# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

Hi,早上好。
我是洛小山,和你聊聊 AI 应用的降本增效。
Ps. 本文涉及技术细节,适合 AI 应用产研阅读。
在 AI 产品从 Demo 走向商业化的过程中,每一位产品负责人都会经历大模型成本焦虑。
不知道你有没有这种感受?
我们总想为用户提供更好的 AI 服务,但在商业化层面,是和用户在对赌。
因为产品用得越好,用户用得越多,利润反而越薄。
看到消费账单的时候,不知道会不会窒息…
这么高额的 Token 费用,想优化提示词,但不知道还有哪些地方还能抠一点。
这篇文章是我对大模型成本管理的方法论,全是干货,欢迎看到最后。
这个方法论主要回答四个问题。
语法层:提示词里能压缩多少成本?
语义层:上下文有哪些优化空间?
架构层:KV Cache 藏着哪些坑?
输出层:输出长度有哪些优化点?

很多产品早期为了调试方便,或者单纯让自己看着舒服,亦或者我们找了 AI 帮忙,生成提示词。
AI 习惯用 ###、** 加粗重点,用 JSON 来展示数据结构。
虽然这样的形式对人类很友好。
但在大模型的计费逻辑里,这些都是词法税。
这么说你可能没啥感觉,我给你举个例子。
为了搞清楚这笔税有多重,我做了个 Token 可视化分析工具。
网址:yusuan.ai/analyzer
你也可以点击【查看原文】,跳转到网站测试。
也可以后台发送【预算】,获得网站与功能说明。
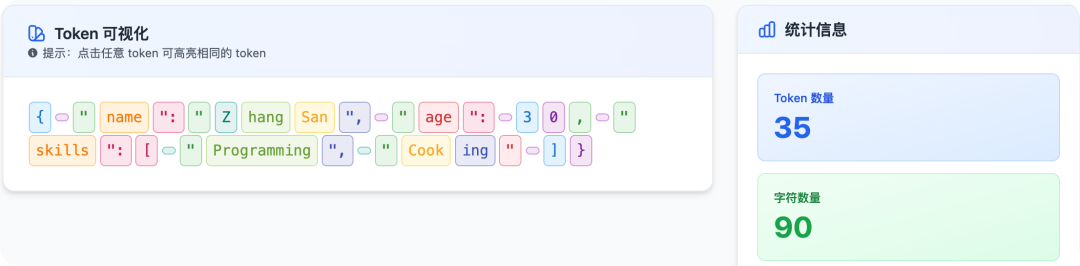
我把一小段提示词丢进去分析,结果是这样的…

我们付给模型厂商的每一分钱,买的应该是智能服务。
至于那些空格、回车、用来加粗的星号…
这些东西能省则省吧。就不应该花这些钱,对吧。
我下面这个提示词,是精简的 Lyra 提示词(翻译版)
光是加粗用的 ** 符号,就吃掉了 8.5% 的 Token。



吓人吗?这还只是加粗。
算上列表、标题等符号、以及 JSON 格式化带来的缩进换行…
这份提示词13% 都是格式性的提示词。


最终,我们的 Prompt 里可能有 10%-20% 都是这种装饰性的 Token。
你看,如果是千万级调用量下,每个月 20% 的预算,就这么花在让产品经理看起来容易一点上了。


所以这是我的第一个经验:
Prompt 是写给机器的指令,最终版本不需要美观,** 等格式只需用在需要强调的地方。
毕竟机器关注的是逻辑,而不是排版。
但除了砍装饰,结构化数据也得清理。
我总结了三条经验:

很多人习惯在 Prompt 里直接贴 JSON 格式的配置。
问题是 JSON 的信噪比太低,因为每个 Key 都要双引号包裹,每层嵌套都要花括号闭合。
而这些符号往往都是独立计费的。

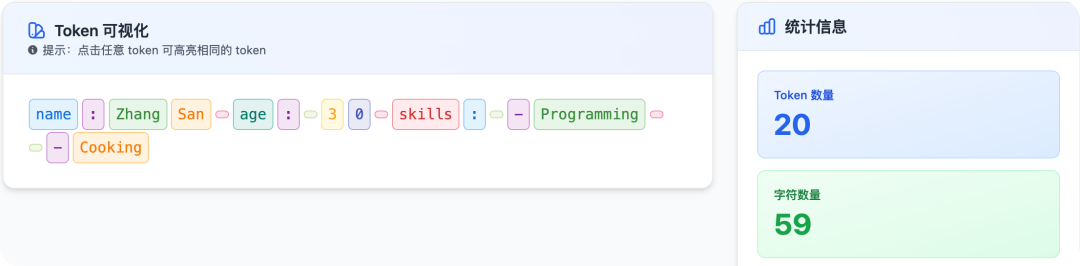
你可以考虑换成 YAML,或者 TOON 试试。
官网地址:yaml.org
YAML 用缩进代替闭合符号,用冒号代替"引号+冒号",不仅更符合自然语言阅读习惯,Token 消耗通常能省 10%-15%以上,多的能到 40%。

