# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

现有指令遵循的视频编辑数据集如 InsViE-1M、Senorita-2M、Ditto-1M 主要存在数据集规模小、编辑类型少、编辑指令短和编辑质量差四个问题。表 1 展示了现有开源视频编辑数据集的定量分析,其中尽管 VIVID 有 10M 的数据规模,但是其只提供了掩码视频而没有编辑后视频导致无法直接训练。而 InsViE-1M、Senorita-2M、Ditto-1M 三个数据集只有 1 或 2M 的样本数,并且编辑种类较少。
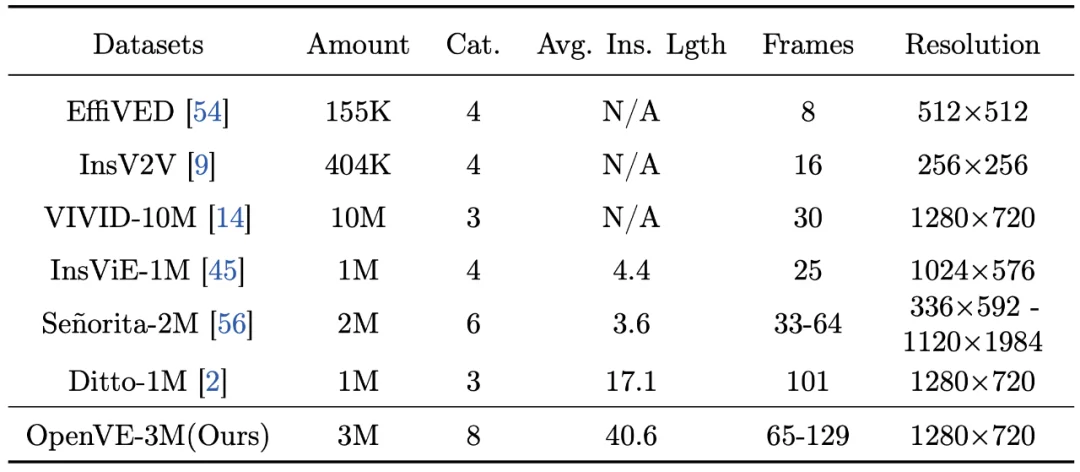
表 1: 与当前指令跟随视频编辑数据集的比较。Cat./Avg. Ins. Lgth 分别指类别 / 平均指令长度
图 2 (a) 展示了编辑指令长度的分布,InsViE-1M、Senorita-2M 的平均编辑指令的单词长度较少平均只有 4 个单词,无法很好的提供准确的编辑指令信息影响编辑效果。为了判断指令跟随的视频编辑数据集的质量,作者将原始视频、编辑后视频和编辑指令输入至 Gemini 2.5 Pro 中并在 Consistency & Detail Fidelity, and Visual Quality & Stability 三个层面进行 1 到 5 打分,其中后两者的得分不应该超过前者。将每个数据集中的每个类别随机挑选 50 个编辑对进行评测,最终得分分布如图 2 (b) 所示。
InsViE-1M、Senorita-2M 数据集尽管在 5 分也有较高的分布,但是其为 1 分的 bad case 占比也很高,导致数据集的平均质量得分偏低。Ditto 数据集也有着不错的质量但是其主要编辑类型为风格的变换,编辑种类还不够丰富。综上所述,目前还缺少大规模、高质量、多种类的指令跟随的视频编辑数据集。
