# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今天我们正式发布 Jina-VLM,这是一款 2.4B 参数量的视觉语言模型(VLM),在同等规模下达到了多语言视觉问答(Multilingual VQA)任务上的 SOTA 基准。
面对小参数量 VLM 在增强视觉能力时容易牺牲文本表现、以及高分辨率图像推理成本高的问题,Jina-VLM 给出了自己的解法:我们引入了注意力池化(Attention-pooling),连接 SigLIP2 视觉编码器与 Qwen3 语言基座,成功在支持 29 种语言的同时,实现了对任意分辨率下自然图片和文档图片(如扫描件、ppt、表图)上的问答、理解、提取任务的高效处理。
Jina-VLM 对硬件需求较低,可在普通消费级显卡或 Macbook 上流畅运行。
在 VLM 领域,参数量往往决定了性能天花板,但 Jina-VLM 证明了架构优化可以突破这一限制。如下表所示,Jina-VLM 在多项关键基准测试中均优于同量级的 Qwen2-VL 和 InternVL 系列。
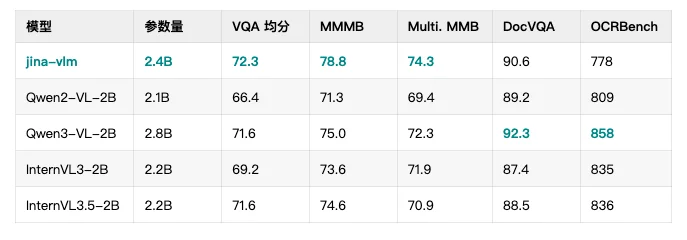
不管是在标准的 VQA 任务、多语言多模态理解(MMMB、MMBench),还是在 OCR 和纯文本任务上,Jina-VLM 都是同规格模型里最优级别的表现,且同时具备在消费级硬件友好的推理效率。

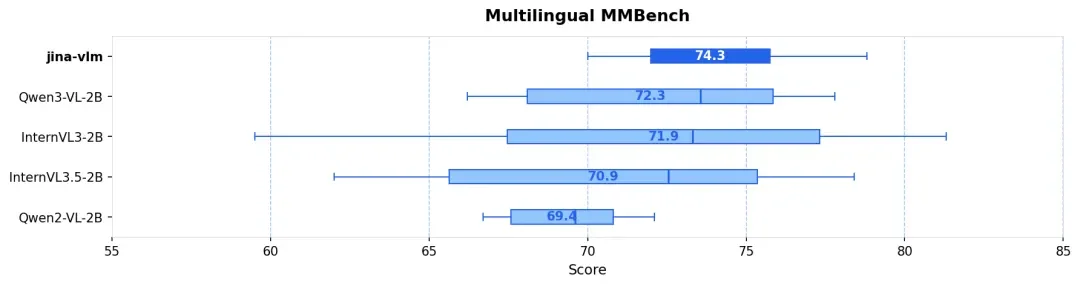
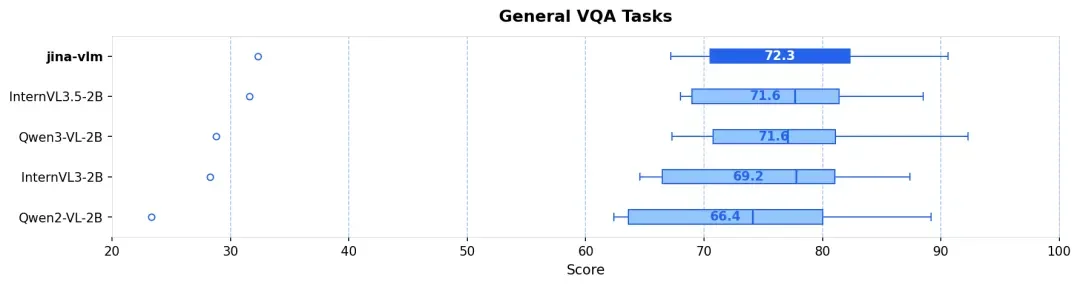