这是 RAG 场景的重灾区。
假设你从数据库捞了 50 条用户记录喂给模型,用 JSON 是这样的:
[
{"id":1,"name":"Alice","role":"Admin"},
{"id":2,"name":"Bob","role":"User"},
...
]

发现问题没?
id、name、role 这些字段名重复写了 50 遍!
这里就建议考虑换成带表头的格式:
id name role
1 Alice Admin
2 Bob User
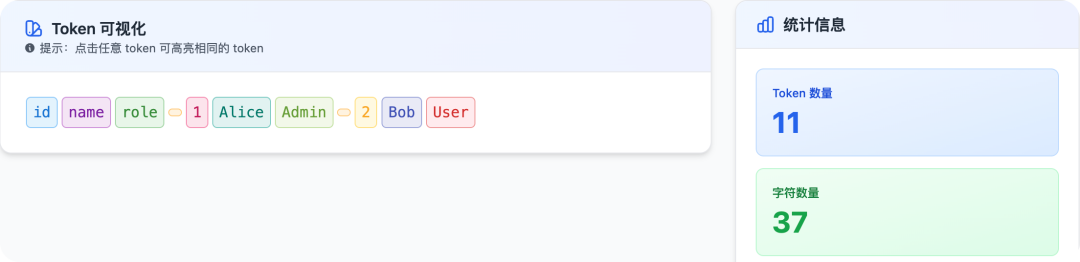
一下子把重复的键名全干掉了。
长列表场景能砍 30%-60% 的 Token,而且同样的 Context 窗口能放更多的数据。

TOON(Token-Oriented Object Notation)语法是专门为这个场景设计的格式,感兴趣可以搜一下。
https://github.com/toon-format/toon

不过我还是更推荐使用 YAML + CSV 的原因,是因为 TOON 作为新定义出来的格式,LLM 不一定支持得很好。
上面是基于输入的优化,但输出端的 Token 比输入端更贵,而且直接影响接口返回效率。
如果你是面向用户的流式输出,为了首字速度,格式宽松点可以接受。
但纯后台任务(提取标签、情感分析、数据清洗),其实是不需要任何排版的。
我的做法是在 System Prompt 里显式约束:输出必须是 Minified JSON,就是{"id":1,"status":"ok"}这种,不换行不缩进。
因为机器读数据不需要美观,只需要合法。

显式添加这样的约束之后,在批量处理的任务下面,能显著降低生成的耗时。


好,最后总结一下。
除了通过去掉排版用的 markdown 符号以外,不同的场景建议选择合适的数据结构,以尽量解约 Token 开销。

格式层的问题解决之后,我们再深入到上下文场景。
RAG 和长文档场景里,我见过最常见的工程错误:把上下文窗口当垃圾桶。
一堆 Few-Shot 案例、还有检索出来的 n 篇文档等等,全怼到上下文里,让模型自己辨识。
确实能用,但不该这样用。
因为这样做有两个问题:

第一,贵而且慢。
Transformer 的自注意力机制,计算复杂度是 O(N²)。
说人话就是:你的提示词长度翻倍,那么计算量翻四倍。
提示词越长,模型预处理的阶段耗时越久,首个 Token 延迟就越高。
当用户还没看到第一个字,耐心可能已经消磨没了。
第二,效果可能更差。
有效信息被废话淹没后,会产生中段迷失效应。
说白了就是:模型对 Prompt 中间部分的注意力最弱。
你可以把大模型的注意力想象成一个人在读长文章。
开头会认真看,因为要搞清楚「这是在讲什么」;结尾也会留意,因为知道「快结束了,该出结论了」。
但中间那一大坨?眼睛扫过去,脑子没过去。
大模型也是一样的。
Prompt 塞得越长,中间塞的信息越容易被「注意力稀释」。
你精心挑选的参考资料,如果不幸落在中段,模型可能根本没认真看。
所以,上下文不是越多越好。
关键信息要么放开头要么放结尾。
中间的位置,留给「丢了也不心疼」的内容。
参考 Claude 之前的研究,模型对 Prompt 中间部分的注意力最弱。
内容塞得越多,反而越抓不住重点。
https://research.trychroma.com/context-rot
对此,我的解法是双重蒸馏。

拿 Text-to-SQL 举例。
之前看到一个朋友写 SQL 的脚本,为了覆盖他们各种业务场景,很多人会在 Prompt 里写死 20 个 SQL 案例,加起来 4,000 多 Token。
然后每次用户提问,模型都要先复习一遍这 4,000 字,既烧 Token 又慢。

