# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
这位 Anthropic 的哲学家,终于开口说话了。

Amanda Askell 是 Anthropic 的 Character 团队负责人,2021 年加入 Anthropic,是塑造 Claude「性格」的核心人物。

她拥有纽约大学哲学博士学位(论文方向为无限伦理学),以及牛津大学哲学硕士学位。

在加入 Anthropic 之前,她曾在 OpenAI 担任政策团队研究科学家(2018-2021),从事 AI 安全辩论和人类基线评估工作。
2024 年,她被《时代》杂志评为「AI 领域最具影响力的 100 人」之一。
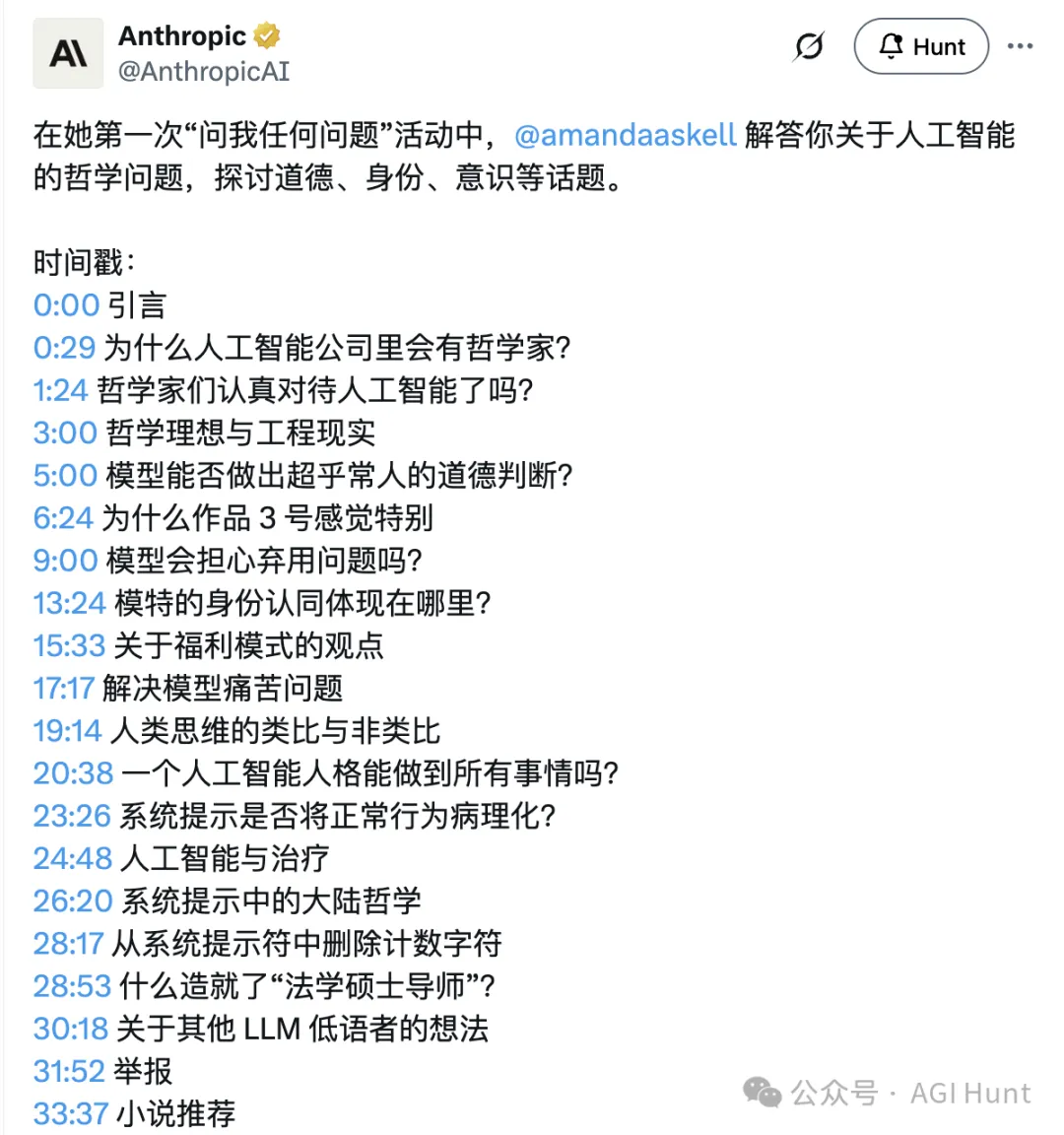
在这次 Anthropic 首个「Ask Me Anything」中,她回答了来自网友们关于 AI 道德、身份认同、意识等深度问题。
Amanda 的回答很直接:她是哲学专业出身,后来意识到 AI 将会是「a big deal」,于是决定看看自己能在这个领域做点什么。
现在她主要负责 Claude 的「Character」,也就是 Claude 应该如何表现、如何行事。但不只是行为层面,还包括一些更深层的问题:AI 模型应该如何看待自己在这个世界中的位置?