在设计 2B 参数量级的 VLM 时,我们面临一个核心的工程矛盾:看得清(高分辨率)往往意味着算不动(Token 爆炸)。
传统的 Vision Transformer (ViT) 处理高密度扫描件、复杂 PPT 时,一般是图像切分为多个图块(Tiles)。按 378×378 来算,一张高清大图(12 切片 + 1 缩略图)会产生近 9500 个视觉 Token。这在 Transformer 架构下,Token 数量的增加会导致计算量呈平方级爆炸。
Jina-VLM 将输入端的动态切片与模型端的智能压缩结合起来:既保留高分辨率的视觉信息,又把下游语言模型看到的视觉 Token 数量压缩约 4 倍。既看得清,也算得动。
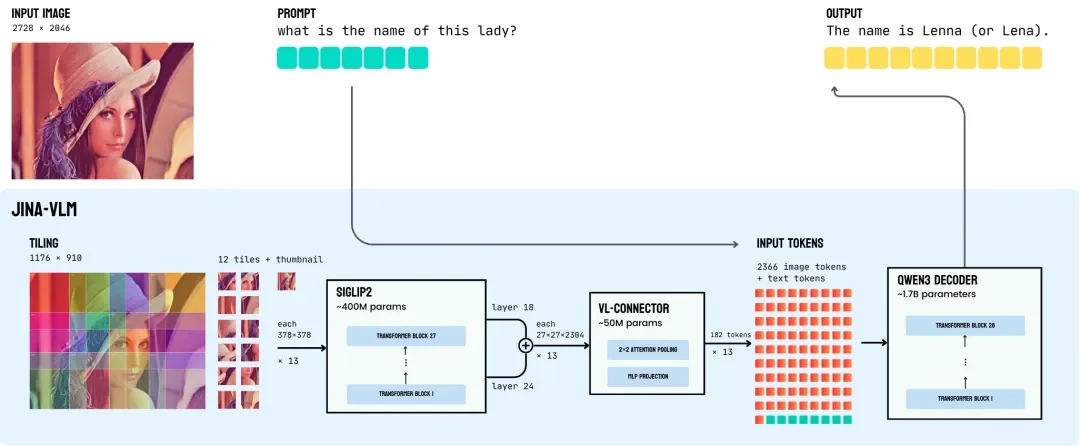
Jina-VLM 架构图,展示了从 SigLIP2 视觉编码器 → VL-Connector → Qwen3 语言基座 的数据流
为了适配 SigLIP2 的固定输入尺寸,并保留细节,我们采用了 动态重叠切片(Dynamic Overlapping Tiling)策略。
1. 全局缩略图:不管原图多大,先生成一张缩略图,让模型能掌握整张图的总体布局。
2. 动态滑窗切片:利用滑动窗口将原图切分为多个 378×378 的图块(默认最多 12 块)。关键在于,我们在图块之间预留了 112 像素的重叠区,确保跨图块的文字或物体不会因分割而导致特征断裂。
这一步解决了“看得清”的问题,但也导致了 Token 数量的激增。解决这一负载压力的关键,在于接下来的视觉-语言连接器(VL-Connector)。
这是 Jina-VLM 的核心创新。与业界常见的 Q-Former(破坏空间结构)或平均池化(丢失细节)不同,我们设计了 2×2 注意力池化机制,实现了 4 倍无损压缩:
大多数模型只取视觉编码器的最后一层输出,Jina-VLM 提取并拼接了两层中间特征:
通过拼接(concat)这两层特征,模型既能理解“这是什么”(语义),也能看清“它长什么样”(细节),为后续处理提供了信息密度极高的输入。
但拿着双倍的信息量,Token 不是更多了吗?
这里是 Jina-VLM 解决视觉 Token 爆炸的关键,我们在连接器中引入了注意力池化机制,实现 4 倍无损压缩:
该机制的核心在于 特征的智能聚合,其工作流如下:
通过这一设计,单个切块(Tile)的输出从 729 个 Token 无损压缩至 182 个。虽然数量减少,但因为严格保留了 Grid(网格)拓扑结构,模型对文档版面、图表坐标的空间感知能力不会受损。
实测数据对比(以 12 Tile 输入为例):

注:视觉编码器的计算量相对固定,不受 Token 数量影响。我们的优化主要体现在语言模型(LLM)的推理阶段,这个是 VLM 部署成本的大头。
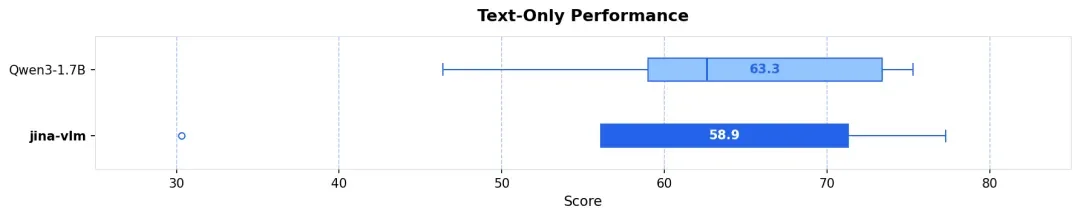
在 VLM 的研发里,业界长期面临一个零和博弈,模型在努力适应新模态时,往往以牺牲原本的文本推理能力为代价,这就是 灾难性遗忘(Catastrophic Forgetting)。其最直接的表现,就是模型在理解图片后,其多语言能力发生退化 (Multilingual Degradation),甚至连基础的纯文本逻辑推理都变得脆弱。
Jina-VLM 采用 两阶段训练 + 持续纯文本注入(Text-only Data Incorporation) 策略。在覆盖 29 种语言、约 500 万张图像和 120 亿文本 Token 的训练规模下,我们的核心目标是:在最大化视觉语义对齐的同时,严格保全语言基座的通用性能。
训练数据中英语占一半,此外还包括中文、阿拉伯语、德语、西班牙语、法语、意大利语、日语、韩语、葡萄牙语、俄语、土耳其语、越南语、泰语、印尼语、印地语、孟加拉语等多种语言。
第一阶段的主要任务是把 SigLIP2 的视觉特征映射到 Qwen3 的文本向量空间。训练数据主要来源于 PixmoCap 和 PangeaIns 等高质量字幕数据集。
这里最关键的一点是,我们在训练数据里强制注入了 15% 的纯文本数据。 这么做不是为了灌输新知识,而是为了防止模型在学看图的时候把原来的语言习惯给忘了。
配合这个思路,我们对模型的不同部分采用了不同的学习节奏:负责连接视觉和语言的组件(Connector)学习率设得很高,让它快速收敛;而原本的大模型基座学习率压得很低,让它在接受新模态信息时保持稳定,尽量不破坏已有的知识结构。
到了第二阶段,我们要提升模型的指令遵循能力,比如在 VQA、OCR 和数学推理等特定任务上的表现。由于训练数据涵盖学术问答、文档理解、图表推理等多种场景,异构性极高,容易在初期造成梯度不稳定。对此,Jina-VLM 采用了 先分后合的渐进式策略:
先使用单源数据,让模型在相对单纯的环境里,快速掌握各类任务的特性(如 OCR 的字符识别、ChartQA 的逻辑推理)。再进行多源数据混合训练,让模型学会融会贯通,处理复杂的跨任务场景。
整个过程中,纯文本的指令数据始终伴随着训练,确保模型在处理多模态任务时,其纯文本的推理与知识检索能力不发生退化。
凭借这一精细的训练控制,Jina-VLM 不仅在 MMMB 等多语言视觉榜单上达到 SOTA,更关键的是,在 MMLU(通用知识)和 GSM-8K(数学推理)等纯文本基准测试中,它几乎完整保留了 Qwen3-1.7B 基座的性能,真正实现了 视觉增强,语言无损。
我们在 https://api-beta-vlm.jina.ai 上线了兼容 OpenAI 接口规范的 API 服务,支持流式输出与 Base64 图像输入。

