# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
“人工智能要发展到下一个台阶,一定要突破两座大山。第一座大山是Transformer,第二座大山是反向传播算法。”
在大模型规模不断拔高、算力与数据卷到极致的当下,RockAI创始人刘凡平提出了一个与主流共识截然不同的判断。
下一阶段的智能,不在“更大”,而在“活起来”。
本质是让模型摆脱静态函数的桎梏,让端侧设备具备原生记忆、自主学习与持续进化的能力。
这意味着AI的方向要从云端集中式的算力竞争,迁移到每一台设备,每一个个体都能参与学习,生成知识的全新范式。
在量子位MEET2026智能未来大会上,刘凡平将这一转折点称为硬件觉醒:
当模型在端侧能像大脑一样稀疏激活、实时形成记忆,并在物理世界中不断更新自身,设备就不再是工具,而是“活”的智能体。
而无数这样的智能体在现实世界中学习、协作,便将孕育出真正能够产生知识的群体智能。

这既是对Transformer与反向传播算法这“两座大山”的正面突破,也是迈向通用人工智能的一条新路径。
为了准确呈现刘凡平的完整思考,以下内容基于演讲实录进行整理编辑,希望能提供新的视角与洞察。
MEET2026智能未来大会是由量子位主办的行业峰会,近30位产业代表与会讨论。线下参会观众近1500人,线上直播观众350万+,获得了主流媒体的广泛关注与报道。
以下为刘凡平演讲全文:
很高兴能够和大家在今天分享RockAI在模型层面的思考,也许今天讲的内容和大家平常理解的有些不一样——我们认为通用人工智能一定有自己的发展路径。
今天分享的主题是硬件觉醒。
我们知道硬件是没有生命的,怎么可能觉醒?没错,我们做大模型应该重新思考这一切的东西,这一切就是因为被Transformer束缚了。
我想问一下大家,你期待的未来的智能硬件是什么样子?是你的智能手机还是平板,还是前两天的豆包手机?
今天很多大会嘉宾都提到了Agent,提Agent的时候都提到一个点:工具,更高效的工具。
当前很多人还是把大模型当工具用。就像计算器一样,我需要的时候拿过来用一下,不需要的时候就放开了。
从智能发展角度来想想:豆包手机能按照指令打开APP做相应的事情,下一步会发生什么?它能打开微信发信息,那微信未来的样态还是现在这样吗?它能打开高德地图,高德地图十年以后还是现在这样吗?
大家会发现,目前是一个中间状态,并不是终极状态。
刚刚很多嘉宾提到,Token消耗量增长了10倍,尤其是使用上Agent之后。
