# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文为Milvus Week系列第6篇,该系列旨在把Zilliz团队过去半年多积累的先进的技术实践和创新整理成多篇干货深度文章发布。
以下是DAY 6内容 划重点:
在智能Agent的上下文(Context)处理体系中,关键词匹配是贯穿核心链路的刚性需求。
无论是客服Agent从数万条历史对话日志中定位有特定产品、成分的话术资料,还是AI Coding场景,检索特定的代码片段;亦或是法律、医疗、学术等场景,筛选包含特定内容的文档,本质上都依赖于对关键词的精确检索能力。
而LIKE表达式,正是支撑这类需求的经典技术手段。例如通过filter = "name LIKE '%rod%'"查询包含特定子串的记录。
然而,在Agent场景的高并发、大容量数据背景下,传统LIKE表达式的性能短板则会被无限放大。
在未建立索引时,LIKE表达式需对全量上下文数据执行逐行正则匹配。若Agent的上下文池包含百万级对话记录,单次查询耗时甚至可达秒级,完全无法满足Agent实时交互的要求。
即便为查询字段建立常规索引,LIKE表达式的执行仍需对索引词典进行全量正则遍历;这种看似去重的操作,本质上仍是线性扫描,实际性能提升微乎其微。
针对这一痛点,Milvus采用了Ngram Index作为解决方案,通过引入分词技术,Ngram Index能高效适配LIKE表达式的各类查询场景,成为优化其性能的核心方案。
本文将深入剖析LIKE查询的性能痛点,并系统介绍Ngram Index的原理、执行逻辑及实践效果。
LIKE表达式可归纳为四种核心类型,Ngram Index能对其实现全面优化,具体分类如下:
%,且分别位于 literal 的首尾,比如 filter = 'name LIKE "%rod%"'filter = 'name LIKE "rod%"'filter = 'name LIKE "%rod"'% 和 _,比如 filter = 'name LIKE "%rod%aab%bc_de"'基于以上背景,Ngram Index的核心逻辑是将文本拆分为固定长度的连续子串(即N元分词),通过构建这些子串的倒排索引,将模糊匹配转化为精确子串查询。其索引构建需依赖两个关键参数:min_gram(最小分词长度)和max_gram(最大分词长度),对文本中长度介于两者之间的所有连续子串执行分词并建立索引。
以实际案例说明:若对文本“Apple”执行分词,且设置min_gram = 2、max_gram = 3,则分词结果包含所有2元子串和3元子串,即:“Ap”“pp”“pl”“le”“App”“ppl”“ple”。
