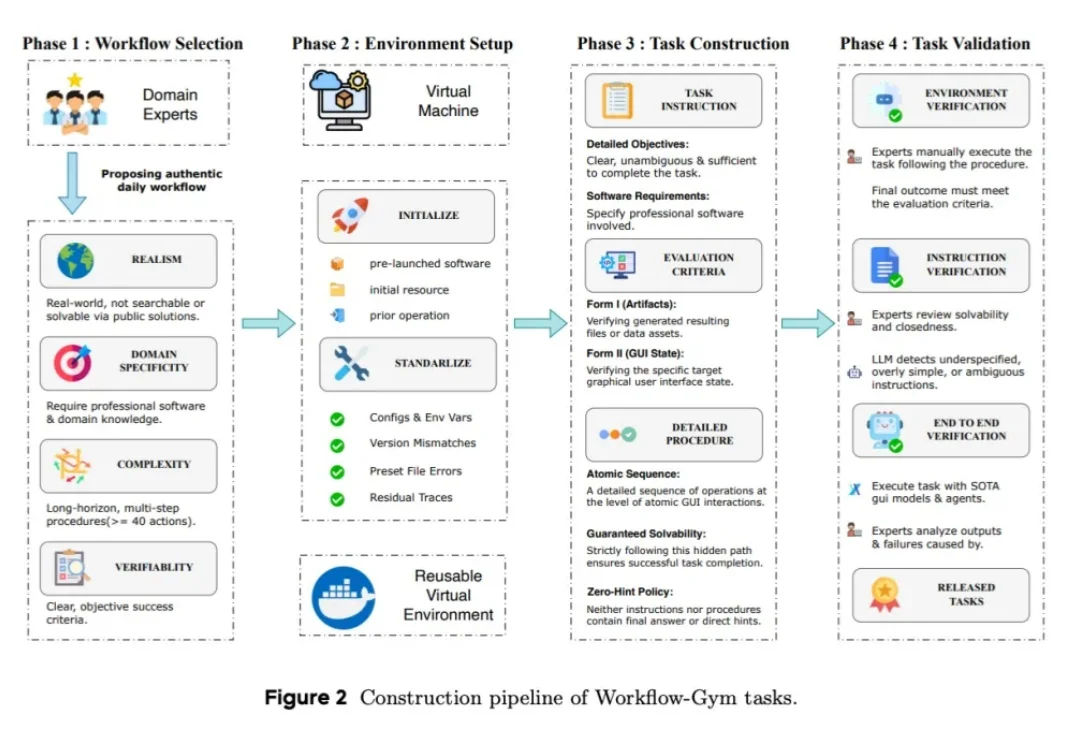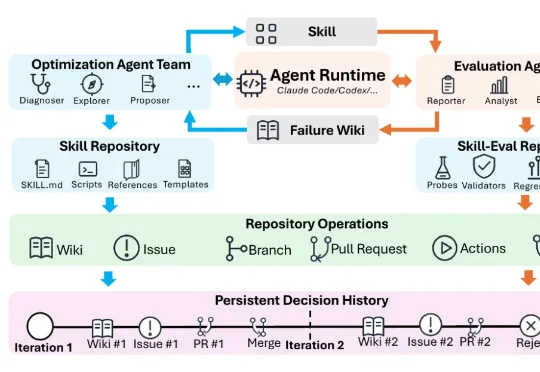
一个Skill为什么越改越好?腾讯SkillHone让Agent记住每次优化决策
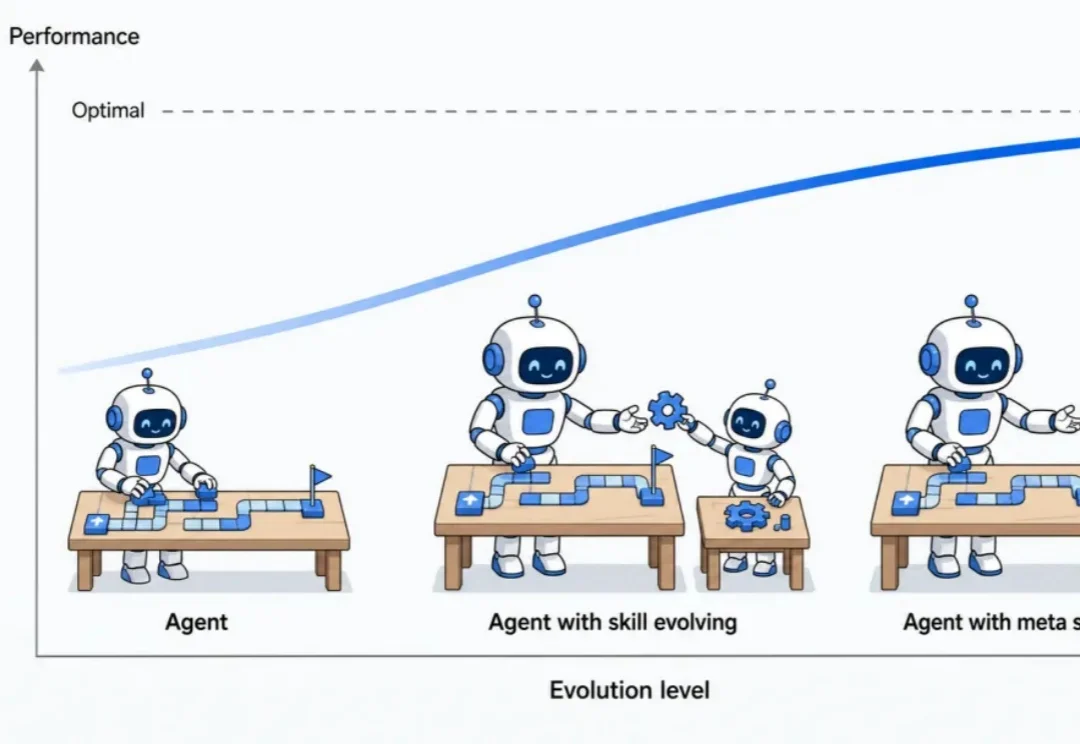
一个Skill为什么越改越好?腾讯SkillHone让Agent记住每次优化决策腾讯微信在论文 SkillHone 中,将这个问题归结为优化历史丢失,进而提出了面向持续 Skill 进化的开发框架。 SkillHone 把每轮诊断、候选修改、评估证据和最终决定组织成持久决策历史。同时,持续优化的对象也从单一的 SKILL.md 文件扩展到了整个 Skill 文件夹及其修改过程。
来自主题: AI技术研报
8055 点击 2026-07-24 15:56