# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
北京大学团队提出了一种新的视觉语义场景补全方法HD²-SSC,用于从多视角图像重建三维语义场景。该方法通过高维度语义解耦和高密度占用优化,解决了现有技术中二维输入与三维输出之间的维度差异,以及人工标注与真实场景密度差异的问题,从而实现更准确的语义场景补全。在自动驾驶数据集SemanticKITT和SSCBench-KITTI-360上,HD²-SSC均取得了当前最优性能。
视觉语义场景补全旨在从多视角图像中重建完整的三维语义场景,即预测空间中每个体素的几何占用状态与语义类别,实现对复杂环境的精细感知与重建,在自动驾驶、机器人导航等场景中具有重要的研究和应用价值。
然而,现有视觉语义场景补全方法往往忽视了自动驾驶道路场景中2D输入和3D输出之间的维度差异,以及人工标注和真实场景之间的密度差异,难以准确预测立体视角下的密集场景补全结果。
针对这一问题,北京大学彭宇新教授团队提出了「高维度-高密度」语义场景补全方法HD²-SSC,首先通过高维度语义解耦将平面图像特征扩展为伪体素化特征与立体场景特征进行对齐;然后通过高密度占用优化增强三维场景的信息密度,补全和修正错误体素预测,实现准确的语义场景补全。

论文链接:https://arxiv.org/abs/2511.07925
代码仓库:https://github.com/PKU-ICST-MIPL/HD2-AAAI2026
实验室网址:https://www.wict.pku.edu.cn/mipl
HD²-SSC在两个常用自动驾驶数据集SemanticKITT和SSCBench-KITTI-360上均取得了当前最优的性能。
