# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2025就要过去了。UC Berkeley、Stanford和IBM联手做了一件大事。他们调研了306份在一线“造 Agent”的从业者问卷,并深度访谈了20个已经成功落地并产生价值的一线企业案例(涵盖金融、科技、医疗等领域)。试图回答一个最朴素的工程问题:一个能用的、赚钱的Agent,到底是用什么架构搭出来的?

这篇名为 《Measuring Agents in Production》 的论文,是一份来自学术+工业界的“诚实报告”。它可能会打破您对Agent的很多幻想,但能给您指一条真正通往落地的路。
企业费尽周折开发Agent,到底图什么?
数据非常直观。在那些已经将Agent上线的团队中,72.7%的人表示,首要动机是“提高生产力”(Increasing Productivity)。紧随其后的是“减少人工工时”(63.6%)和“自动化常规劳动”(50.0%)。
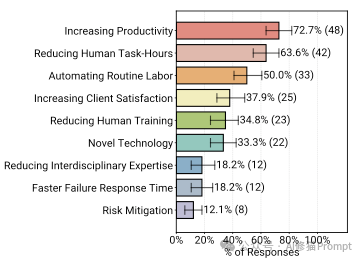
相比之下,那些听起来很高级的理由,比如“风险缓解”(12.1%)或“快速故障响应”(18.2%),并不是企业采用Agent的主要动力。
现实是:企业引入Agent,主要是为了帮人干脏活、累活,或者是解决人手不足的问题。
您可能认为Agent主要是在帮程序员写代码,但调查结果让人意外。虽然“技术”领域确实占了一席之地(24.6%),但占比最高的是“金融与银行业” (39.1%)。
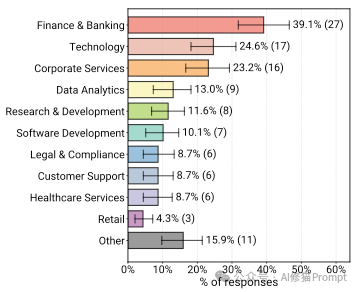
Agent的身影已经遍布了26个不同的领域,包括:
这一点非常关键。92.5%的生产级Agent是直接服务于人类用户的,而不是服务于其他机器或软件系统。
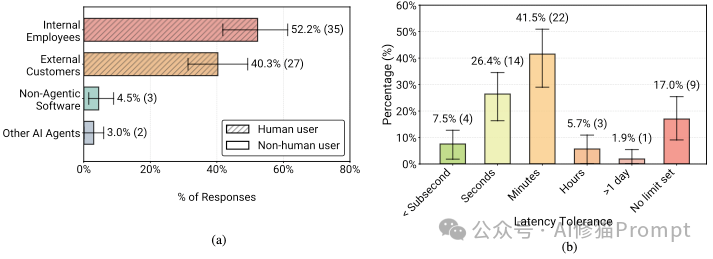
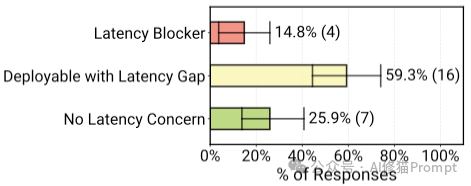
(a) 用户类型:92.5% 的 Agent 服务于人类用户(内部员工+外部客户),只有极少数服务于其他软件。(b) 延迟容忍度:绝大多数系统允许“分钟级” (41.5%) 的响应时间,只有7.5%要求亚秒级响应。
这也解释了为什么Agent能落地:它们并不是完全替代人,而是作为“工具”增强人的能力。人类用户本身就是最后一道防线。
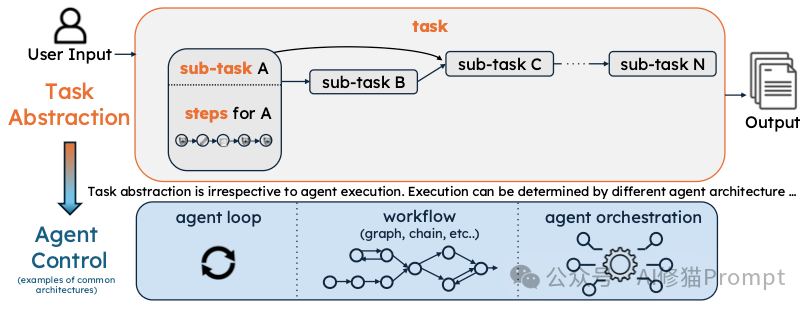
这是论文最硬核、也最颠覆认知的部分。学术界推崇的“全自动、自我进化、复杂规划”在工业界几乎没人用。
工业界的信条是:简单、可控、有效。
尽管开源社区非常活跃,但在真正的生产环境中,企业做出了非常现实的选择。
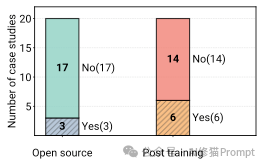
左图:17个案例使用闭源模型(No Open Source),只有3个用开源。右图:14个案例没有进行后训练(Post-training/Fine-tuning),直接用现成模型。
这可能违背了很多人的直觉。我们常以为要把Agent做好,必须得用私有数据去微调(Fine-tuning)模型。但事实是:
那么,怎么让模型听话呢?靠Prompt Engineering(提示工程)。
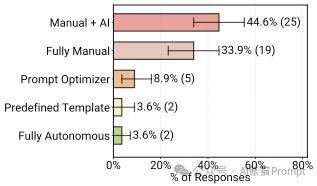
在学术论文里,Agent通常是“这就给你解决问题”,然后自己去思考步骤。但在公司里,Agent是被“管”得死死的。