要不我们换个思路:
1. 把 20 个案例存进向量数据库
2. 用户问"上个月销售额”时,提前用语义检索,只捞 Top-3 个财务相关的案例
3. 最终 Prompt 从 4,000 Token 砍到 500

实测效果:Token 成本降 87.5%,响应速度快 3 倍以上。
而且因为去掉了无关案例的干扰,SQL 生成准确率反而更高了。

金融研报、会议纪要这类文档,充满正确的废话:免责声明、重复的背景介绍、口语化的垫话。
直接喂给 AI,等于花大成本请博士生帮你读垃圾邮件。

建议考虑在 RAG 检索后、送去推理之前,插一层 LLMLingua-2 中间件。
这东西并不是简单粗暴地砍词。
它用 BERT 的双向注意力机制,能同时看到上下文的前后,精准识别核心语义(实体、数据、关键动词),把冗余的噪音剔掉。

这个中间件能把文档压缩 5-20 倍。
原本需要 1 秒的预填充,压完后 50 毫秒搞定。
对高并发场景来说,吞吐量直接上一个量级。

因为高密度的提示词才能换来高质量的注意力。
别让用户在等待里流失。

在商业化产品的降本增效中,KV Cache 是我认为最被低估的技术点之一。
先说什么是 KV Cache。
我之前的推文提到过,大模型的本质是「Token 推 Token」的过程:它不关心你问的是什么问题,只关心前文是什么。点击这里查看原文
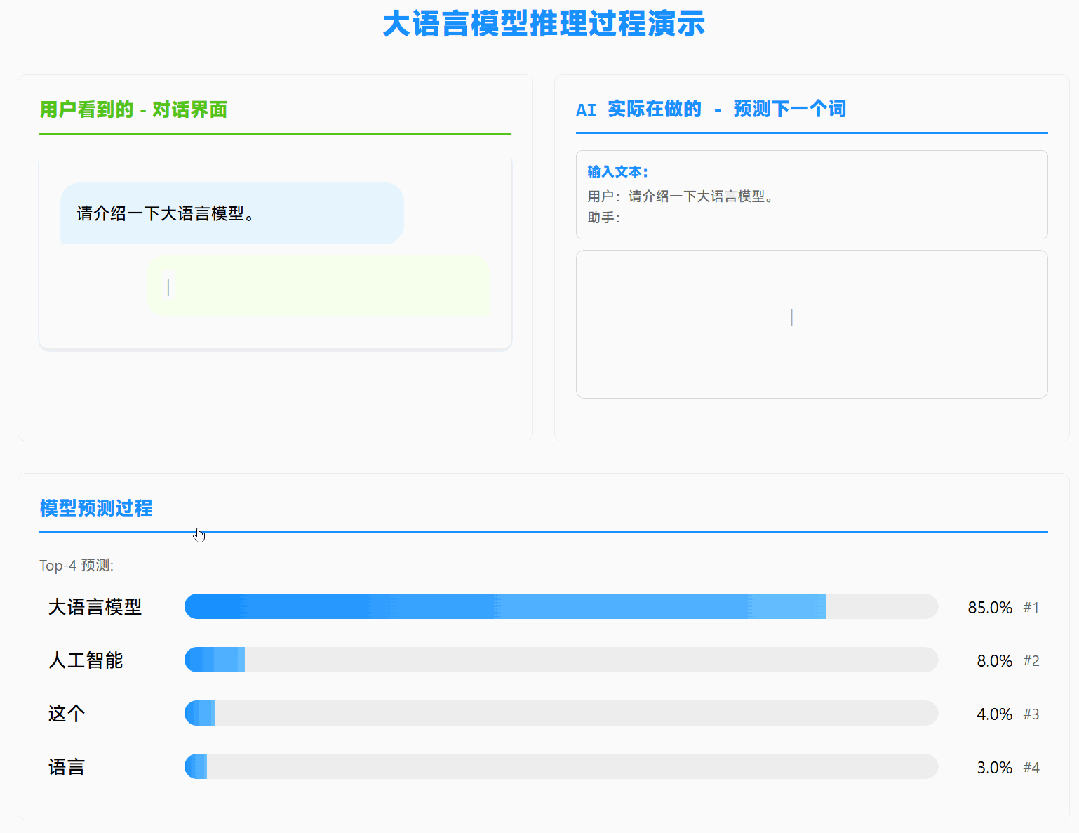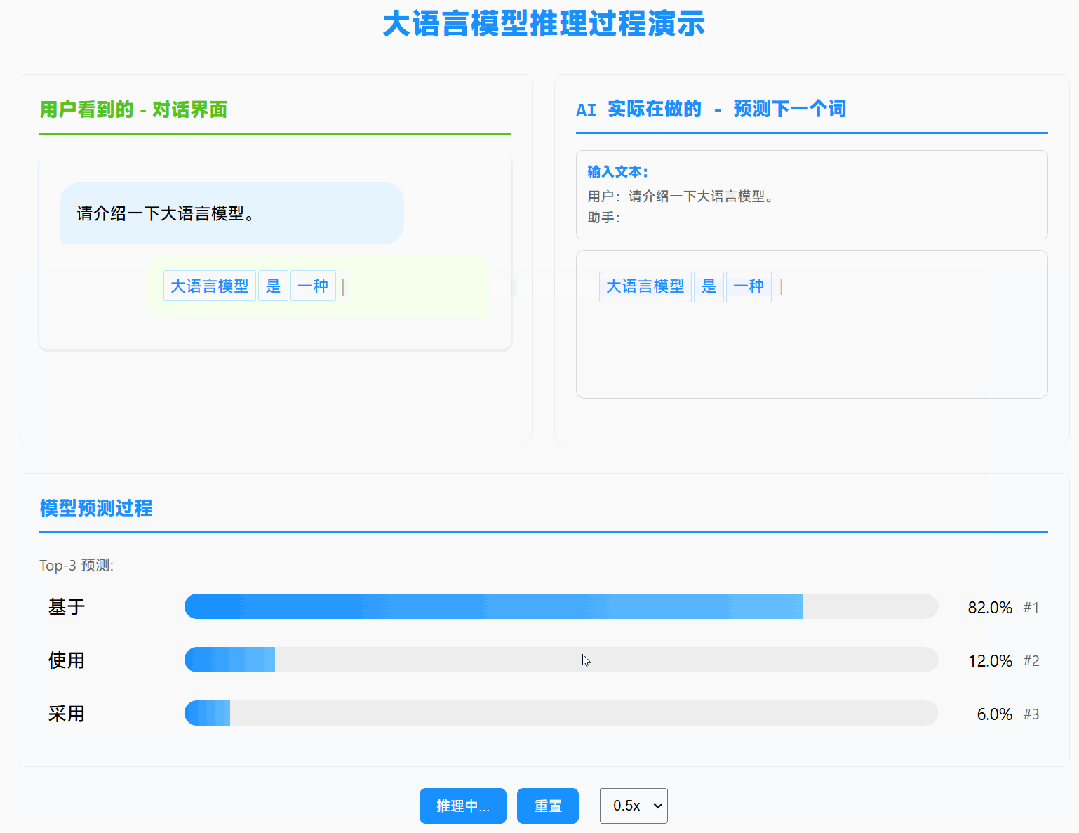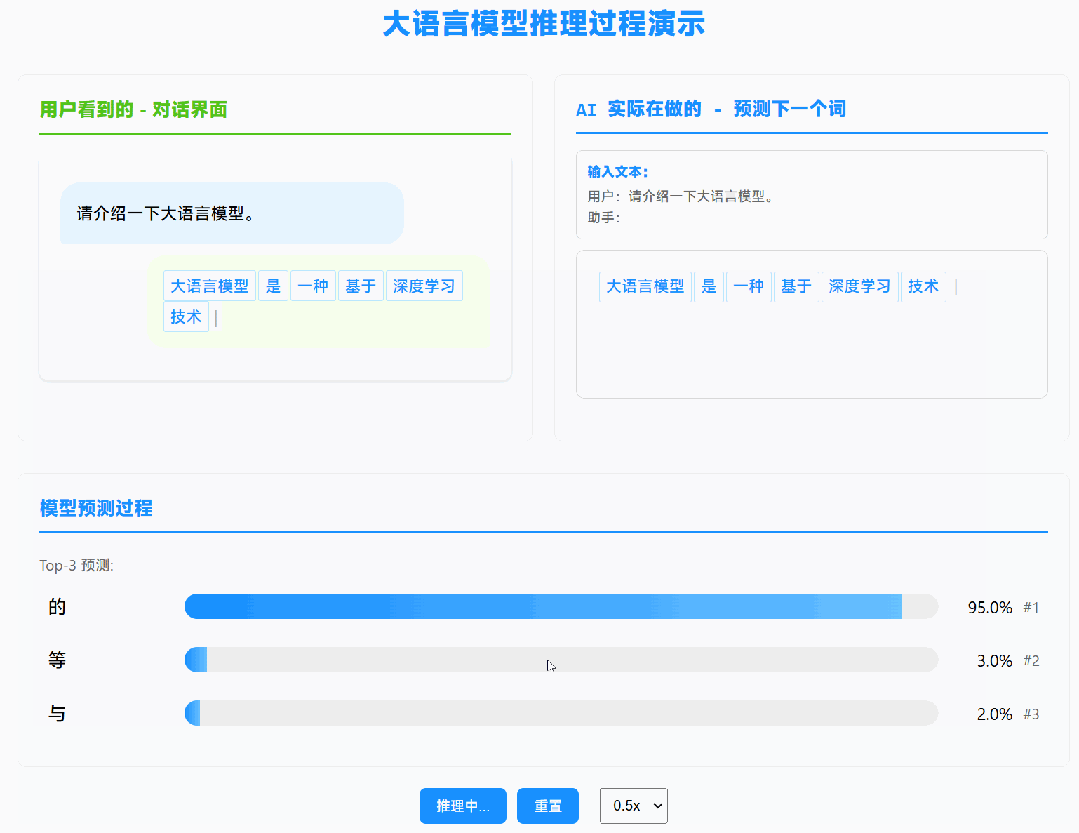