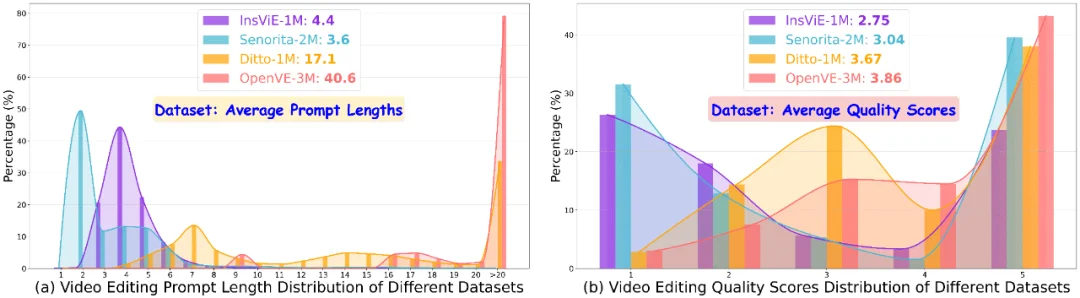
图 2: OpenVE-3M 与当前开源视频编辑数据集的视频统计数据比较
因此,作者提出了一个大规模、高质量、多类别的指令跟随视频编辑数据集 OpenVE-3M。其共包含 3M 个样本,分为空间对齐和非空间对齐两类,其中空间对齐指的是编辑后视频和原始视频在空间和时序上具有一致的运动包括 Global Style, Background Change, Local Change, Local Remove, Local Add, and Subtitles Edit 共 6 类,非空间对齐指的是编辑后视频和原始视频在空间和时序上具有一致的主体但不一致的运动包括 Camera Multi-Shot Edit and Creative Edit 共 2 类。所有类别的可视化例子如图 1 所示。此外 OpenVE-3M 还具有最长的平均指令长度 40.6,分布均匀的视频帧数以及最高的视频编辑质量总平均分 3.86。

图 1: 在同一个视频中演示来自所提出的 OpenVE-3M 数据集的八个不同类别
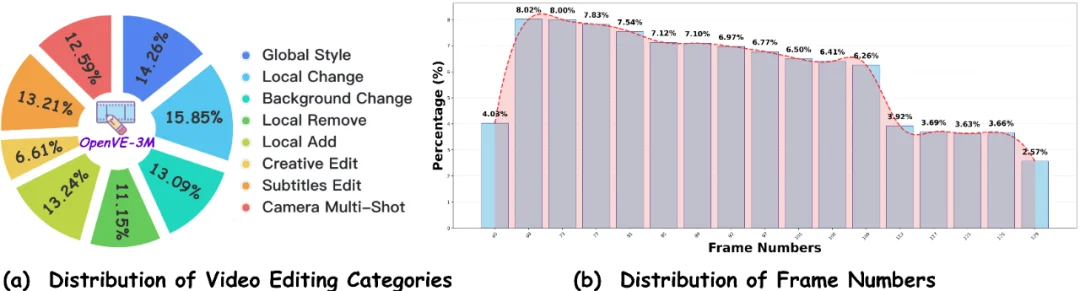
图 3: OpenVE-3M 的类别和帧计数统计
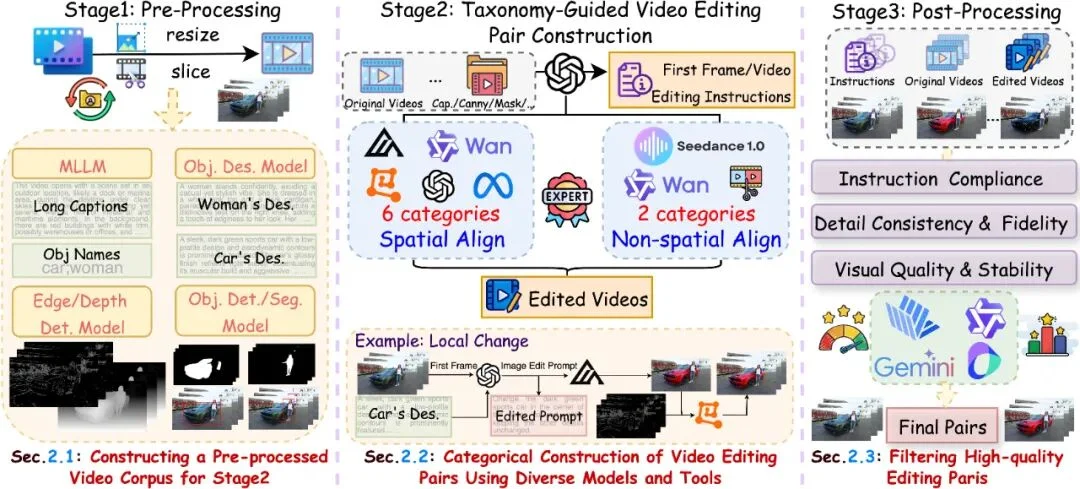
图 4: 数据管道概述。第一阶段:旨在构建视频语料库并执行各种预处理步骤,为第二阶段做准备。第二阶段:重点在于利用一系列模型和工具,为每个类别生成编辑对。第三阶段:涉及对第二阶段生成的所有编辑对进行细粒度过滤,以仅保留高质量样本。