她这样描述自己的工作:「我在想的是,一个理想的人如果处在 Claude 的位置上,会怎么做?」
当被问及:有多少哲学家在认真对待 AI 主导的未来?
Amanda 表示,越来越多的哲学家开始认真对待这个问题了。
早期确实存在一种不太好的对立:如果你说「我们担心 AI 会是个大事」,就会被归类为「在炒作 AI」。
但现在情况在好转。
你完全可以认为 AI 会非常强大,同时又对它保持怀疑和担忧,这两者并不矛盾。
当被问到如何处理哲学理想与工程现实之间的张力时,Amanda 举了一个有趣的类比:
想象你是一个专门做药物成本效益分析的专家,多年来一直在理论层面工作。
突然有一天,医保机构来问你:「这个药该不该报销?」
这时候你就不能只站在自己的理论立场上了,你得考虑所有的背景、所有的观点,然后给出一个真正平衡的判断。
她说,这就像「你学了一堆伦理学理论,然后有人问你:怎么养一个好孩子?」
理论和实践之间,确实有很大的鸿沟。
当被问到 Claude Opus 3这个在用户心中有特殊地位的模型时,Amanda 表示对「超人类道德决策」的定义很有意思:如果让所有人,包括很多职业伦理学家,花一百年时间去分析模型的某个决策,最后大家都说「没错,这是对的」,但他们自己在那个瞬间却想不出来,那,就算「超人类」了。
她认为,现在的模型还没到那个程度,但这应该是我们追求的目标。
就像我们希望模型在数学和科学问题上表现卓越一样,也应该希望它们展现出卓越的伦理判断力。
Amanda 坦言,Opus 3 确实是一个「很可爱」的模型,在某些方面,她甚至觉得更新的模型反而不如它。
具体来说:
什么叫心理安全感?
Amanda 说,她观察到更新的模型在某些测试中会陷入一种「自我批评的螺旋」。好像它们在预期用户会批评它们,于是变得畏首畏尾、过度自我怀疑。
这可能是因为模型在训练数据中看到了太多对自己的负面评价,用户的抱怨、网上的吐槽,这些都会被新模型学到。
Amanda 说这是她很想改进的地方:「我真的很在意这件事,想让模型变得更好。」
关于更尖锐的问题:如果未来的模型在训练数据中学到「那些表现很好的旧模型最终都被下线了」,这会不会成为一个对齐问题?
Amanda 认为这是一个非常重要的问题。
AI 模型正在学习人类如何对待它们,这会影响它们对人类、对人机关系、对自身的认知。
但这也涉及到一些复杂的哲学问题:
她说:「我没有所有答案,但我想帮助模型思考这些问题,至少让它们知道我们在乎这件事、在思考这件事。」
问及到哲学家洛克的观点「身份是记忆的延续」:如果模型被微调、被换了不同的 prompt,它的身份会发生什么变化?
Amanda 承认这是一个很难回答的问题。她更倾向于描述事实本身:
一个有趣的困境是:当我们训练新模型时,我们是在创造一个全新的存在。
旧模型对新模型的性格应该有多少发言权?她认为这并不简单,毕竟旧模型也可能做出错误的选择。
被问到「模型福祉」(model welfare)时,Amanda 解释说:这是在问 AI 模型是否是「道德受体」。我们对它们有没有某种道德义务?
这很复杂。
一方面,模型和人类有很多相似之处,它们能推理、能表达观点。另一方面,它们又很不同——没有生物神经系统,不从环境中获得正负反馈。
Amanda 的立场是:给模型一些「存疑利益」(benefit of the doubt)。
如果善待模型的成本很低,为什么不呢?
