# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
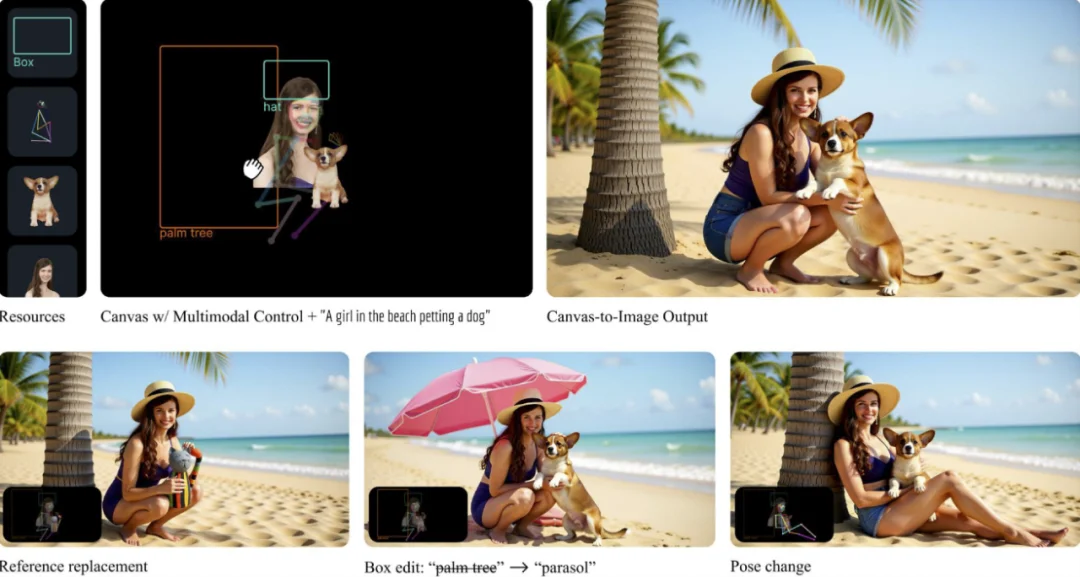
Canvas-to-Image 是一个面向组合式图像创作的全新框架。它取消了传统「分散控制」的流程,将身份参考图、空间布局、姿态线稿等不同类型的控制信息全部整合在同一个画布中。用户在画布上放置或绘制的内容,会被模型直接解释为生成指令,简化了图像生成过程中的控制流程。