这本质是在为Token付费。
但大家有没有想过:为Token付费是一件很愚蠢的事情。
我们为什么做大模型?是因为智能。如果要付费,应该是为智能付费,为什么为Token付费?
打个比方,有的人讲话只要简单几句就能说清楚,有的人说话很啰嗦,我难道要为它的啰嗦付费吗?肯定是不对的。
细想一下,就会发现为Token付费是一个错误。未来(两年之后)回头看,我相信大家一定也会疑惑当年居然还为Token付过费、充值过。
硬件已经发生了很多变化,当前的云端大模型已经慢慢走向了终端设备。
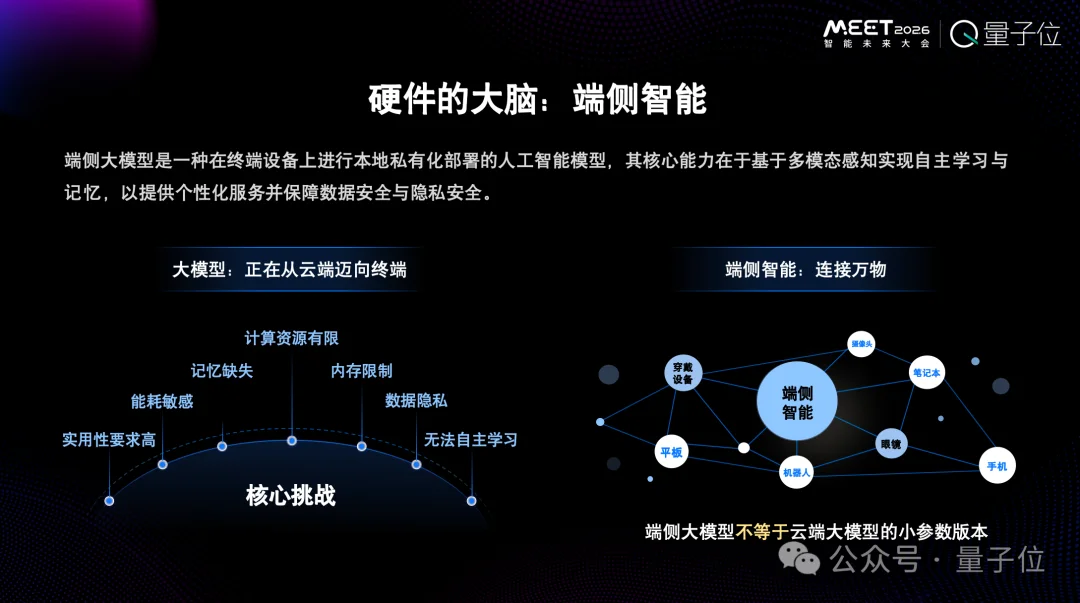
为什么这么说?我们不否定云端大模型的好处,尤其在工具使用上,云端大模型非常优秀。
但是未来AI是属于每一个人的。要让AI走向每一个人的世界,最重要的是端侧的智能。
一方面因为端侧离你更近,而且端侧还有一个“数据无处不在”的好处。
我一直以来比较反感把所有数据采集到云端,云端训练好了再下发给用户使用。
数据明明就在你的身边,为什么做不到就让它在你身边?因为云端大模型参数量太大了,也没有这么多设备收集你身边的数据。
端侧大模型如果能在设备上收集数据,而且是完全属于你个人的数据,且这台设备又能和你其他设备关联,那个时候大家就不会单纯把模型当做一个工具来使用了。
很多人觉得端侧受限于设备,算力有限,所以在云端做几十B的“大”模型,端侧做几B的“小”模型,就成了端侧模型。
但端侧模型并不是云端大模型的小参数版本。
RockAI对端侧大模型有两个非常关键的定义:自主学习和原生记忆。这是我们认为最重要的事情。
如果是Transformer架构的模型,无法在端侧实现自主学习与原生记忆。
Transformer很优秀。
我自己就是国内最早研究Transformer的人之一,对它早期的成功非常认可。
但它现在进入到一个死亡螺旋的状态,带来一个问题——为了让模型能力足够突出我们要加大算力、加大数据,带来成本极大提升。大家和竞争对手都在做同样的事情。

你会发现,大家都没有管架构,大家都在干数据和算力。因为“只要我数据算力够了,我就做得更好”。
我们认为,信仰Scaling Law的成功在现在看来是错误的。不仅我这样说,现在很多人也有类似的观点。
核心本质不在于模型不够大,而在于思考的方式错了。
模型本身是一个静态函数,这种静态函数是不太可能会具备真正的智能。因为人的大脑是一个动态函数,每时每刻都在建立新的连接,而新的连接是动态结构的。人的大脑是因为这样才有了记忆的能力。