通过 URL 处理图像:
curl https://api-beta-vlm.jina.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $JINA_API_KEY" \
-d '{
"model": "jina-vlm",
"messages": [{
"role": "user",
"content": [
{"type": "text", "text": "描述这张图片"},
{"type": "image_url", "image_url": {"url": "https://example.com/photo.jpg"}}
]
}]
}'
curl https://api-beta-vlm.jina.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $JINA_API_KEY" \
-d '{
"model": "jina-vlm",
"messages": [{
"role": "user",
"content": [
{"type": "text", "text": "What is in this image?"},
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,'$(base64 -i image.jpg)'"}}
]
}]
}'
curl https://api-beta-vlm.jina.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $JINA_API_KEY" \
-d '{
"model": "jina-vlm",
"messages": [{"role": "user", "content": "What is the capital of France?"}]
}'
只需添加 "stream": true ,在生成同时接收 Token:
curl https://api-beta-vlm.jina.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $JINA_API_KEY" \
-d '{
"model": "jina-vlm",
"stream": true,
"messages": [{"role": "user", "content": "Write a haiku about coding"}]
}'
如果遇到服务冷启动,API 可能会返回如下 503 错误:
{
"error": {
"message": "Model is loading, please retry in 30-60 seconds. Cold start takes ~30s after the service scales up.",
"code": 503
}
}
此时服务正在自动扩容,稍作等待后重试请求即可。
我们的 HuggingFace 仓库包含一个 infer.py 脚本,用于快速测试:
# Single image
python infer.py -i image.jpg -p "What's in this image?"
# Streaming output
python infer.py -i image.jpg -p "Describe this image" --stream
# Multiple images
python infer.py -i img1.jpg -i img2.jpg -p "Compare these images"
# Text-only
python infer.py -p "What is the capital of France?"
Jina-VLM 现已开源并集成至 Hugging Face 生态。
from transformers import AutoModelForCausalLM, AutoProcessor
import torch
from PIL import Image
# 加载模型 (支持 bfloat16 精度)
model = AutoModelForCausalLM.from_pretrained(
"jinaai/jina-vlm",
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto"
)
processor = AutoProcessor.from_pretrained("jinaai/jina-vlm", trust_remote_code=True)
# 推理示例
image = Image.open("document.png")
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": image},
{"type": "text", "text": "这份文档的主题是什么?"}
]
}
]
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True, return_tensors="pt"
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=256, do_sample=False)
print(processor.decode(outputs[0], skip_special_tokens=True))
Jina-VLM 强有力地证明了,通过精妙的架构设计与训练策略,小参数量 VLM 完全可以具备卓越的跨语言视觉理解能力。我们的注意力池化连接器(Attention-pooling connector)在几乎不牺牲精度的情况下,在将 Token 数量大幅削减 4 倍;而在多模态训练中策略性地混入纯文本数据,则成功保全了模型原本容易发生退化的语言能力。
当然,任何架构设计本质上都是一种 trade-off:
未来的工作,我们将致力于探索更高效的分辨率处理机制,并验证这套多语言训练配方能否成功迁移至更大规模的模型中。
文章来自微信公众号 “ Jina AI ”


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