语义场景补全任务旨在从多视角图像或稀疏点云中重建完整的三维语义场景,为下游任务提供体素级别的场景理解。
近年来,视觉语义场景补全方法由于图像传感器在实际应用场景中部署的低成本和灵活性,逐渐成为研究热点。
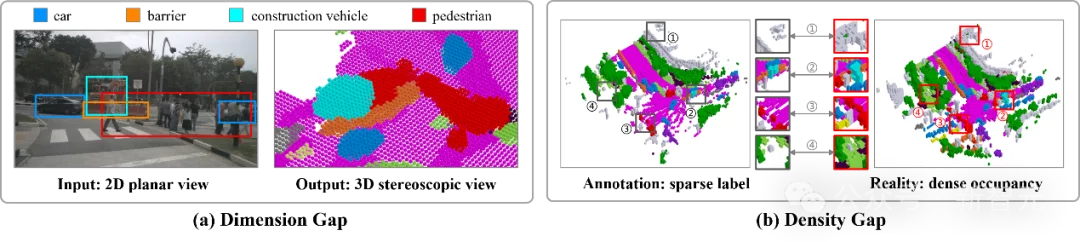
视觉语义场景补全任务中的维度差异和密度差异
研究人员分析了现有视觉语义场景补全方法所面临的挑战,如图1所示:
1. 维度差异:输入的图像数据从二维平面视角捕获,导致被物体遮挡所混淆的粗糙像素语义;然而,语义场景补全任务要求输出三维立体视角下的细粒度体素语义,准确分离输入图像中的遮挡物体。
2. 密度差异:基于激光雷达传感器的人工标注因为点云的分辨率有限,导致具有间隙的稀疏标签;然而,真实道路场景呈现密集且连贯的空间占用,具有远高于人工标注的语义信息密度。
为解决视觉语义场景补全中的维度差异和密度差异问题,研究人员提出了高维度-高密度语义场景补全方法HD²-SSC。
HD²-SSC主要包含两个阶段:
1. 首先针对维度差异难点,提出高维度语义解耦,利用伪体素化模块将粗粒度像素语义扩展为细粒度体素化语义特征,并通过语义聚合模块对全局细粒度语义进行聚类和整合,实现像素和体素语义的对齐;
2. 然后针对密度差异难点,提出高密度占用优化,采用“检测-优化”架构,通过粗粒度预测提取密度分数,然后利用几何密度优化模块识别并对齐几何和语义关键体素,确保上下文几何与语义信息的一致性,增强局部辨识性信息密度,实现准确的语义场景补全。
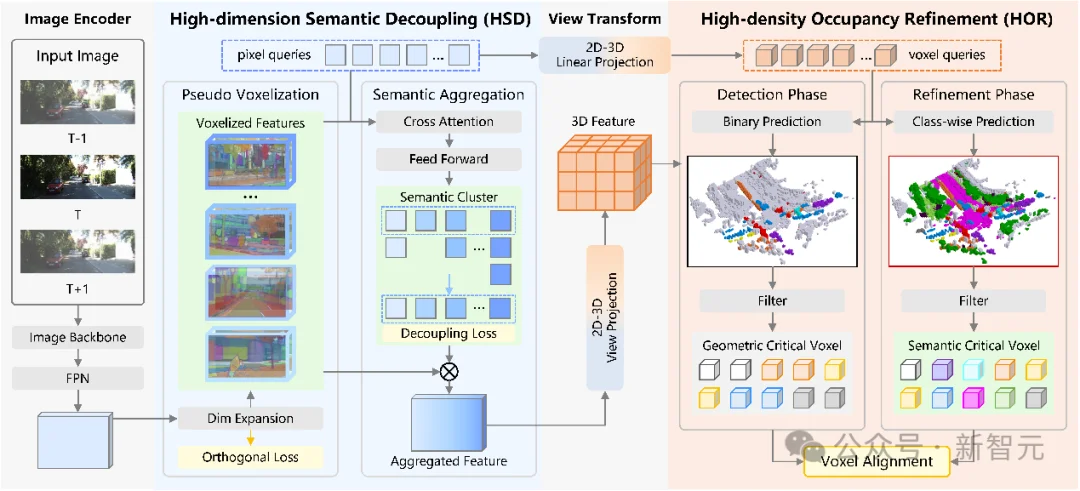
高维度-高密度语义场景补全(HD²-SSC)框架图
首先,给定从图像编码器中提取的图像特征,使用一个维度扩展层将其沿一个伪「语义维度」提升为伪体素化特征:
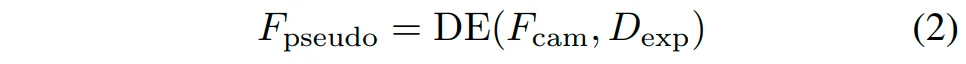
其中,表示用于进行图像特征维度扩展的二维卷积网络,表示扩展维度的通道数。同时,采用正交损失进一步促进伪体素化语义之间的差异性,提升其泛化到不同被遮挡物体的能力:
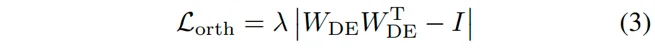
其中,表示维度扩展层的权重矩阵,表示单位矩阵,表示正则化参数。然后,引入像素查询,通过交叉注意力机制从伪体素化特征中提取全局语义,并进行语义聚类:
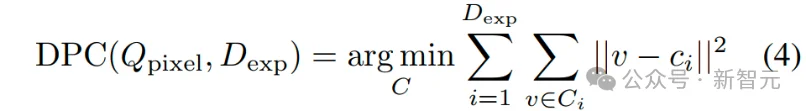
其中,表示与扩展维度对应的个语义特征聚类,表示第个聚类的聚类中心。同时采用一个解耦损失来增强不同语义聚类簇之间的区分度:
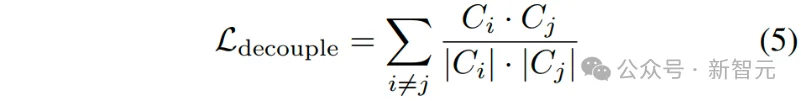
最后,根据伪体素化特征与各语义聚类簇之间的相似度来定位其辨识性区域,实现对全局高维度细粒度语义特征的聚合:
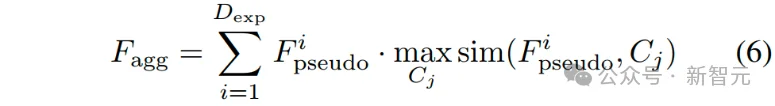
其中,表示最终的聚合语义特征。
采用「检测-优化」架构,在检测阶段,由像素查询映射得到的体素查询和通过视角转换得到的体素特征被送入一个启发式二元分类头,检测被占用的体素,同时对前景和背景体素进行区分:
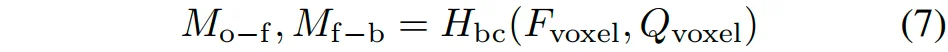
然后,筛选具有最高分数的体素作为几何关键体素:
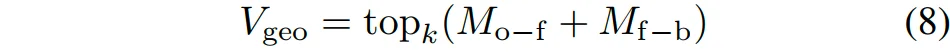
其中,是所选关键体素的数量。在优化阶段,首先使用体素查询和体素特征进行逐类预测,生成初始的语义场景补全结果:
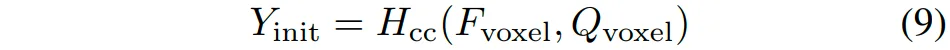