基于该分词规则,我们对5条样本数据(Apple、Pineapple、Maple、Apply、Snapple)构建倒排索引,结果如下表所示(键为N元子串,值为对应数据的索引编号):
"Ap" -> [0, 3]
"App" -> [0, 3]
"Ma" -> [2]
"Map" -> [2]
"Pi" -> [1]
"Pin" -> [1]
"Sn" -> [4]
"Sna" -> [4]
"ap" -> [1, 2, 4]
"apl" -> [2]
"app" -> [1, 4]
"ea" -> [1]
"eap" -> [1]
"in" -> [1]
"ine" -> [1]
"le" -> [0, 1, 2, 4]
"ly" -> [3]
"na" -> [4]
"nap" -> [4]
"ne" -> [1]
"nea" -> [1]
"pl" -> [0, 1, 2, 3, 4]
"ple" -> [0, 1, 2, 4]
"ply" -> [3]
"pp" -> [0, 1, 3, 4]
"ppl" -> [0, 1, 3, 4]
Ngram index 过滤执行分为两阶段:一阶段:从倒排索引中查找到可能符合条件的文档,二阶段:从选中的文档中进行精确过滤操作。
接下来分别介绍 inner_match 和 match 在 ngram index 下的执行操作(prefix_match 、 postfix_match 与 inner_match 类似,所以略过)。
执行 strField LIKE %ppl%
一阶段:从 ngram 索引中查找 "ppl",候选 [0, 1, 3, 4];
二阶段:inner_match 在 literal 长度介于 min_gram 和 max_gram 之间(包含边界)时,无需二阶段查找。
Literal 的长度可能大于 max_gram,比如 strField LIKE %pple%,此时需要对 literal 进行 max_gram 为粒度的分词
一阶段:"pple" 按照 max_gram 分词,结果为 "ppl" 和 "ple",在倒排中分别对应 [0, 1, 3, 4] 和 [0, 1, 2, 4],由于最终结果必须同时包含 "ppl" 和 "ple",所以需要取交集,结果为 [0, 1, 4]
二阶段:[0, 1, 4] 对应的文档 ["Apple", "Pineapple", "Snapple"] 中进行 %pple% 过滤,结果为 [0, 1, 4]
Literal 的长度可能小于 min_gram,这种情况无法通过 ngram 进行优化,按原路径执行。
执行 strField LIKE %Ap%pple%