另一个误区是“更多参数就意味着更多智能”。
在Transformer架构下这样想没错,但如果跳出Transformer架构就不是这样了。
举一个简单的例子——
生物界,一条蛇或者一个小兔子它没有智能吗?应该没有人否定它们的智能。
和人脑相比,它们大脑拥有的“参数”肯定少很多。
另外还有长上下文。
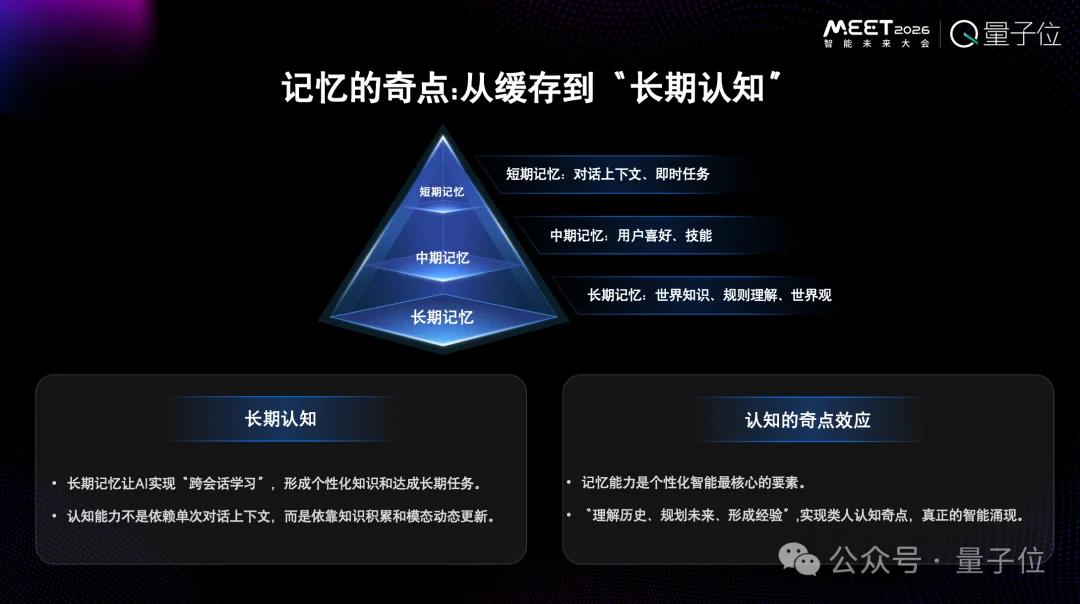
2024年,长上下文方面有很多突破。但我们一直不认为长上下文是一种记忆,真正的记忆应该像人大脑的海马体一样,会把所有信息通过加工处理压缩存储下来,根据需要的情况会移除掉一部分信息。
这种记忆是参数化的记忆,不是靠上下文完成的。靠上下文完成,记忆就会很短。
为什么现在大家又执着于做上下文?是因为Agent,而Agent背后的Transformer架构模型部署后是一个静态函数,没办法,只能通过上下文改变它的能力。
讲到这里大家就会恍然大悟,长上下文其实是一个退而求其次的方案,并不是真正智能的解决方案。
上下文窗口超过100万Tokens也好,200万Tokens也好,1000万Tokens也好……但每时每刻产生的Token远远超过了这个量。就拿今天大会大家分享的内容来说,就已经远远超过了1万Tokens。
记忆能让人形成长期认知,是一个过程。我们的价值观就是记忆逐步积累起来的。如果记忆只靠长上下文,那么就形成不了价值观,更不会有知识沉淀。
人的聪明来自长时间的积累。
回到刚才说的,未来的智能硬件最重要的应该是原生记忆和自主学习。
刚才说了原生记忆,现在来说自主学习,自主学习是一定要走向物理世界的。
自主学习带来的一大好处就是模型不会因为部署就“死亡”了。
可能大家不知道,因为参数已经固定,所以模型在部署的那一刻就死掉了。想要改变,就只能上传到云端服务器重新训练,过一段时间再下发给大家使用。
一旦能够自主学习,随之而来的自主进化就会带来全新的改变。我们就不再认为它是一个固定的工具,而是可以持续学习的。
我们把这种持续学习状态的技术称之为训练和推理同步进行。
训练和推理同步进行,就像我站在这里输出一些内容(可以看成大模型的推理过程)的时候,也在获得一些新的东西。我的推理和训练是同时完成的。大脑不仅在推理,参数也在不断改变,这就是“活”的东西。
今天发布了一个模型,过三个月再去问这三个月里发生的事情,它是不知道的,需要通过知识外挂RAG等方式弥补。这不是临时方案是什么?
