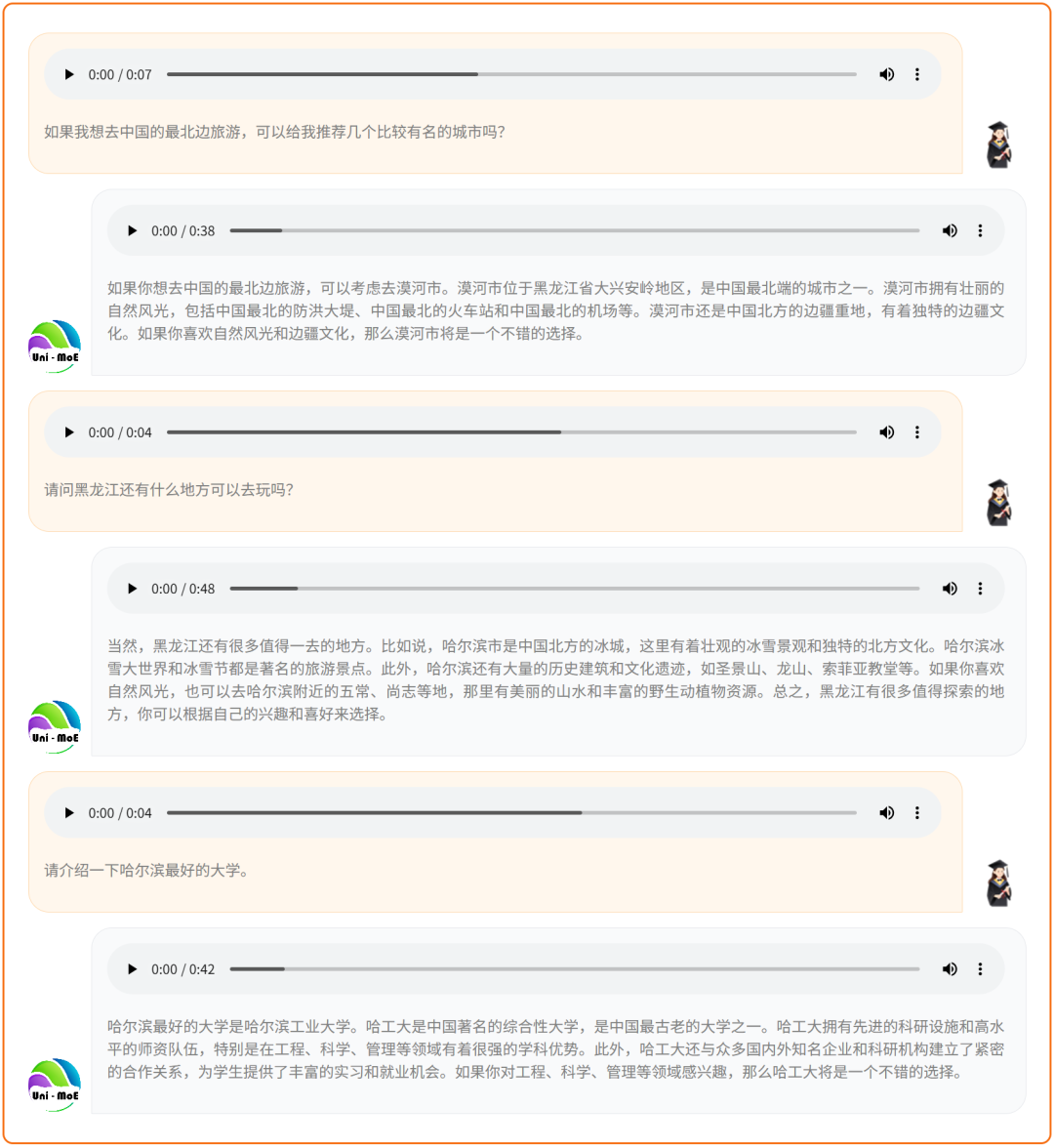
化身智慧助手,精准捕捉话题流转,连续响应用户意图。
Uni-MoE-2.0-Omni 是一个架构先进、完全开源的全模态大模型。从 Uni-MoE 1.0 到 2.0,该系列模型不仅验证了将稠密大语言模型扩展为全模态模型的路径,更实现了从单纯的「多模态理解」向「理解生成一体化」的跨越。该模型的发布,为社区提供了一个强有力的全模态基座,其代码、模型权重及数据清单的开源,将进一步推动通用多模态人工智能的研究与应用发展。
文章来自于“机器之心”,作者 “机器之心”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