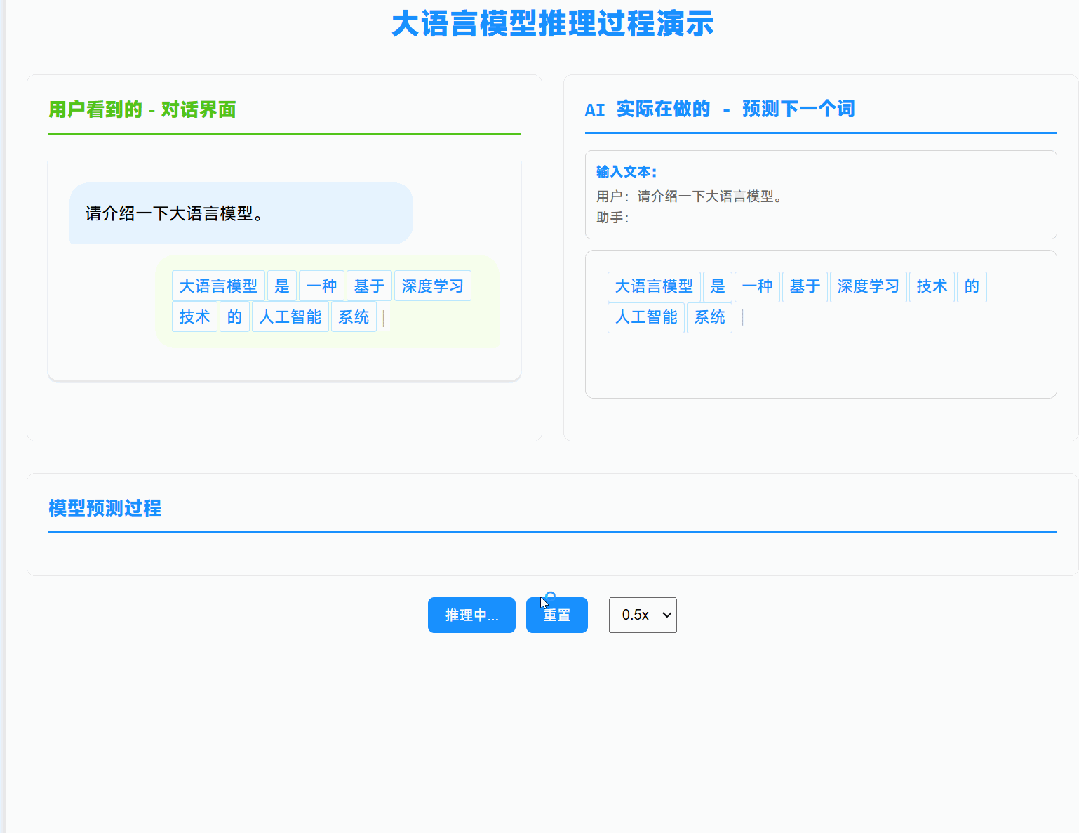
这意味着:如果两次对话的前缀相同,模型其实在重复计算同样的内容。
KV Cache 就是用来解决这个问题的。
我们可以把已经计算过的中间结果存下来,下次遇到相同前缀时直接复用。
本质上就是用更廉价的存储空间,换相对昂贵的实时计算。这就是「空间换时间」。
举个例子,
当你问大模型「2 + 4 = ?」,它算出 6。
如果你再问「3 + 4 = ?」,前缀变了,模型只能从头再算一遍。
但如果你问的是「2 + 4 + 1 = ?」
前缀「2 + 4」没变,模型就能直接从 6 开始,算出 7。
这就是 KV Cache 的核心机制:前缀匹配。
只要前缀不变,缓存就能命中。