一阶段:首先需要对 %Ap%pple% 按通配符进行分词,结果为 "Ap" 和 "pple",然后需要判断是否存在小于 min_gram 的分词(存在则无法进行 ngram 优化),对于大于 max_gram 的需要按照 max_gram 分词,结果为 "Ap","ppl" 和 "ple",在倒排中分别对应 [0, 3],[0, 1, 3, 4],[0, 1, 2, 4],取交集结果为 [0]。
二阶段:在 [0] 对应的文档 ["Apple"] 中进行 %Ap%pple% 过滤操作,结果为 []。
从上述流程可见,Ngram Index的优化本质是降维——将原本的全文暴搜,转化为N元子串精确点查+小范围候选验证,而点查操作的时间复杂度远低于暴搜,从而实现性能跃升。
尽管Ngram Index能大幅优化查询性能,但仍存在两项核心局限性,需在实际应用中权衡:
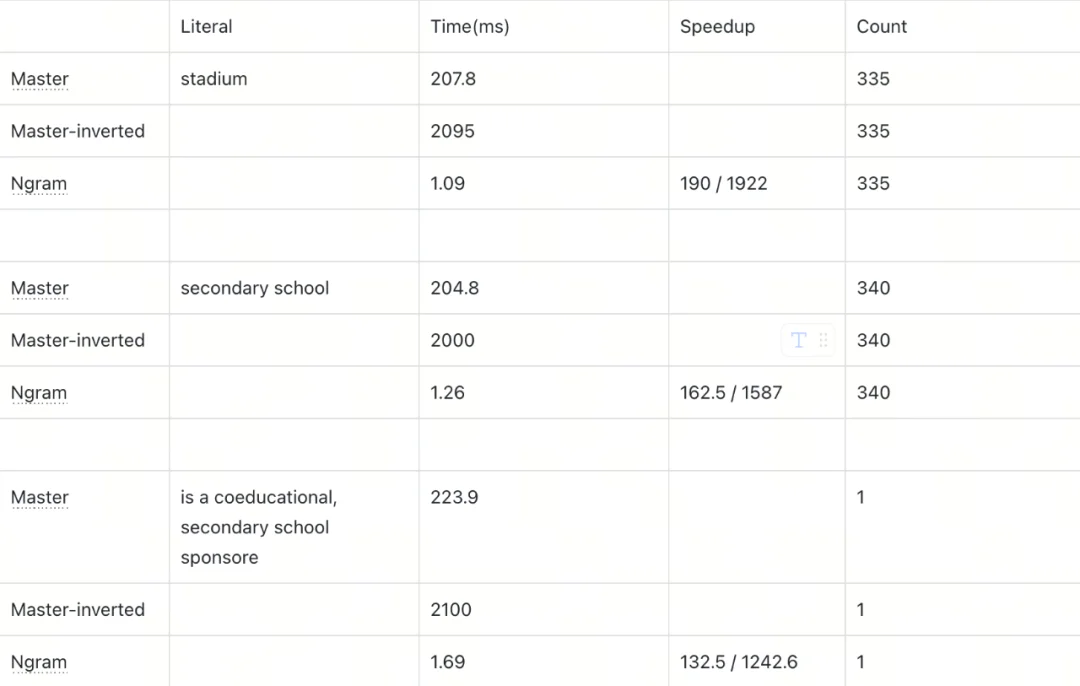
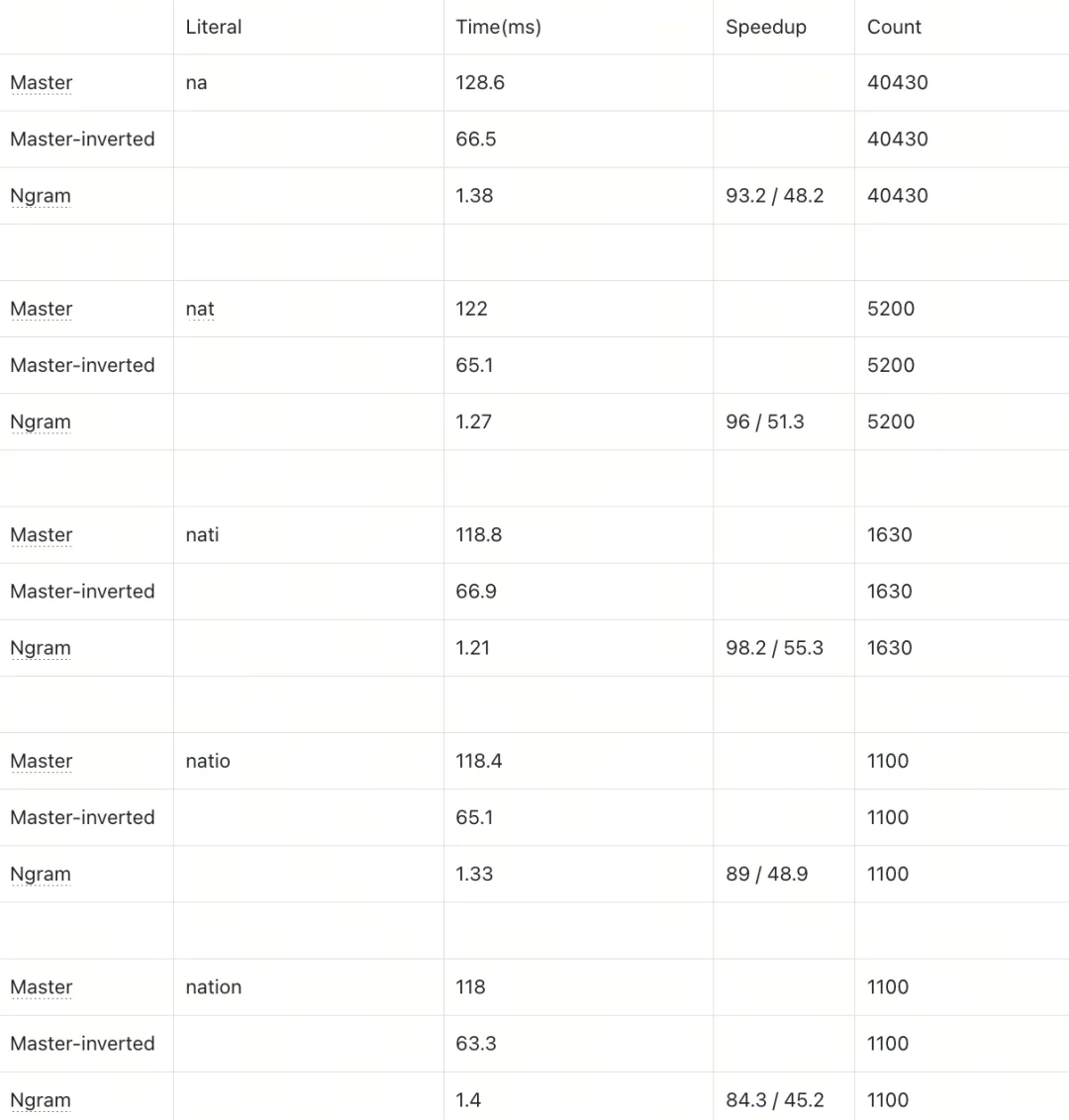
为验证Ngram Index的优化效果,我们设计了两组测试场景:Wiki文本数据(10万行,单条文本长度截断为1000字节)和 single words(100万行),均采用 Inner Match(%xxx%)模式,Ngram参数设置为min_gram=2、max_gram=4,对比Master(无索引暴力查询)、Master-inverted(常规倒排索引)与Ngram Index的执行耗时及加速比。
为比较执行本身,设置 output_filed 为 count(*)。
该 benchmark 是 5 月份的结果,master 在这段期间进行了一定程度的优化,所以性能差距应该减少了。
Test for wiki, each line is a wiki text with content length truncated by 1000, 100K rows
Test for single words, 1M rows
结论:
测试结果表明,Ngram Index对LIKE查询的性能提升效果显著,且提升幅度与数据特征强相关:
当前以上结果为5月份测试结果,此后半年master 已经有了一定优化,当下差距应该会有一定的缩小。
综上,对于代码检索、客服agent、法律、医疗、企业知识库、学术等场景,Ngram Index是解决LIKE模糊查询性能问题的高效方案,尤其适用于长文本模糊匹配场景。
此外,在实际应用中,我们需结合业务查询特征合理设置min_gram与max_gram参数,平衡索引空间成本与查询性能收益。

唐晨杰
Zilliz Senior Software Engineer
文章来自于“Zilliz”,作者 “唐晨杰”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
