# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Vision–Language–Action(VLA)策略正逐渐成为机器人迈向通用操作智能的重要技术路径:这类策略能够在统一模型内同时处理视觉感知、语言指令并生成连续控制信号。
然而,当前大多数 VLA 仍主要依赖模仿学习,实质上是按示范轨迹复刻,在分布发生偏移、任务形式变化或操作时域拉长时,极易出现误差累积并导致任务失败。强化学习(RL)从回报信号出发直接优化任务成功率,按理应当能够缓解这一目标错配问题,但在真实机器人上开展在线 RL 成本高昂,并行执行受限,还伴随大量重置与标注开销;以 π*0.6 为代表的多轮离线 RL 范式在每一轮中仍高度依赖真实系统部署和人工干预,训练成本与迭代效率都存在明显瓶颈(需要一直有人类介入,一旦出现错误轨迹就人类接管操作,记录相应的数据);另一方面,基于传统物理引擎(MuJoCo、Isaac sim)的强化学习又难以同时兼顾逼真度、场景多样性与工程可用性。
针对上述问题,研究团队提出 ProphRL 框架:采用大规模预训练的世界模型 Prophet 作为「面向真实环境」的视频级模拟器,并配合专为流式动作头设计的在线 RL 算法 Flow-Action-GRPO 与 FlowScale,在虚拟但物理一致的环境中直接对 VLA 策略进行强化学习优化,再将优化后的策略部署到真实机器人上。如此,策略改进的主要探索过程可以在世界模型中完成,在兼顾物理可信度的同时显著降低真实交互成本,为大模型 VLA 的实际落地提供了更可行的技术路径。如图所示:

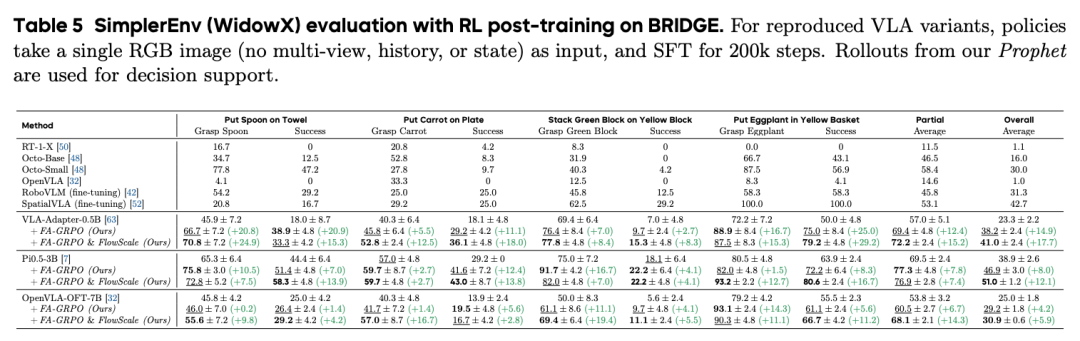
实验结果显示,ProphRL 在多个公开基准上为各类 VLA 模型(VLA-adapter-0.5B, Pi0.5-3B, OpenVLA-OFT-7B)带来 5–17% 的成功率提升,在真实机器人实验中进一步取得 24–30% 的大幅度成功率提升。

近年的工作表明,VLA 在自然语言指令和视觉观测的驱动下,已经可以完成台面整理、物体抓取、工具操作等多步任务。但绝大多数方法仍依赖行为克隆式监督训练,只关心轨迹像不像示范,并未真正对齐任务最终是否成功。因此,模型在训练分布附近表现良好,一旦场景略有变化或操作链条变长,就容易因误差累积而导致失败。
从原理上看,为 VLA 叠加一个 RL 模块,让策略通过在线交互从成功或失败中学习,是缓解上述错配的自然途径。但在真实机器人上实践 RL 成本极高:每次试验都消耗时间和硬件寿命,需要严格的安全防护和人工监控,多机器人并行基础设施投入也非常大,许多精细任务还依赖人工重置与干预。综合来看,直接在真机上大规模跑 RL 并不现实。
另一条路线是依托 MuJoCo、Isaac sim 等物理引擎,在仿真环境中完成 RL,再做 sim-to-real 迁移。然而,对以 RGB 图像为输入的 VLA 而言,要搭建一个同时兼顾视觉逼真度、接触动力学精度和物体多样性的仿真场景,工程成本极高,且仍难以准确覆盖如布料折叠、纸巾拉取等复杂任务。这使得基于传统仿真器的大规模 VLA 后训练在实际中难以落地。
近年来,数据驱动世界模型开始在机器人领域兴起:给定初始图像和底层机械臂动作指令,模型可以预测未来机械臂操作视频,从而在「想象空间」里让策略反复练习。这类方法天然与 VLA 的视觉接口兼容,有望成为连接 RL 与真实世界的新桥梁。但现有世界模型通常局限于单场景或单任务,跨数据集、跨机器人形态的泛化能力有限;与 VLA 结合时,世界模型也多被当作简单的数据增强来支撑 SFT,而尚未形成一个可迁移、可适配、能够真正支撑 RL 的通用模拟器。