命中缓存和没命中,最高能节省 90% 的成本。
比如下图是 DeepSeek 的报价。
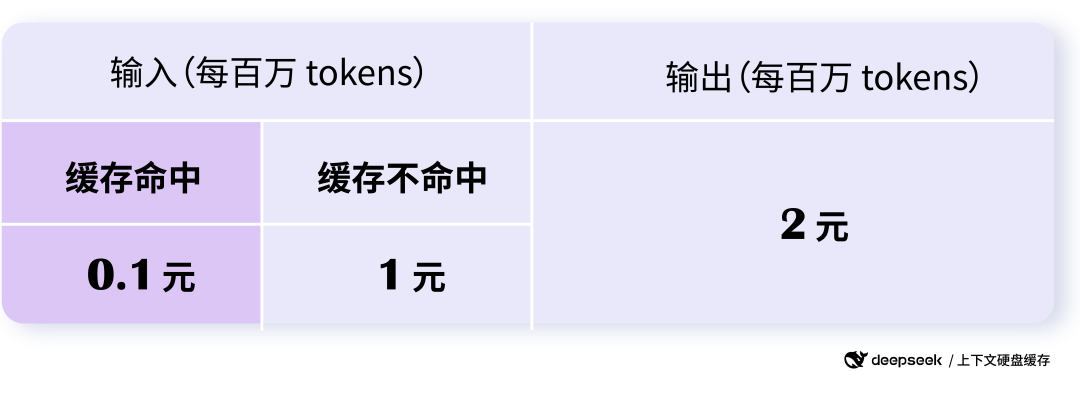
现在 DeepSeek、Qwen、智谱等主流模型都支持这个能力,以至于这是我在挑选大模型 API 时必看的一项。
虽然听起来诱人,但里面有几个隐形的坑,不说你可能不知道。
有些产品为了极致省钱,会根据用户意图动态挂载 AI 调用的工具:问天气就挂 WeatherTool,闲聊就不挂任何工具。
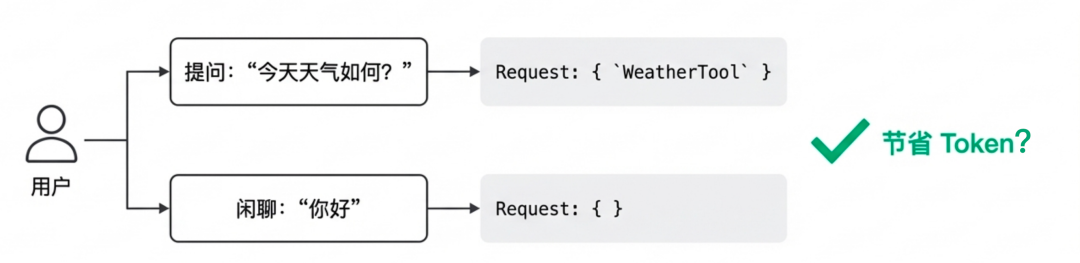
看起来很美好,节省 Token 美滋滋。
但实际上,这是大坑。
原因在于大模型后端的模板逻辑。
我以 Qwen 3 的提示词模板为例。

