# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近,Prime Intellect正式发布了INTELLECT-3。
这是一款拥有106B参数的混合专家(Mixture-of-Experts)模型,基于Prime Intellect的强化学习(RL)技术栈训练。
在数学、代码、科学与推理的各类基准测试上,它达成了同规模中最强的成绩,甚至超越了不少更大的前沿模型。
Prime Intellect已经把完整的训练流程——包括模型权重、训练框架、数据集、RL环境和评测体系——全部开源,希望能推动更多关于大规模强化学习的开放研究。
INTELLECT-3使用的训练软件与基础设施,与即将在Prime Intellect平台向所有人开放的版本完全一致。
这意味着未来每个人、每家公司都能拥有对最先进模型进行后训练的能力。
多项基准,斩获SOTA
INTELLECT-3是一个106B参数的Mixture-of-Experts(MoE)模型,基于GLM 4.5 Air进行了监督微调(SFT)和强化学习训练。
它在数学、代码、科学和推理类Benchmark上均取得了同体量中的最强表现。

训练框架
训练中,Prime Intellect使用了以下核心组件:
INTELLECT-3完整使用PRIME-RL进行端到端训练。
这套框架与Verifiers环境深度整合,支撑从合成数据生成、监督微调、强化学习到评估的整个后训练体系。
通过与Environments Hub的紧密连接,训练系统可以顺畅访问不断扩展的环境与评测任务集合。
PRIME-RL最显著的特点是全分布式(async-only)。
研究团队在上一代INTELLECT-2时就已经确认:
RL的未来一定是分布式的,也就是始终处于轻微off-policy的状态。
因为在长时序智能体rollout中,分布式是唯一能避免速度瓶颈、真正扩大训练规模的方式。
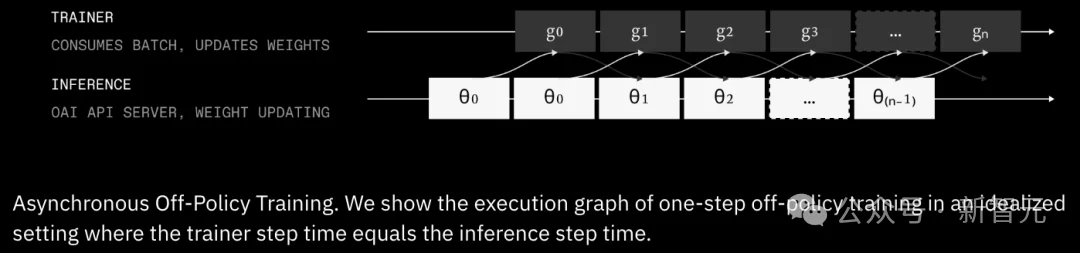
过去6个月,研究团队重点做了大量关于性能、稳定性和大规模效率的消融实验,INTELLECT-3正是这些研究的成果。
Prime Intellect也将在即将上线的Lab平台提供托管式PRIME-RL,访问者无需处理复杂基础设施就能进行大规模RL训练。
训练环境
INTELLECT-3的训练环境由Verifiers库构建,并托管于Environments Hub,这是Prime Intellect面向社区的RL环境与评测中心。
Verifiers是当前领先的开源工具,用来为模型构建RL环境与评测任务。