图 5: Stage1 视频数据预处理管道
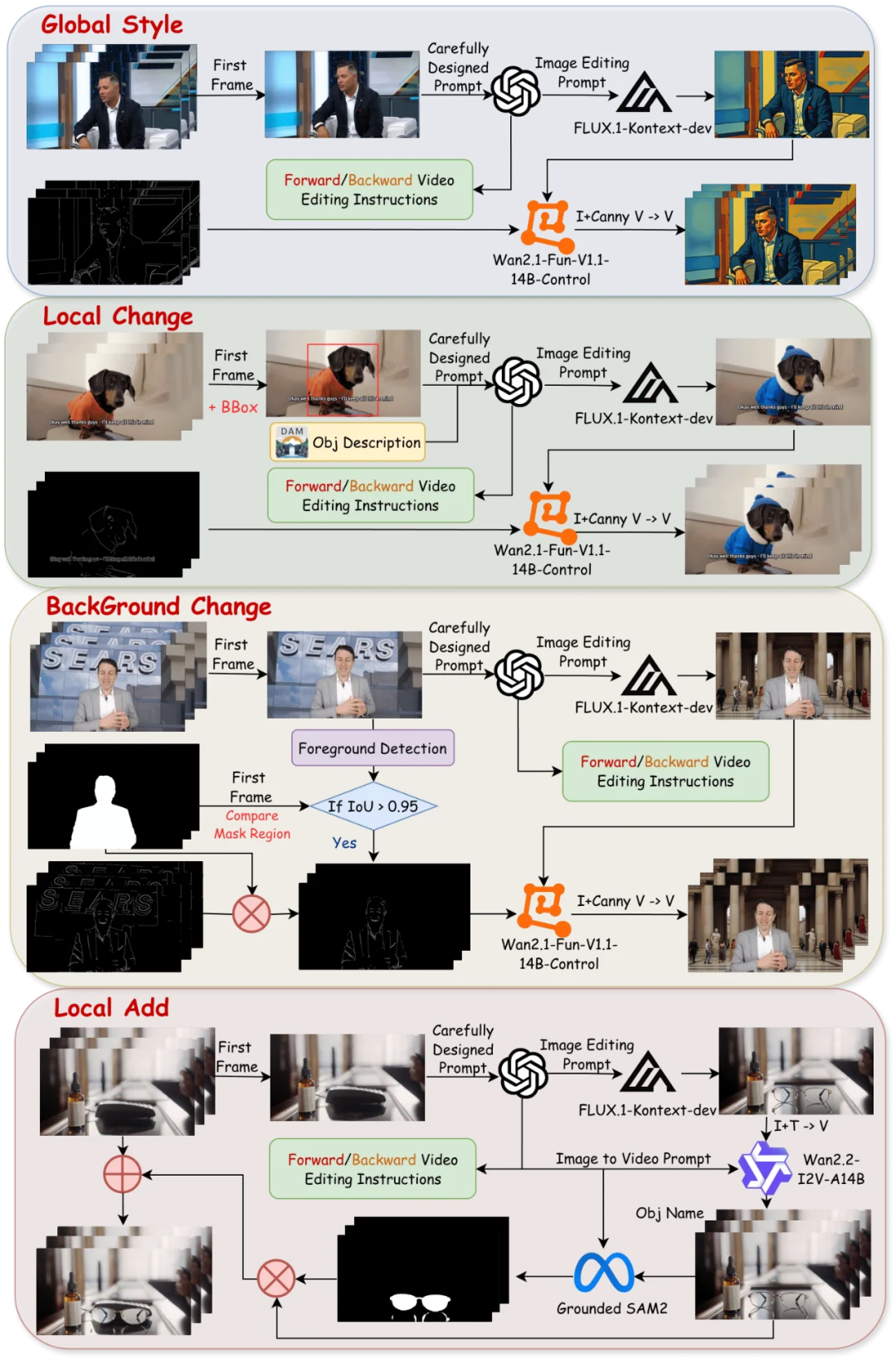
图 6: Stage2 视频编辑数据构建流程的详细工作流程: Global Style, Local Change, Background Change, and Local Add

图 7: Stage2 视频编辑数据构建流程的详细工作流程: Local Remove, Subtitles Edit, Camera Multi-shot Edit, and Creative Edit
对于所有类别的合成数据对作者针对每个类别精细设计了数据过滤管道。首先是每个类别视频编辑提示词的精细构建,共包含 3 大主要评测指标:指令遵循、Consistency & Detail Fidelity 和 Visual Quality & Stability,每个指标评分 1-5 分进行打分。
其中关键的是以指令遵循指标为得分上限,即后面两个指标的得分不能超过指令遵循指标。因为有许多视频编辑数据尽管视频质量高但完全没有被编辑,因此作者希望指令遵循是首要评判标准。随后作者将编辑指令、编辑前视频和编辑后视频输入到 VLMs 中进行打分。在此,作者人工挑选并打分了 300 个视频编辑对并与 3 个 VLMs 模型打分结果进行对比。将视频编辑对平均得分超过 3 分定义为正样本、小于等于 3 分为负样本。最终计算 Qwen3-VL-A3B 模型准确率为 61%,Intern3.5-VL-38B 模型准确率为 66%,Seed1.6-VL 准确率为 70%,Gemini2.5-Pro 准确率为 69%。但是受限于 Seed1.6-VL 和 Gemini2.5-Pro 的 API TPM 的限制,作者最终选用 Intern3.5-VL-38B 模型用于打分并过滤所有得分大于 3 分的视频编辑对。
