# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

本文为Milvus Week系列第一篇,该系列旨在分享Zilliz、Milvus在系统性能、索引算法和云原生架构上的创新与实践,以下是DAY1内容划重点:
- 传统JSON 格式数据处理效率与灵活性难以兼顾
- JSON Shredding 通过把高频键拆分为独立的类型化列,混合类型的键拆分为动态列,稀疏低频键汇总到共享键存储并配套建立倒排索引,做到了效率与灵活性兼备。
现代应用,从微服务到物联网设备再到以JSON output为标准配置的AI应用,都在源源不断地产生海量的 JSON 或类 JSON 格式的半结构化数据。
对此,传统的处理方式主要有两种:
1.完全解析成固定表:将所有可能的字段提前定义好。这虽然能获得不错的查询性能,但一旦数据格式发生变化,就需要繁琐的 DDL 变更,灵活性极差。
2.将整个 JSON 存储为单个字段(如 JSON 列)或者 使用Milvus 的 Dynamic Schema 功能:虽然增加了灵活性,但需要以牺牲一定的查询性能为代价。每次查询都需要在运行时解析 JSON,并进行全表扫描,当数据量庞大时,响应速度会急剧下降。
痛点一句话概括,就是灵活性与效率不能兼得。
那么有什么办法能够解决这个两难困境?
答案就是今天Milvus正式推出的JSON Shredding 功能,它能将无模式数据的灵活性与列式存储的查询性能完美结合,做到鱼与熊掌兼得。
JSON Shredding 的核心思路是 动态列式存储。它结合了 JSON Shredding 和 Shared Key Index 技术,整个过程对用户完全透明,你只需要正常插入 JSON 数据,系统会在背后自动完成所有繁重的工作。
其具体工作流程是:系统接收结构灵活的原始 JSON 记录,然后对其中的键做频率、类型稳定性、稀疏度的分析;接着将类型固定的高频键拆分为独立的类型化列,混合类型的键拆分为动态列,这两类数据都会存为Arrow/Parquet 列存格式;而稀疏低频键则汇总到共享键存储并配套建立倒排索引。
详情如下图所示:
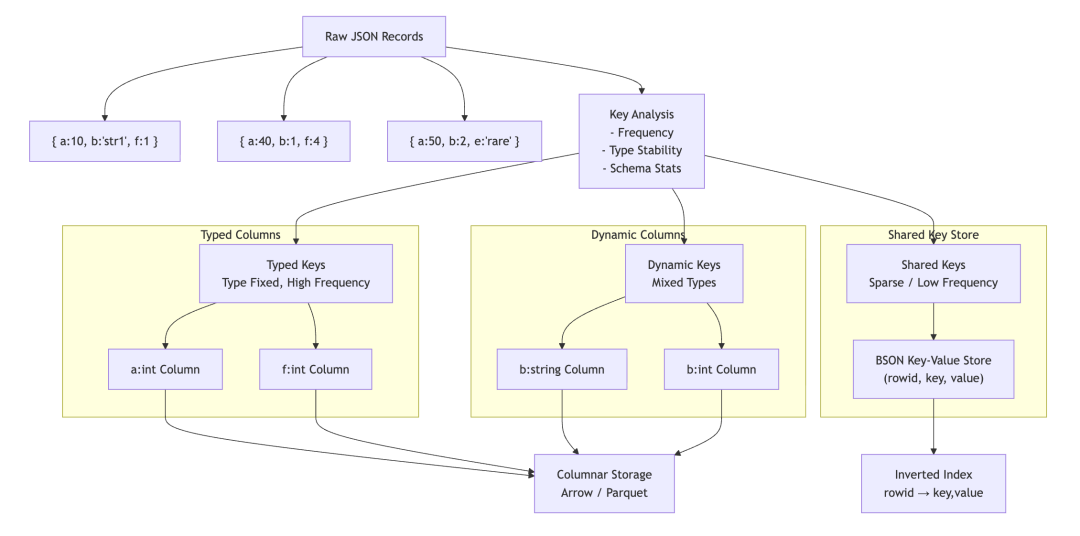
第一步:JSON 拆分与列化
这是JSON Shredding 的核心,是带来性能提升的关键。
当一个新的 JSON 文档被写入时,系统会将其拆分
第二步:动态列管理
这是实现灵活性的关键。
INTEGER, DOUBLE, VARCHAR 等),并为其选择高效的列式存储格式。第三步,优化查询
我们设计了一个基准测试,对比原生JSON与 JSON Shredding 在处理半结构化数据时的查询性能:
测试环境:
选取几个典型的场景
1.查询的key 可以被shredding 成单独列 (稠密数据)
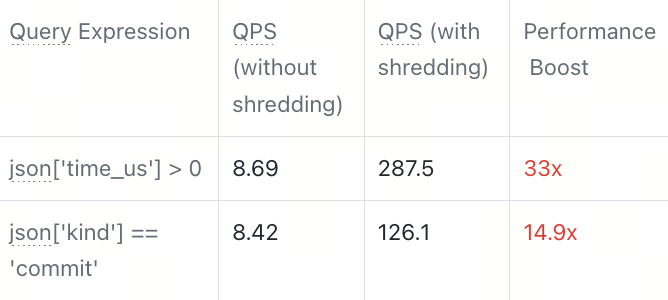
2.查询的key 没有shredding 成单独的列 (稀疏数据)

无论稀疏还是稠密的key 查询,得益于前面提到的优化方法,在shredding 的作用下都具有较大的性能提升。
无论面对的是 API 日志、物联网传感器数据,还是快速迭代的产品特性, JSON Shredding 功能都能为你提供“既要又要”的体验。
这项新功能现已上线,查看以下详细教程,即可开始使用。JSON Shredding | Milvus Documentation:https://milvus.io/docs/zh/json-shredding.md#Parameter-tuning

张露
Zilliz Staff Software Engineer
文章来自于“Zilliz”,作者 “张露”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