根据分类置信度筛选语义关键体素:
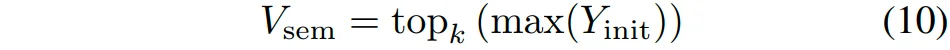
最后,对齐几何和语义关键体素的整体分布,促进上下文语义和几何信息的一致性,增强局部辨识性信息密度:
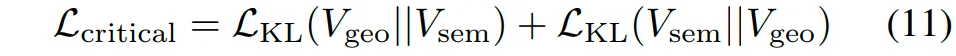
对齐后的几何和语义关键体素提供了上下文的互补信息,用于优化初始的语义场景补全结果:
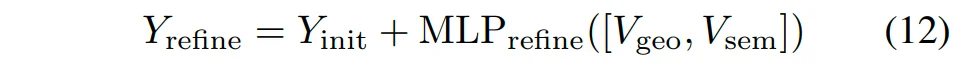
其中,表示优化得到的最终语义场景补全结果。
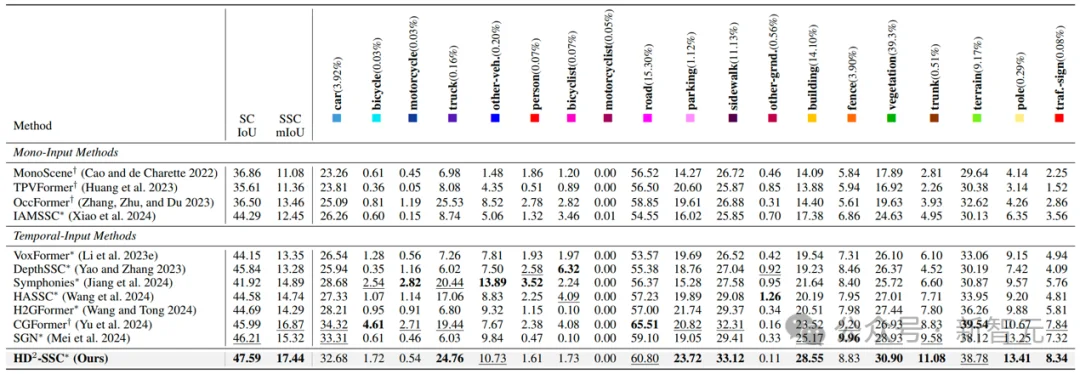
表1 高维度-高密度语义场景补全(HD²-SSC)实验结果1(SemanticKITTI)
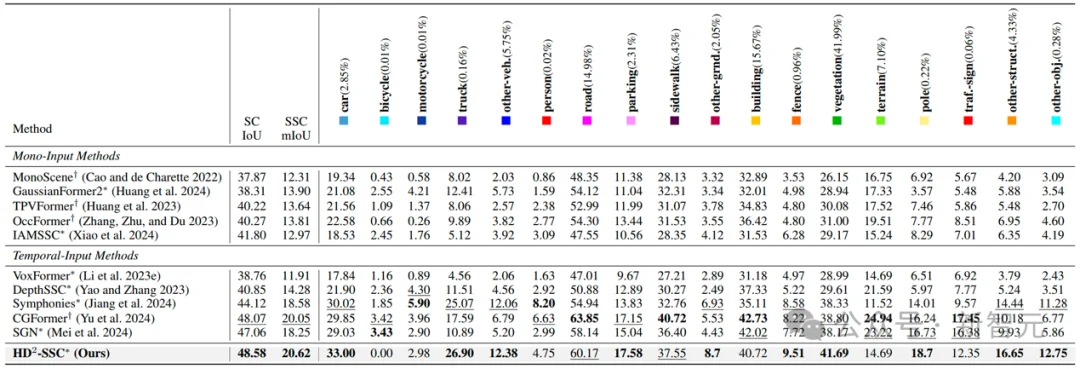
表2 高维度-高密度语义场景补全(HD²-SSC)实验结果2(SSCBench-KITTI-360)
表1和表2的实验结果表明,HD²-SSC在2个常用自动驾驶数据集SemanticKITTT和SSCBench-KITTI-360上均达到了当前最优的性能,相比浙江大学提出的SGN方法分别取得了1.38%IoU,2.12%mIoU和1.52%IoU,2.37%mIoU的性能提升。
可视化结果表明,相比于SOTA对比方法SGN,HD²-SSC方法能够生成具有更准确语义信息和更真实几何结构的三维占用预测结果。
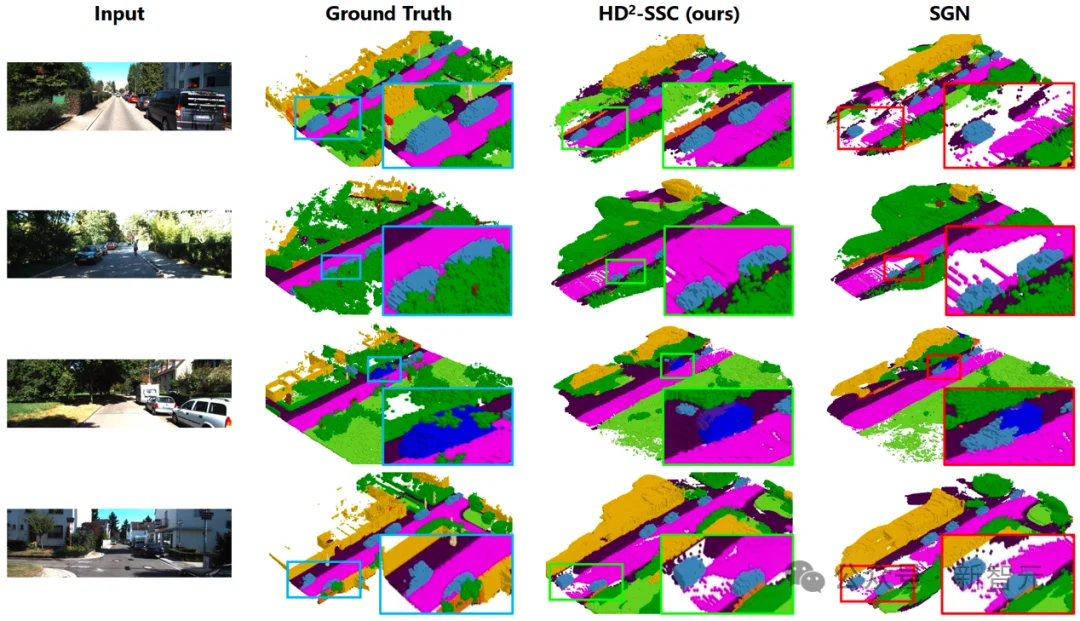
高维度-高密度语义场景补全(HD²-SSC)可视化案例展示
参考资料:
https://arxiv.org/abs/2511.07925
文章来自于“新智元”,作者 “LRST”。