研究团队构建的世界模型 Prophet,目标是在统一接口下学习从动作序列到未来操作视频的映射。其核心结构是视频扩散模型,在推理时输入历史帧、当前参考帧,以及未来一段时间的动作序列,输出与真实机器人执行过程对齐的长时操作视频。为更好地对齐动作与几何信息,研究团队采用双重动作条件:一方面将共 7 维的末端执行器位姿增量和夹爪开合编码为全局标量嵌入;另一方面将末端执行器动作投影到相机平面,并渲染为动作帧,为模型提供显式位姿与运动方向线索。此外,研究团队引入 FramePack 式的历史记忆机制,在控制计算成本的同时,持续追踪接触过程中的几何一致性和物体状态演化。
为了让 Prophet 具备通用机器人直觉,研究团队在 AgiBot、DROID、LIBERO 以及筛选后的 Open-X 等多源数据上进行统一预训练,覆盖多种机械臂、视角、场景和操作风格。训练时,对坐标系、夹爪语义和动作参数化进行统一建模,避免不同数据源之间的结构冲突。在此基础上,面对新场景、新物体或新任务时,只需百级别真实轨迹,通过 快速且轻量的微调,即可让 Prophet 快速适配,同时保持对符合真实世界物理结果生成能力的延续。

以下两个视频为 Prophet 的交互 demo,通过选择具体动作,生成对应动作的视频:


传统视频生成评估指标(PSNR、SSIM 等)主要衡量画面清晰度和逼真度,却难以判断机器人有没有按预期动作。为此,研究团队提出光流引导的评估协议:在真实视频与 Prophet 生成视频之间计算像素级光流,并对比两组光流之间的一致性,以外观无关的方式评估末端轨迹和接触行为是否对齐。该指标与感知质量互为补充,为在世界模型中开展 RL 提供了更贴近控制需求的反馈信号。
在策略层面,研究团队面向带 flow-based 动作头的 VLA,这类策略通过多步去噪生成连续动作,内部包含大量中间流步。现有 Flow-GRPO 将每个流步都当作独立动作,既放大了梯度方差,也削弱了与环境反馈之间的对应关系,训练容易不稳定。为此,研究团队做了两点改进:
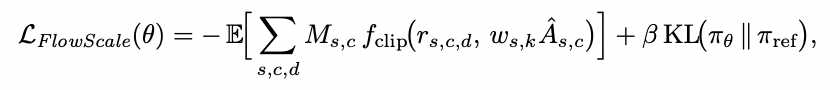
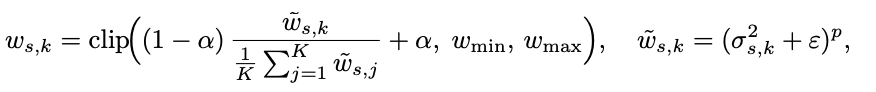
结合 Prophet 提供的长视野视频模拟器,VLA 策略在其中用 FA-GRPO 和 FlowScale 反复训练,再迁移到真实机器人上执行,形成「在想象中学,在现实中用」的完整闭环。
在 ProphRL 中,奖励不再依赖手工设计的几何距离,而是由 视觉–语言奖励模型(Reward model) 直接根据「整条轨迹是否完成任务」给分。具体来说,reward model 以任务文本和整段执行视频为输入,输出一个标量得分,并在一个 batch 内做归一化后,作为整条轨迹上各步的 advantage,送入 FA-GRPO 和 FlowScale。
最终,世界模型、VLA 基座模型、奖励模型,通过在线强化学习(FA-GRPO & FlowScale)构成数据闭环,为具身场景落地提供切实可行的解决方案。如下图所示:

在实验部分,研究团队围绕三个维度系统评估 ProphRL:
世界模型能力:在 AgiBot、DROID、LIBERO 和 BRIDGE 等多数据集上,预训练的 Prophet 就能在视觉效果和动作一致性上同时取得领先表现,其中 BRIDGE 在预训练阶段是完全未参与的数据集。在 BRIDGE 少样本场景中,经过少量示范的微调后,Prophet 依然可以执行视觉上未出现过的新物体、新组合动作,体现出良好的跨场景、跨物体泛化能力。
生成质量超越 Nvidia 的 Cosmos 与上海智元的 Genie-envisioner:



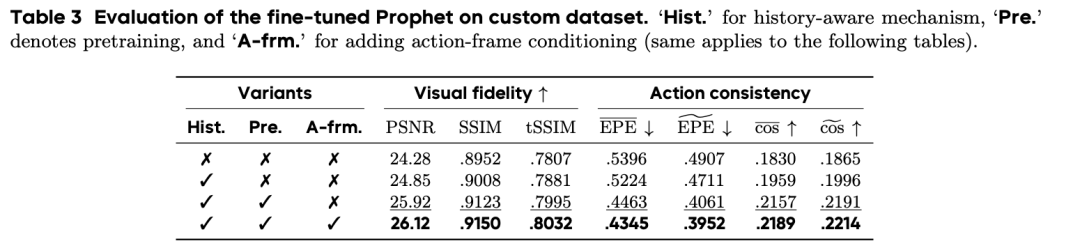
在世界模型中的 RL 效果:研究团队选取多种 VLA 模型(如 VLA-Adapter-0.5B、Pi 0.5-3b、OpenVLA-OFT-7B ),在 Prophet 中对每个任务分别进行强化学习训练。对比仅做监督微调,加入 FA-GRPO + FlowScale 后,在多项 benchmark 与真实任务中成功率都有显著提升。
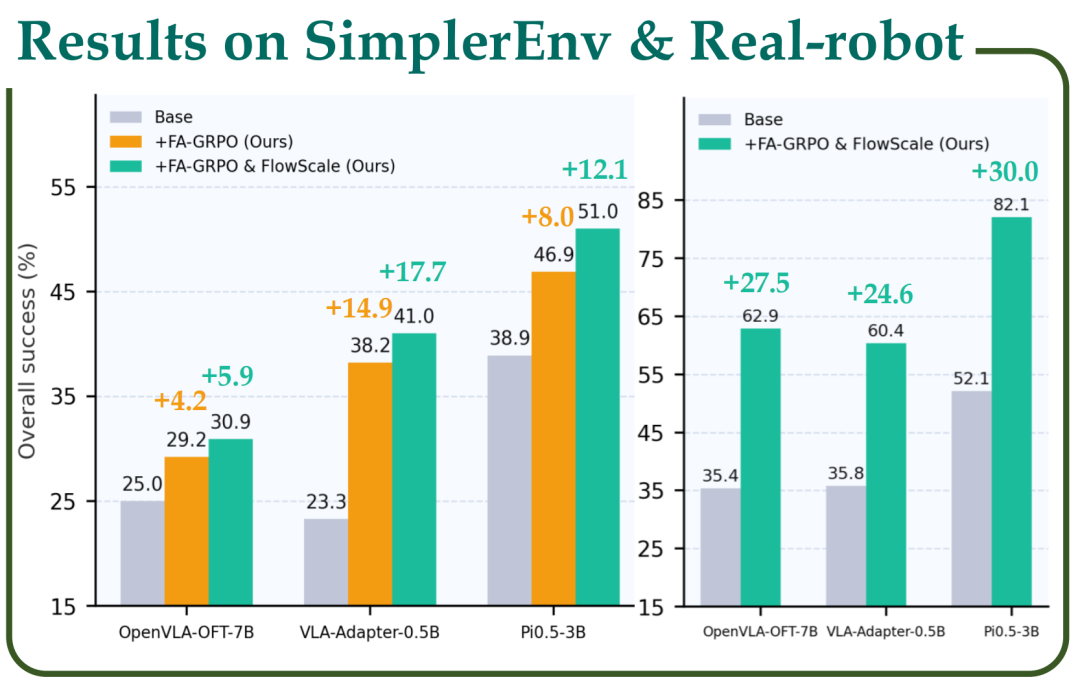
真实机器人上的验证:基于 UR30e 机械臂,研究团队设计了 GraspBottle、PlaceCube、PulloutTissue、PlaceBowl 四个桌面操作任务,覆盖刚体抓取、容器放置和柔性物体拉取等难以精确仿真的场景。将 Prophet 中训练得到的策略迁移到真机后,ProphRL 相比纯监督微调在所有任务的平均成功率上都带来约 24–30% 的成功率提升。

VLA 或者 VLA + SFT 后训练 在做的其实是 imitate 训练数据集,而 世界模型 + RL 能够学习并加强到训练数据中不存在或者弱存在的成功轨迹,如下视频所示:


总的来看,目前机器人策略仍以基于示范的监督微调(SFT)为主,在分布偏移和长时序任务下往往难以保持稳定表现,而强化学习则是提升鲁棒性和适应能力的关键手段。
不过,以 Pi*0.6 为代表的多轮离线 RL 范式在每一轮中仍高度依赖真实系统部署和人工干预,训练成本与迭代效率都存在明显瓶颈。
ProphRL 以世界模型 Prophet 为核心,先在大规模真实轨迹上学习从动作到未来观测的动力学,再在这一数据驱动的模拟环境中对 VLA 策略执行 RL 优化,最后将策略迁移到真实机器人上进行验证。
这样的设计使得策略改进的主要探索过程可以在世界模型中完成,在兼顾物理一致性的同时减少对真机交互的依赖,并在实验中对多类 VLA 模型中带来了稳定且显著的性能提升,表明「世界模型 + RL」让具身智能在真实场景中落地可期!
文章来自于“机器之心”,作者 “张家辉、张力”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