它提供模块化、可扩展的组件,让复杂环境逻辑也能以简洁方式描述,同时保持极高性能与吞吐。
传统的RL框架通常把环境强绑定在训练仓库里,使得版本管理、消融与外部贡献都不方便。
Environments Hub则把基于Verifiers的环境作为独立、可锁定版本的Python模块发布,并统一入口点,让任务可以独立版本化、共享与持续迭代。
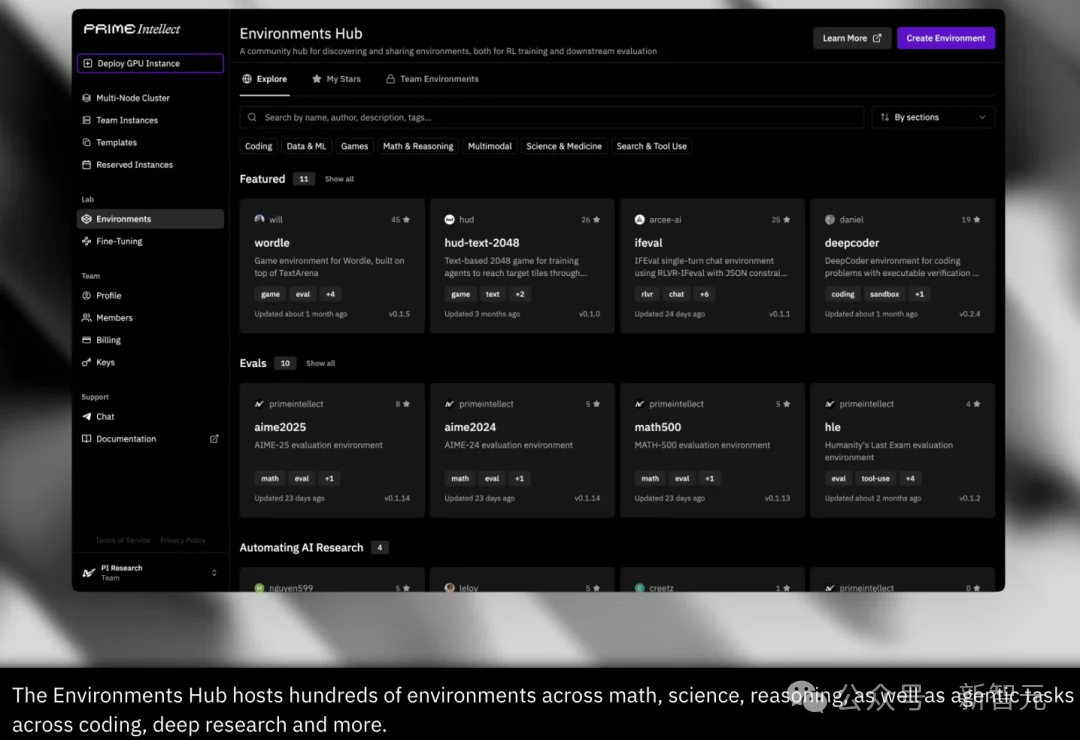
INTELLECT-3使用的所有环境和评测,均已公开在Environments Hub。
为了支持强化学习,Prime Intellect大幅扩展并升级了自研的Sandboxes基础设施。
在几千条并发rollout中安全执行外部代码,需要一个具备亚秒级启动、毫秒级执行延迟的容器编排层。
虽然Kubernetes提供了底层能力,但常规架构并无法满足这种高速度的训练需求。
Prime Sandboxes可以绕过Kubernetes控制面板,通过Rust直接与pod通信,做到接近本地进程的延迟;即使在大规模并发下也能在10秒内启动,且每个节点可稳定运行数百个隔离沙箱。
在Verifiers中,研究人员将沙箱启动与模型首轮推理并行,从而完全消除代码执行前的可感知等待时间。
算力调度
研究人员在64个互联节点上部署了512张NVIDIA H200 GPU。
最大工程挑战是如何在可能出现硬件故障的分布式系统里保持确定性与同步。
训练方案
INTELLECT-3主要分两阶段:
基于GLM-4.5-Air的监督微调,以及大规模RL训练。
两个阶段以及多轮消融实验都在512张H200 GPU上运行,总共持续两个月。
研究人员训练了覆盖数学、代码、科学、逻辑、深度研究、软件工程等类别的多样化RL环境,用来提升模型的推理与智能体能力。
所有环境均已在Environments Hub上公开。
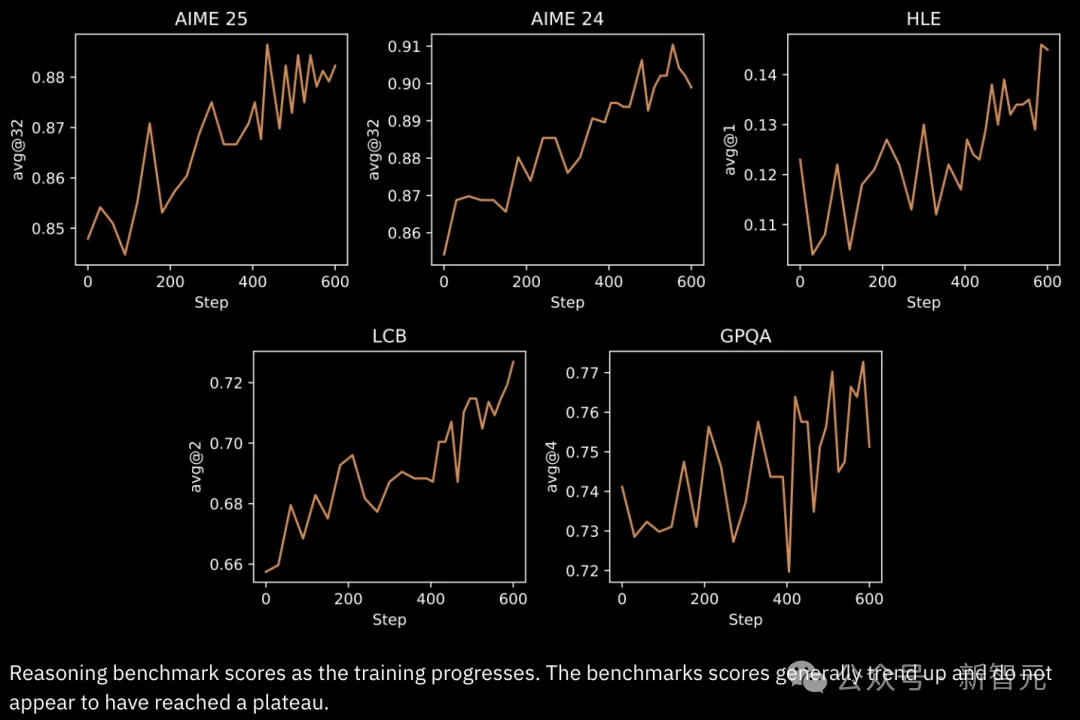
所有基准测试也都提供了标准化且验证过的实现。
未来,Prime Intellect的工作重点包括:
Prime Intellect正在构建开放的超级智能技术栈,把训练前沿模型的能力交到每个人手里。
INTELLECT-3 也证明:即使不是大实验室,也可以训练出与顶尖团队同台竞技的模型。
参考资料:
https://www.primeintellect.ai/blog/intellect-3
文章来自于微信公众号 “新智元”,作者 “新智元”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
