# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
被顶会ICCV 2025以554高分接收的视频理解框架来了!
视频包含的信息远比图像复杂,现有的Video-LLM常靠下采样或Token聚合来“挤”进语言模型,难免会丢细节并造成语义纠缠(entanglement)。

于是,北大和UCSD团队提出VideoOrion——

直接把前景里显著的时空动态编码成Object Tokens并与Context Tokens并行喂给LLM,搭建出一个高效、可解释、具指代能力的视频理解框架。
将Object Dynamics显式提炼成离散的Token,既可压缩数据量,又让LLM的对齐更自然。
实验显示,它在MVBench、EgoSchema、Perception-Test、VideoMME、ActivityNet-QA等上整体领先,并自然演化出视频指代问答能力。

传统视频Token多是按空间栅格或特征聚合得到,语义容易纠缠。
VideoOrion把对象及其跨帧演化当作一级语义单位,使LLM在推理时可以沿对象维度整合细节,既提升细粒度问答,也为指代等需要“锁定实例”的任务提供天然接口。
在以下案例中:相比仅场景级描述,模型能说清“红色三轮滑板车+拖地组件”的细节或“黑色泳装+跳板后空翻”的动作要素。

据了解,VideoOrion采用双分支并行编码:
两类Token将被一起输入LLM融合推理。

因为视频里前景会进出画面、场景突变,研究另提出按前景物体出现变化自适应切片以稳健检测与关联,避免均匀切段带来的跨段错配。
在对象流水线的替换实验中(提案器/分段策略/跟踪器),无论用RAM++、Mask2Former做提案,还是改为均匀/不切分,或以SAM2替代XMem,整体都稳定优于仅视频分支,最佳组合为RAM++分段 + GroundingDINO提案 + XMem跟踪。
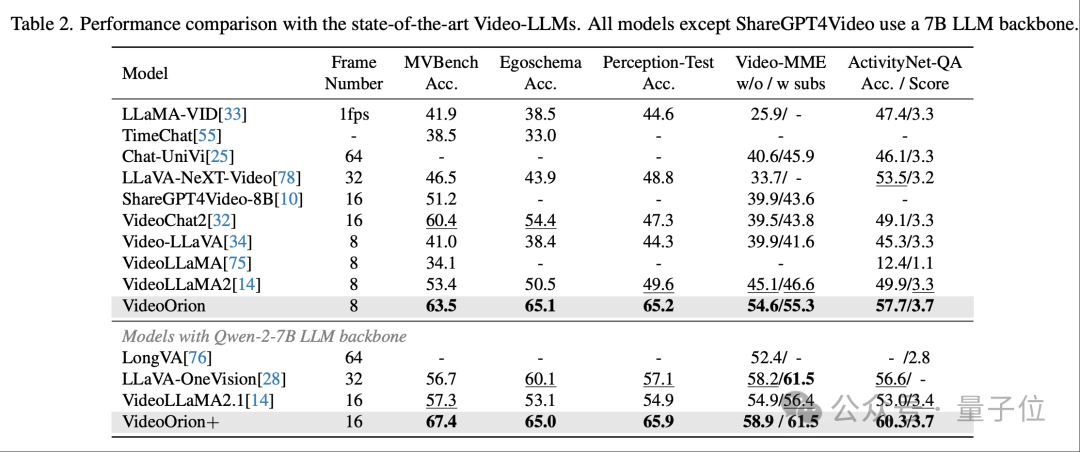
VideoOrion(7B)在MVBench / EgoSchema / Perception-Test / VideoMME / ActivityNet-QA上,全面超越同backbone的VideoLLaMA2/2.1。
具体相对涨幅分别为+10.1%、+14.6%、+15.6%、+8.7%、+7.8%(VideoOrion+亦有相近或更高增幅),体现了Object Token带来的细粒度语义增益。
进一步看表格数值:在7B LLM设置下,VideoOrion在 MVBench/EgoSchema/Perception-Test/VideoMME(w/o/w subs)/ActivityNet-QA(Acc/Score)达到63.5 / 65.1 / 65.2 / 54.6–55.3 / 57.7–3.7,相对多款开源/闭源同规模模型具有明显优势。
得益于显式Object Token,VideoOrion天然支持视频指代——
在提示模板中把目标对象对应的Token填入<o> 即可完成“指这个物体在做什么”的问答。
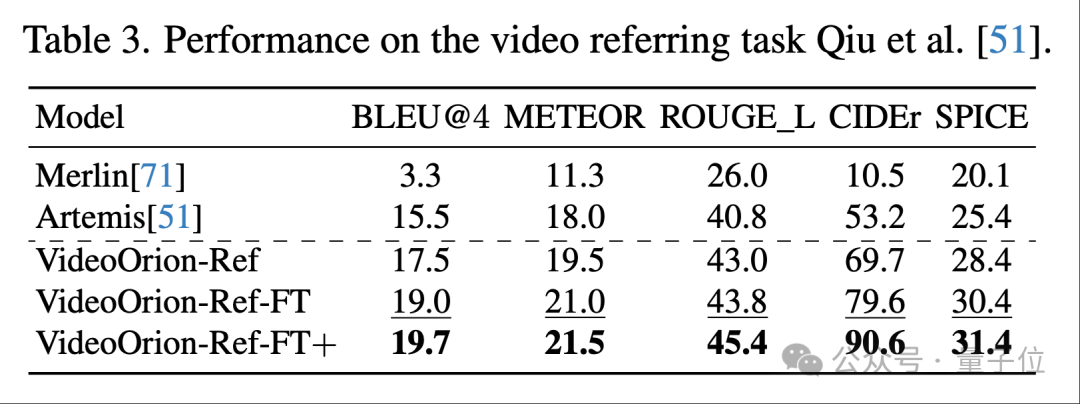
团队在VideoRef45K上对比Artemis、Merlin等方法,零样本即有效,经小规模指代数据微调后(3 epoch)多项指标(BLEU@4、METEOR、ROUGE_L、CIDEr、SPICE)全面领先,验证Object Token对指代理解的直接助益。
1、有无对象分支:在等数据量下,把对象分支去掉的基础VideoLLaMA2模型在各基准上都落后。
2、对象分支预训练是否重要:对象分支做预训练整体更优,说明Object像视觉Token 一样,需要先学基本语义再对齐文本。
3、Object Token数量:模型在达到最多64个Object Token往往最稳,过少信息不足、过多反而分散注意。
4、仅对象or仅视频:只用Object Token会损失背景与全局线索,性能低于双分支;但在某些偏对象细节的任务上,与仅视频分支相当,显示Object Token的关键信息密度。
5、流水线替换:RAM++自适应分段优于均匀/不分段;XMem跟踪略优于SAM2;不同提案/分段/跟踪组合均显著好于视频-only。
不过,团队也提到这项研究仍存在一定局限性:
至此小结一下,VideoOrion把“对象动态”当作视频语义的基本Token,在保证紧凑与可解释的同时,提高了对细节、交互与指代的把握能力。
团队表示,它不是替代视频特征,而是对象—场景双视角的结构化重写——一边看全局,一边抓关键。
这个范式或将影响后续的视频问答、检索、机器人感知与视频创作等多模态应用。
VideoOrion论文链接:
https://openaccess.thecvf.com/content/ICCV2025/papers/Feng_VideoOrion_Tokenizing_Object_Dynamics_in_Videos_ICCV_2025_paper.pdf
文章来自于“量子位”,作者 “北大&UCSD团队”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