Agent核心组件配置:(a) 模型数量:大多数Agent只用1-2个模型。(b) Prompt 长度:存在一个“长尾”,有12%的Prompt超过了1万个token。(c) 自主步骤:46.7%的Agent只能自主执行1-4步。这张图是论文核心观点“Reliability Through Constrained Deployment”(通过受限部署实现可靠性)的最有力数据支撑,Agent不是无限思考的,而是被限制在很短的步骤内。
这是一个非常有趣的“罗生门”现象。
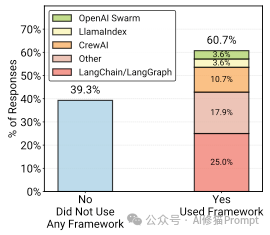
为什么高手都不用框架?原因: 框架太重、抽象层太厚,难以调试,比如Langchain的源代码就有一万多行。为了控制力和稳定性,工程师宁愿自己写简单的循环代码。
何况LLM框架本质上就是一个简单的有向图,这一观点出自Pocket Flow的作者Zachary Huang博士,感兴趣您可以看下:

软件工程里我们有单元测试,但在Agent开发中,评估(Evaluation)是一个巨大的痛点。

(a) 基线对比:61.3% 的团队没有进行基线对比。(b) 评估方法:74.2%依靠人工(Human-in-the-loop),51.6%使用 LLM-as-a-judge。(c) 共现矩阵:显示了不同评估方法的重叠,人工评估是连接所有方法的中心。
如果不知道 Agent 对不对,怎么敢上线?
1. 没有任何公开基准能用
2. “LLM-as-a-judge” 的真实用法
当问到“开发Agent最难的是什么”时,“可靠性” (Reliability)毫无悬念地排在第一位。
传统的软件,Bug是可复现的。Agent的Bug是随机的。
这可能是另一个反直觉的发现。
我们常认为安全就是“把Agent关在沙盒里”。但这远远不够,因为Agent必须接触企业的核心数据。
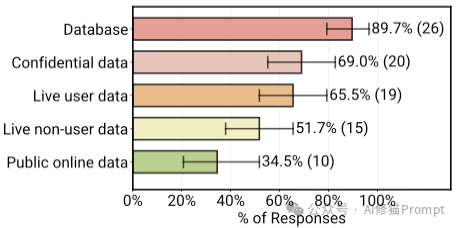
虽然目前的Agent大多是“聊天机器人”的形态,但论文中的数据预示了未来的进化方向。
读完这篇论文,我们可以勾勒出当前工业界AI Agent的真实画像:
它们不是科幻电影里全知全能的超级AI,而是被工程师们用无数规则、人工审核、特定流程以及法律合同“精心包裹”起来的实用工具。
研究者将这种模式总结为:“通过受限部署实现可靠性” (Reliability Through Constrained Deployment)。
如果您正准备开发Agent,这篇论文给了您几条非常务实的建议:
AI Agent的时代确实已经到来,但它不是以“魔法”的形式,而是以“工程”的形式,一步一个脚印地走进我们的生产环境。
文章来自于“AI修猫Prompt”,作者 “AI修猫Prompt”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