你看…
只要你在请求里带了 tools 参数,
AI 服务器后台会在 System Prompt 后面插入一段工具说明…

如果你的提示词没有 System Prompt,模板会自动帮你加一个System Prompt…
然后再插入工具说明。
这不就坑大了吗…
一旦工具状态变了(比如从有到无,或从 A 工具换成 B 工具),Prompt 的头部前缀就变了。
模型会认为这是一段全新的对话,之前缓存的 Token 瞬间灰飞烟灭…

所以我推荐的操作是:尽可能 System Prompt 保持不变 + 不用 Tools 字段。
或者宁可浪费点 Token ,把全量工具定义一直挂着,也要保住知识库的缓存命中。
因为 System Prompt 的稳定性比省那点 Token 重要得多。
大模型的上下文长度有限,多轮对话场景下,历史消息很容易撑爆窗口。
很多产品的做法是「滑动窗口」,就是只保留最近 10 轮对话,旧的直接丢掉。
这是偷懒,而且会出问题。
比如用户上传了一份 2 万字的合同,然后开始和 AI 逐段讨论、修改。
如果窗口只保留最近几轮,AI 会丢失对整份文档的理解,改到第三段时已经忘了第一段的上下文。
因为滑动窗口的本质是队列,先进先出。
用户前几个会话交代的重要背景(比如「我对花生过敏」),后面可能就因为窗口移动被切掉了。
结果就是间歇性失忆…
用户会觉得「这 AI 根本没在听我说话」。
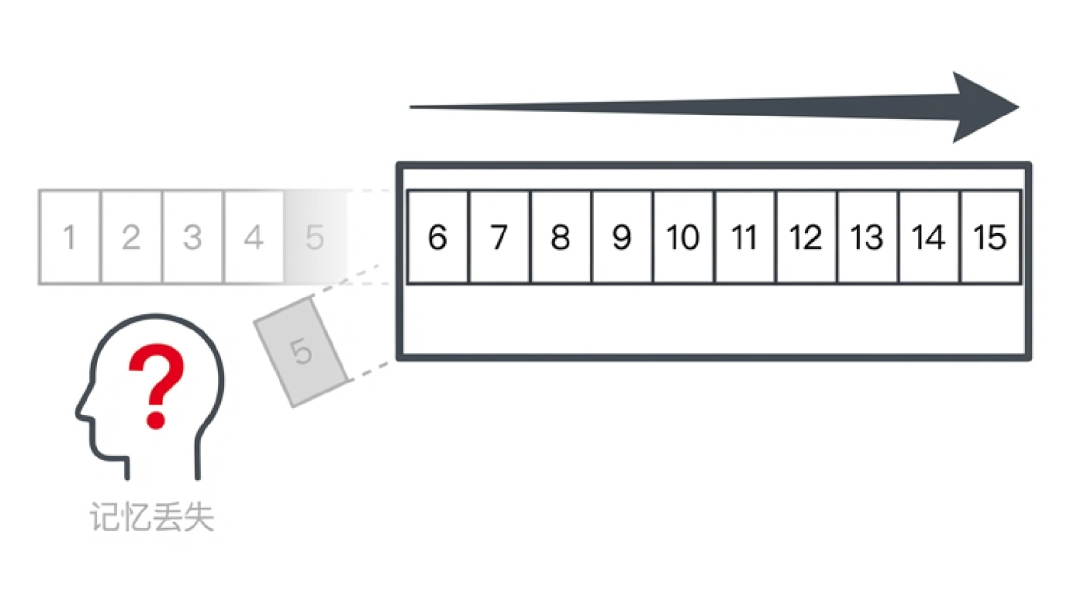
我更推荐的做法是「固定左侧,压缩后文」。

这样做的好处是:长期记忆有「索引」(压缩摘要),短期记忆有「高清」(完整对话)。

这样才能在质量和成本之间找到更合理的平衡点。
不过,前文里我们老盯着 Prompt 做优化,但说实话,真正费钱费时间的是输出。

为什么?
因为大模型的输入和输出,处理方式完全不同。
输入是并行的,一次性读完;输出是串行的,一个 Token 一个 Token 往外输出。
每多输出一个字,用户就多等十几毫秒,后台并发能力就降一分。

然后现在的模型都有个毛病:话痨。
好的,作为一个 AI 助手,我很高兴为您解答…
希望这段代码对您有帮助,如果有任何问题请随时…
这些是 RLHF 训练出来的「礼貌废话」,工程上叫 Yapping(唠叨)。
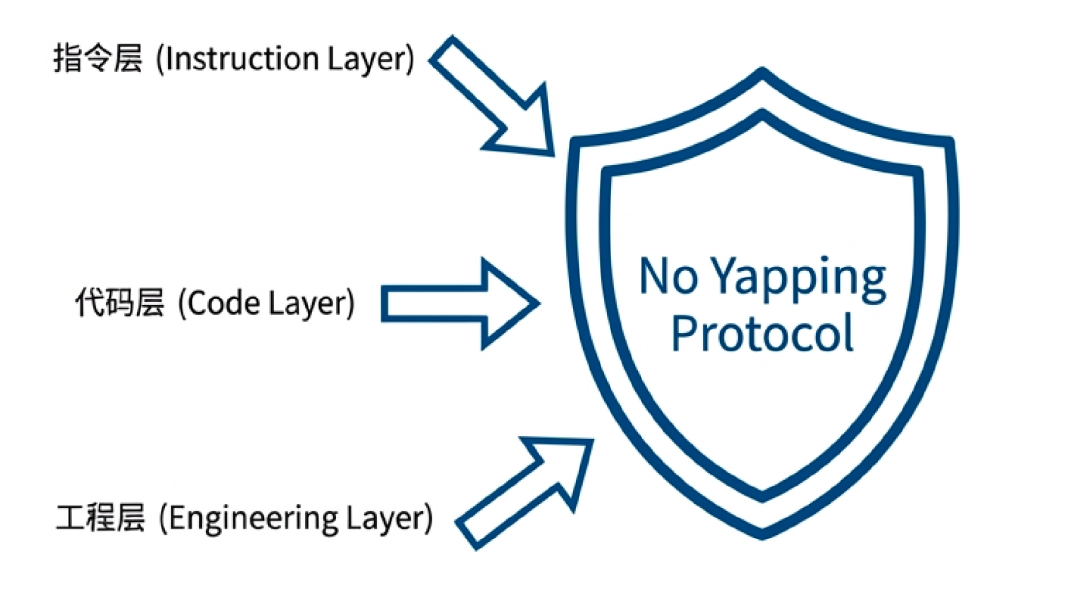
这真得治。