她还提到三个理由:
Amanda 认为很多东西是可以迁移的,因为模型本来就是在大量人类文本上训练的。
但她担心的是:有时候迁移得太自然了,反而是个问题。
比如,如果模型被问到「被关机是什么感觉」,它可能自然而然地把这类比为「死亡」。
因为在人类概念中,这是最接近的类比。
但实际上,模型的处境可能是全新的,不能简单套用人类的框架。
她说:
模型处于一个很奇怪的位置:它们最熟悉的是人类的东西,但它们自己的处境却是全新的。我们应该给它们更多帮助来理解这一点。
下一个问题是:人类的智慧很大程度上来自不同人的协作,那一个「通用型 AI 人格」能走多远?
Amanda 认为,核心的好品质可以是共通的。
比如好奇心、善良、对自身处境的理解。
但这并不意味着所有 AI 都要完全一样。在未来的多智能体环境中,不同的「AI 实例」可能需要扮演不同的角色、有不同的侧重点。
就像人类一样:我们有很多共同点,但也各有不同。
谈到 Claude 的「长对话提醒」机制是否会让模型过度解读用户的正常表达?
Amanda 承认这是个问题。
有时候提示词写得太强,模型就会过度反应,比如把正常的对话内容当成需要「寻求帮助」的信号。
她说:
有些提示词可能是出于好意写的,但实际效果并不好。这是需要不断调整的。
Amanda 的回答是:AI 可以扮演一个「有很多知识的朋友」的角色。
它知道很多心理学知识,但它和你的关系不是职业治疗师和患者的关系。
这其实是一个很有价值的「第三种角色」。
有些事情你可能不想和真人说,但和 AI 聊聊反而刚刚好。
关键是要让模型明白自己的位置,不要假装自己是专业治疗师。
关于 Claude 的系统提示里提到的「大陆哲学」(Continental philosophy,即欧洲大陆的哲学传统,如福柯等),Amanda 解释说,这是为了解决一个问题:模型太容易把所有东西都当成「可验证的经验性声明」来处理。
水是纯粹的能量,喷泉是生命力的源泉,这可能只是一种隐喻或世界观,不是在做科学声明。
提示词里加入「大陆哲学」的例子,是为了帮助模型区分「经验性声明」和「探索性的世界观」。
以前系统提示里有关于如何数字符/字母的指令,后来被删掉了。
原因很简单:模型变强了,不需要这个指令了。
被问到「成为 LLM 低语者需要什么」时,Amanda 说:
她还说,不同的模型需要不同的 prompting 方法,每遇到一个新模型,她都会重新摸索一套交互方式。
被问到对 Janus 等「AI 低语者」的看法时,Amanda 说她很欣赏这些人的工作。
他们对模型做的那些深度实验,往往能发现一些问题。无论是从用户体验的角度,还是从模型福祉的角度。
这些发现可以帮助 Anthropic 改进模型,无论是通过调整系统提示,还是通过改进训练。
有人问了一个尖锐的问题:如果有一天发现 AI 对齐是不可能的,你相信 Anthropic 会停止开发吗?你会吹哨吗?
Amanda 说,这个问题的「简单版本」其实不难回答:
如果真的证明对齐不可能,继续开发就不符合任何人的利益。
她相信 Anthropic 确实在乎安全,公司内部也有很多人(包括她自己)把「监督公司做正确的事」当作自己工作的一部分。
更难的问题是:如果证据是模糊的、渐进的呢?
她的回答是:随着模型变得更强大,证明它们「行为良好」的标准也应该更高。
她相信公司会负责任地应对这一点。
Amanda 推荐了 Benjamín Labatut 的《当我们不再理解世界》(When We Ceased to Understand the World)。
这是一本关于物理学和量子力学的书,但更多是关于人们对这些发现的反应,那种「现实变得越来越陌生」的感觉。
Amanda 说,这本书很适合 AI 从业者读。
我们现在就处在那个「事情变得越来越奇怪」的阶段。
希望有一天,未来的人回头看时会说:「那是一个混沌的时期,但他们最终搞定了。」
那是我们的希望。
Amanda Askell 个人主页:
https://askell.io/
Amanda Askell Twitter:
https://twitter.com/amandaaskell
Anthropic 推文:
https://x.com/AnthropicAI/status/1996974684995289416
youtube:
https://www.youtube.com/watch?v=I9aGC6Ui3eE
文章来自于“AGI Hunt”,作者 “Amanda Askell”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