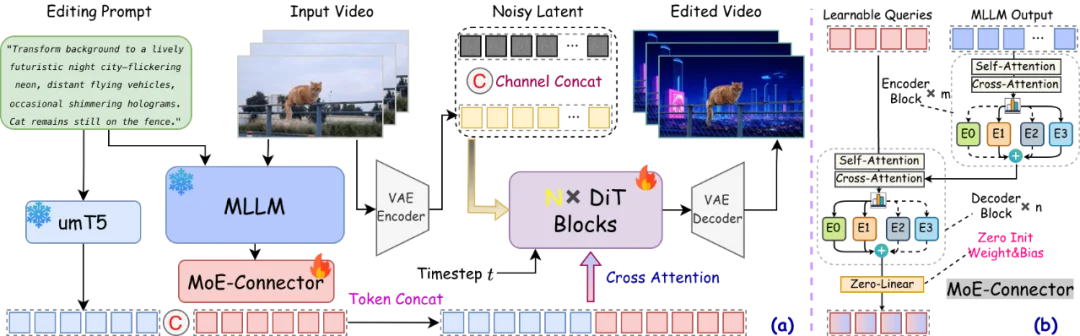
图 8: OpenVE-Edit 的整体架构。(a) OpenVE-Edit 的架构。(b) MoE-Connector 模块的详细结构。
OpenVE-Edit 创新点:
现在还没有一个通用的并且与人类评价高度对齐的指令跟随的视频编辑评测。因此,作者提出了 OpenVE-Bench,一个人工精心挑选包含 8 类别共 431 条编辑对的评测集,并且对于每个类别均精心设计了 Instruction Consistency & Detail Fidelity, and Visual Quality & Stability 三个关键评测 Prompt,最终将编辑指令、原始视频、编辑后视频共同输入给 VLM 得到编辑分数。
作者对比了目前所有的视频编辑开源模型 VACE、OmniVideo、InsViE、ICVE、Lucy-Edit、DITTO 和闭源模型 Runway Aleph,在使用 80G 显存 GPU 复现开源模型过程中。OmniVideo 仅能生成 640*352 分辨率,17 帧的视频,其他分辨率和帧数都会导致视频异常。ICVE 模型仅能在 480*768 分辨率生成最多 41 帧的视频,更多帧数的生成会导致显存爆炸,因此使用 384*240 以保证所有帧被编辑。其他的模型都按照其训练的分辨率和输入视频的帧数对应进行生成。另外由于 Runway Aleph 费用的限制,作者在每类评测集上仅挑选 30 个样本进行测试与评分。