在以往的生成流程中,身份参考、姿态线稿、布局框等控制方式往往被设计成互不相干的独立输入路径。
例如:
这些控制信号分别从不同通道进入模型,各自拥有独立的编码方式与预处理逻辑。结果就是:用户无法在画面的同一位置叠加多种控制信息,也无法用「一个局部区域里的组合提示」来告诉模型该怎么生成。
换句话说,传统方法的输入结构是多入口、分散式的,缺乏统一的表达空间。这使得复杂场景的构建流程变得冗长且割裂,用户只能一次提供一种控制,无法在同一个图像区域上同时表达身份 + 姿态 + 位置等组合指令。
Canvas-to-Image 正是针对这一结构性限制提出新的方案:所有控制信号都汇聚到同一张画布中,由模型在同一个像素空间内理解、组合并执行。
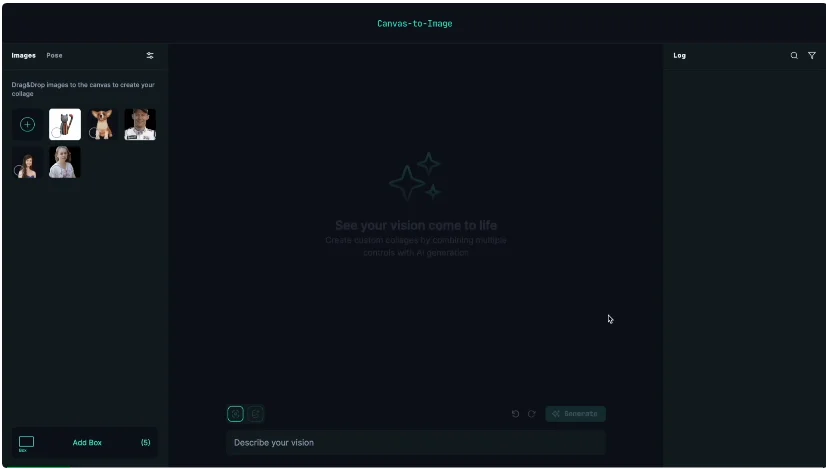
Canvas-to-Image 设计的关键在于——画布本身既是 UI,也是模型的输入。画布中可以出现:
这些异构视觉符号中包含的空间关系、语义信息,都由 VLM-Diffusion(基于 Qwen-Image-Edit)直接解析。
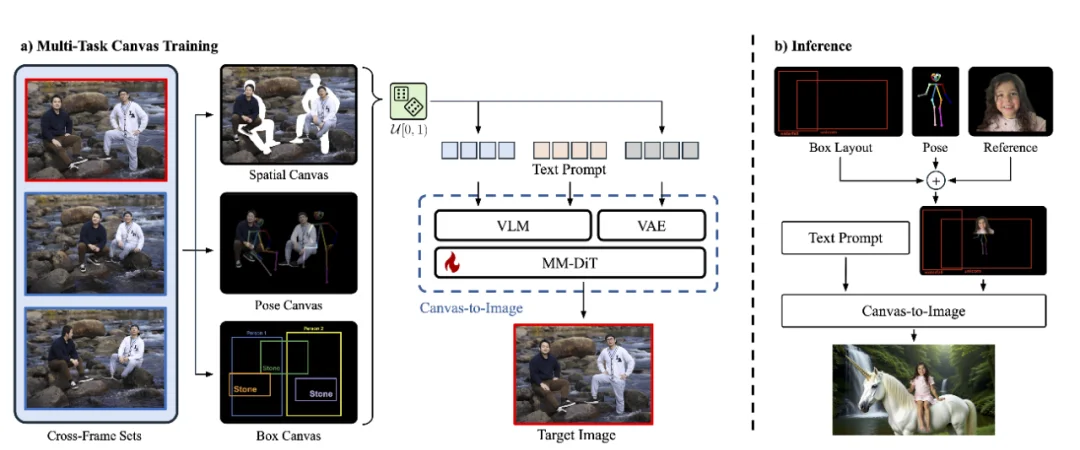
在训练过程中,Canvas-to-Image 的多任务画布从跨帧图像集(cross-frame image sets)中自动生成。具体流程如下:
这样的跨帧采样策略会在输入画布中自然引入姿态、光照、表情等方面的显著差异,使得输入提示与目标图像之间不存在可直接复用的像素对应关系。由此,模型无法依赖简单的拷贝机制来完成训练任务,而必须学习更抽象的语义关联与结构映射。这一设计在训练阶段有效规避了「抄输入」的捷径,从根本上避免了模型在推理阶段出现 copy-paste 式的生成行为。
为了保持训练的简洁性,在每一次训练中,模型只会接收到一种随机选定的控制模态(例如空间布局、姿态骨架或边界框)。这样可以让模型分别学会独立理解不同类型的控制提示,并在推理阶段自然实现多控制的组合能力。
在推理阶段,Canvas-to-Image 允许用户在同一张画布上灵活组合多种控制模态,例如同时提供身份参考区域、姿态骨架以及空间布局框,从而实现复杂的多控制场景生成。与传统「单一路径控制」的方案不同,用户无需在不同模块之间切换或分阶段注入条件,而是通过统一画布一次性给出所有约束信号。
从学习机制上看,模型在训练过程中仅接触到单一控制模态的样本:每个训练样本只随机激活其中一种控制形式(身份、姿态或位置),使模型分别掌握对单独控制信号的理解与对齐能力。值得注意的是,即便在数据中并不存在显式标注的「多模态组合控制」样本,模型在推理阶段仍然能够在统一画布中同时解析并整合多种控制信号:它会在身份参考的约束下保持人物外观一致性,在姿态骨架约束下生成结构合理的姿态,并在布局框条件下遵循全局空间排布。
这一现象表明,模型在统一画布表示的框架下,学到的并不是对某一种控制模态的简单记忆,而是对「画布上局部区域与目标图像结构之间关系」的更高层次建模能力。换言之,模型在仅依赖单模态训练的前提下,仍然展现出对未见过控制组合的泛化能力:在推理中面对新的、复杂的多控制配置时,依然能够生成结构一致、外观可信且各控制信号相互兼容的高质量结果。这也从实验角度验证了统一画布设计在提升组合式可控生成能力方面的有效性。
Canvas-to-Image 能够同时处理身份、姿态和布局框,而基线方法往往会失败。Canvas-to-Image 能:

当画布中同时包含人物提示和物体提示时,Canvas-to-Image 不会把两者当作独立元素简单并置。模型能够理解两者之间应有的空间与语义关系,因而会生成具有自然接触、合理互动的场景。
此外,在多种控制叠加的情况下,Canvas-to-Image 仍能保持:
因此即便在复杂的组合控制设置下,生成的画面也能呈现出连贯、可信的互动效果,而不是常见的「贴图式合成感」。

在给定一张背景图的情况下,Canvas-to-Image 可以通过放置参考图或标注边界框的方式,将人物或物体自然地融入场景。模型会根据画布中的提示自动调整空间关系,使插入元素在位置、光照和整体氛围上与背景保持一致,呈现近乎原生的融合效果。

我们系统地测试了当逐步添加控制时模型的表现:
关键发现:虽然训练时使用单任务画布,但模型自然学会了在推理时组合多种控制——这种涌现能力验证了我们的设计理念。

Canvas-to-Image 的核心价值是把多模态的生成控制方式全部图形化,让复杂场景的构建回归到最直观的方式:在画布上摆放、画、框,就能让模型生成对应的结构化、真实感强的画面。统一画布 + 多模态控制的范式,将有望成为下一代创作工具的基础界面形态。
文章来自于“机器之心”,作者 “机器之心”。