我们作为研究者,应该要面临这样的现实——
大模型的很多方案都是临时方案,并不是真正的终局方案,终局方案就是要改架构。
我自己的观点是这样的:人工智能要往下发展到更高的台阶,一定要突破两个大山,第一座大山是Transformer,第二座大山是反向传播算法(反向传播算法制约了现在很多设备的发展,包括算力的发展)。
为了让模型不再死亡、能够进化,模型架构一定要改变。
以我们自己研发的Yan架构的大模型为例,整个模型极端稀疏化,激活机制比MoE更稀疏。
它模仿了人类大脑的运行机制。人的大脑大概有860亿参数,但二十几瓦的大脑预算峰值就可以推动大脑运算。

另外,我们在模型中加入了记忆模块。也就是说,推理过程中,随着你跟它沟通,记忆模块会发生改变。所以真正的记忆开始了,真正个性化开始了。
如果一个设备拥有了自主学习,就有了新的可能性。
今年世界人工智能大会我们发布的一个部署了模型的小设备,是一个机器狗,最开始什么能力都没有,但是可以现学现会。我们模型不一定需要云端GPU,手机、CPU上都能直接跑。

这还仅仅是一个简单的机器狗。如果范围更大一点,到具身智能呢?
具身智能现在没办法进入千家万户,核心原因是没法在出厂的时候适应每个家庭,服务好每个家庭。它需要学习。
一个人到了酒店,还得看一下酒店的布局,知道书房在哪里,洗漱间在哪里。
未来设备也是一样,它需要专门了解,有一个学习的过程,而不是出厂的时候就会用所用家电了。这个学习的过程是Transformer架构现在很难具备的。
原生记忆和自主学习带来的变化不仅仅是Token不再收费了,更多的还有智能重新定义硬件的价值。
举个例子。比如说花两万块钱买了一只宠物狗,它陪伴了你两年,你跟它产生了情感依赖。两年之后你还会花两万块钱把它卖掉吗?我想那个时候你肯定不是思考两万块钱的事情,而是更在意狗和你之间产生了多深的情感。
未来的硬件其实需要让用户与它共同创造价值,而不是为它的功能买单。
就像买一部手机,未来为它付费的不是内存,是与它的价值共创。你买它的时候它的价值是最小的时候。
所以我们认为智能会重新定义硬件的价值,它就不再只是一个工具了。
我们的模型能够在手机、具身智能等设备上灵活运行。比如在手机上部署的3B的离线模型,保证了用户的隐私和安全,体验还非常流畅。
特别强调的是,在离线情况下,多模态感知能具备记忆和自主学习能力,那么硬件价值一定会发生很大变化。这也是全新架构带来的全新可能。
Transformer几乎不可能做到这个水平。因为手机上运行它会消耗很高的内存资源。
当硬件拥有了原生记忆和自主学习,还会发生什么样的变化?
不同于OpenAI,也不同于DeepSeek,我们认为这条路径是群体智能。
每一台设备都拥有了自己的智能,此外还能向物理世界进行学习的时候,就会产生群体智能。
群体智能有点像人类社会。每个人都不是全能的,我们不需要造一个全能的人,更不需要人人都全能。大家只需要有自己擅长的点就可以了。
更多智能来自于相互之间的合作,合作过程中会产生真正的知识。

知识有两部分:一个叫产生,一个叫传播。
现在大模型——尤其是Transformer架构大模型——有很大的一个问题,它本身没有产生知识。
真正的智能应该是产生知识。人与人之间随时在产生知识,正是因为每个人的不同产生了不同的解决方案。
真正的智能涌现来自于每个个体,每个个体产生信息之后,再传播给更多的人。我们是在这样的过程中形成了人类逐步发展的文明,而不是靠一个足够聪明的云端通用大模型来造神。
云端通用大模型的厉害之处无非在于收集的数据,而收集的数据无非来自于人类社会的经验。如果它连自己原生的记忆和自主学习都不具备,是不可能产生真正的智能。
RockAI一直认为群体智能才是迈向通用人工智能最佳的方式,而不是OpenAI造神的路径。
文章来自于微信公众号 “量子位”,作者 “量子位”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