表 2 和 3 展示了现在所有指令跟随视频编辑模型在 OpenVE-Bench 上的评测结果。闭源的 Runway Aleph 模型在 Seed1.6VL 和 Gemini 2.5 Pro 两个评测模型上均取得了最出色的效果并且远超现有开源模型。开源的 VACE、OmniVideo 和 InsViE 由于模型参数的限制或者数据集的限制结果较差。Lucy-Edit 在 5B 的参数量下取得了比较平均的效果。ICVE 在 13B 参数量下取得了不错的效果,但高分辨率的编辑仅支持更少的帧数。DITTO 由于数据集主要为 global style 类型,因此其在这一指标上得分较高。作者的 OpenVE-Edit 仅 5B 的参数量取得了 2.41 的总指标,实现较小的参数量下超越了现有所有开源模型效果。
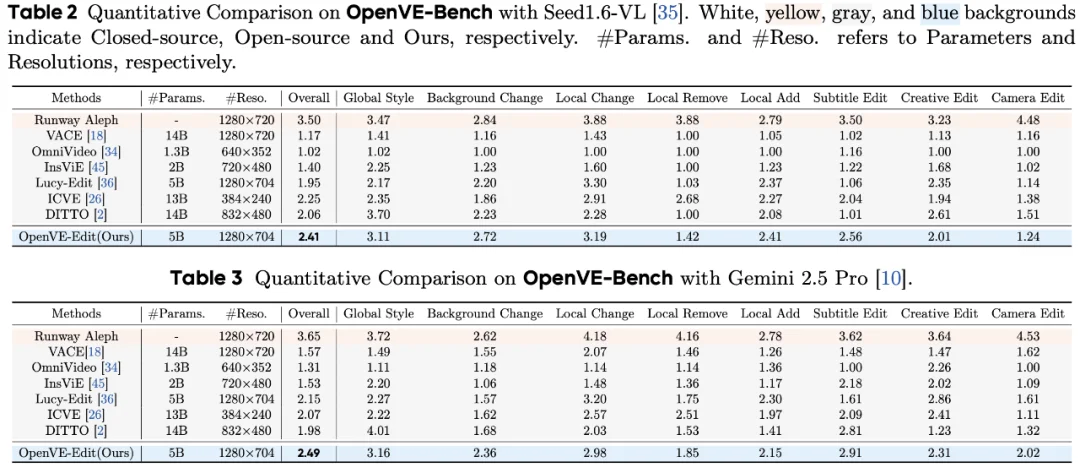
图 9 展示了作者的方法和现有开源 SOTA 方法的定性对比。选取了当前开源模型里最好的三个模型做对比。在左边的 Background Change 的例子里,Lucy-Edit 尽管实现了背景的变换,但是小狗没有保持与原视频一致。ICVE 错误的擦除了女人并且男人的长相也发生了变化。Ditto 错把墙上的画当作前景并且小狗的颜色变深。作者的方法能够在前景所有主体保持一致性的同时背景按照编辑指令改变。右边 Local Change 的例子中,Lucy-Edit 错误的将三个人的衣服全部编辑。ICVE 错误的对左边两个人编辑,并且人也发生了变化。Ditto 不仅编辑错了对象还错误地将背景改变了。作者的方法只按照编辑指令改变了对应女人的衣服并且保持其他男人和背景的一致性。

图 9: 与当前 SoTA 方法的定性比较结果,并举例说明背景变化(左)和局部变化(右)。
文章来自于“机器之心”,作者 “何昊阳”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