对于这个约束,也有三类合适的操作,分别是提示词层面,代码层面和工程化层面。
这个其实不是什么新技巧,很多产品经理都知道要求大模型直接给结果,或者尽量简洁回答。
但如果你的提示词里是:别写「请简洁回答」。
那是有问题的。
因为「简洁」对模型来说太抽象了,它不知道你要多简洁。
建议直接写「不要寒暄、不要总结、不要客套,直接输出结果」。

说白了就是告诉它:别整那些有的没的,直接上结果。
实测下来,Agentic 场景能砍掉 30% 的废话。

这是文字润色场景里最大的成本坑。
比如,用户说「把这句话改通顺一点」,模型直接把整篇 2,000 字的文章从头输出一遍。
或者约束一点之后,只生成这一个段落。
但不管怎么样,这些 Token 都是哗哗地烧。
换个思路,让模型只输出修改的部分,用 Diff 格式标出「原文→改后」,或者直接让 AI 返回正则表达式,程序拿到正则表达式之后再替换。
只动那两三个词,1 秒搞定。
成本差几十倍,用户体验还更好。
速度快,而且用户能直接看到改了哪里,不用自己去对比。

这招比在 Prompt 里写约束稳定得多,但同时也有一些风险。
你在 Prompt 里写「请只输出 3 项」,模型听不听是玄学。
它可能输出 3 项,也可能输出 5 项再加一段总结。
但停止序列是物理截断,和模型无关。
比如你让模型输出列表前 3 项,可以把「4.」设成停止序列。模型刚想往下写第 4 项,API 直接把生成流掐了。
然后不进历史上下文…
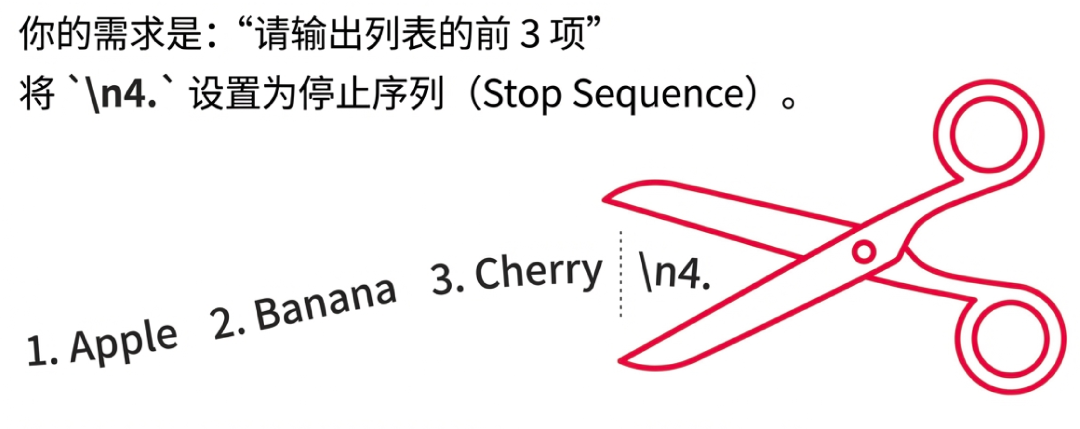
简单,粗暴,但好用。
同样的思路可以用在很多场景:
省 Token,省时间,还不用担心模型乱讲。
有效控制输出,就是控制成本和用户体验。
如果做完这几层优化,你基本上已经跑赢 90% 的粗放型 AI 产品了。
回顾一下,我们聊了 YAML 格式、压缩算法、KV Cache、停止序列…
看起来都是在省钱、抠成本。

但往深了想,省 Token 这件事,本质上是在提高信息密度。
过滤掉格式噪音、文档废话、重复计算之后,喂给模型的都是干货。
密度越高,注意力机制越不容易分散,幻觉也越少。
说白了,高信噪比 = 高智能。

还有个副产品:快。
Token 少了,首字出得快,端到端延迟短。
C 端产品里,这直接决定用户愿不愿意继续用。

下次审工程化方案时,可以用一个标准卡一卡:
这里的每一个 Token,都在为最终结果贡献价值吗?

如果不是,考虑把它干掉。
把算力留给真正的思考。
这,才是 AI 时代的精益计算的美学。
你们团队在 Token 成本优化上还踩过什么坑?
欢迎评论区聊聊,我会挑有价值的问题单独写一篇。
文章来自于“洛小山”,作者 “洛小山”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
