# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
LeCun 的联合嵌入预测架构(JEPA)迎来了新进展。
近日,来自 Meta、香港科技大学、索邦大学、纽约大学的一个联合团队基于 JEPA 打造了一个视觉-语言模型:VL-JEPA。
据作者 Pascale Fung 介绍,VL-JEPA 是第一个基于联合嵌入预测架构,能够实时执行通用领域视觉-语言任务的非生成模型。

下面展示了一段该模型实时工作的视频:

不同于传统的视觉-语言模型(VLM)通过自回归方式生成 token,VL-JEPA 预测的是目标文本的连续嵌入(embedding)。通过在抽象的表征空间中学习,该模型能够专注于与任务相关的语义,同时忽略表层语言形式的多变性 。

该论文共有四位共一作者:Delong Chen(陈德龙)、Mustafa Shukor、Théo Moutakanni、Willy Chung。JEPA 提出者、图灵奖得主 Yann LeCun 也在作者名单中。
理解周围的物理世界是高级机器智能最重要的方面之一。这种能力使 AI 系统能够在现实世界中学习、推理、规划和行动,从而协助人类。
需要在现实世界中行动的智能系统包括可穿戴设备和机器人。构成这一能力的机器学习任务包括描述生成(captioning)、检索、视觉问答、动作跟踪、推理和规划等。用于此类现实世界应用的系统必须具备实时响应能力,且具有低延迟和低推理成本。
目前,完成这些任务的通用方法是使用基于 token 生成的大型视觉 - 语言模型(VLM)。
这些模型接收视觉输入 X_V 和文本查询 X_Q,在 token 空间中自回归地生成所需的文本响应 Y,即 (X_V,X_Q)↦ Y。这种方法虽然直观,但也有不足,原因主要有二:
这个联合团队开发的视觉-语言联合嵌入预测架构(VL-JEPA)能将昂贵的数据空间 token 生成学习转变为更高效的潜空间语义预测。
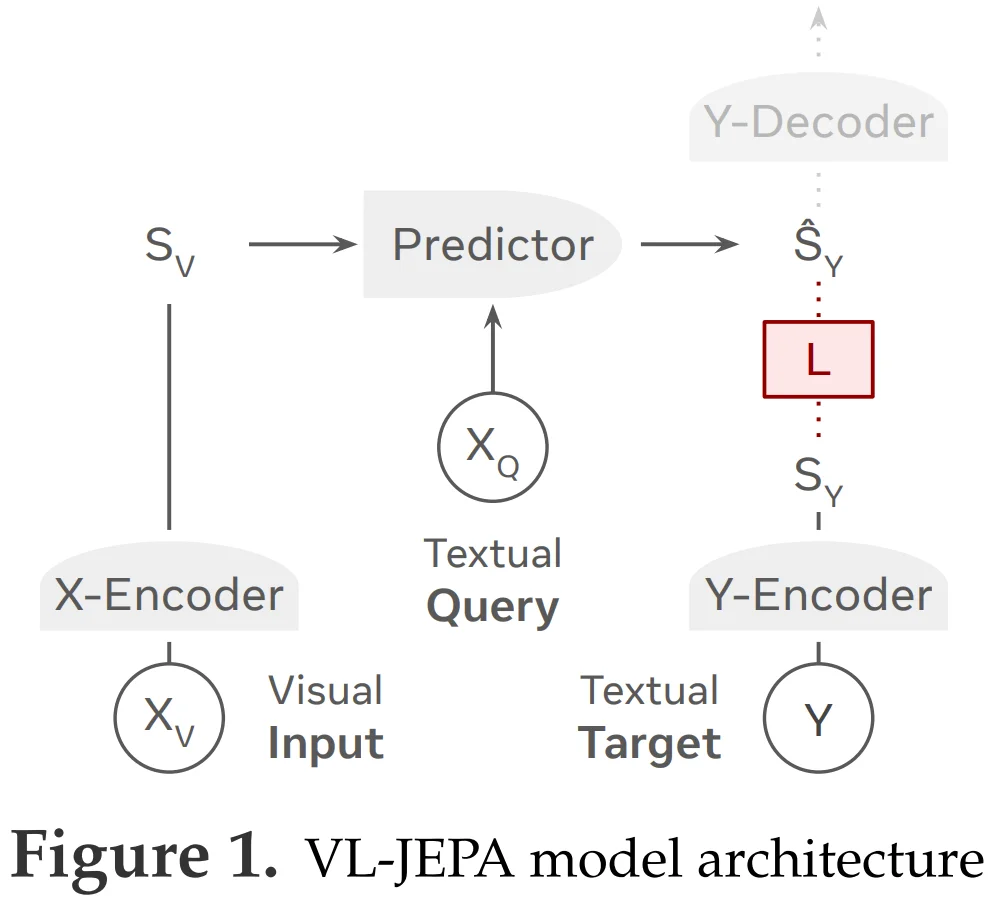
如图 1 所示,该模型会使用 x-encoder 将视觉输入 X_V 映射为嵌入 S_V,使用 y-encoder 将目标文本 Y 映射为嵌入 S_Y,并使用一个预测器来学习映射 (S_V,X_Q)↦ S_Y,其中 X_Q 是文本查询(即提示词)。
训练目标定义在嵌入空间 𝓛_{VL-JEPA}=D (Ŝ_Y,S_Y),而不是数据空间 𝓛_VLM=D (Ŷ,Y)。在推理过程中,当需要时,y-encoder 会将预测的嵌入 Ŝ_Y 读出为文本空间 Ŷ。
得益于其非生成式的特性,VL-JEPA 不必在 token 空间重建 Y 的每一个表层细节。相反,它只需要在嵌入空间预测抽象表征 S_Y。
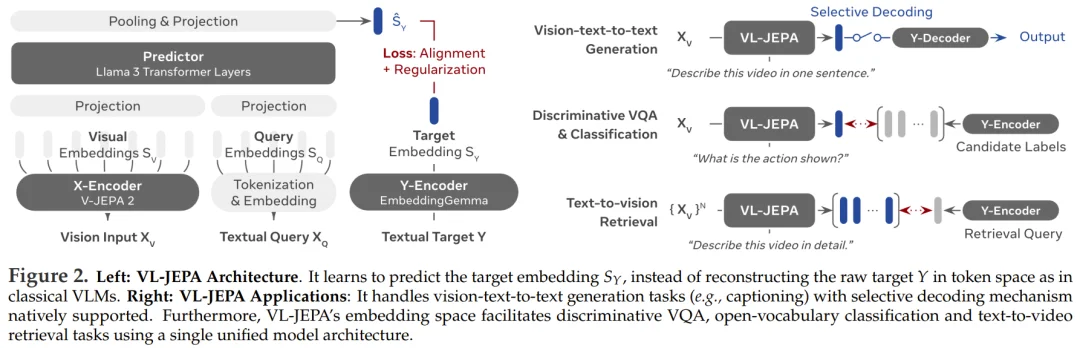
在原始的 One-hot token 空间中,对于同一输入,不同的合理输出 Y 如果不共享重叠的 token,往往看起来几乎是正交的。然而,在嵌入空间中,这些多样化的目标可以被映射到共享相似语义的邻近点。
这就简化了目标分布,从而使学习过程更加高效。此外,与 VLM 不同,这种方法消除了在训练期间使用重型解码器学习语言生成的需要,从而显著提高了效率。
同时,得益于其非自回归的特性,VL-JEPA 可以在滑动窗口内以极低的延迟产生连续的目标语义嵌入流,因为它只需要一次前向传递,无需自回归解码。
这对实时在线应用(如实时动作跟踪、场景识别或规划)特别有利,在这些应用中,嵌入流可以被轻量级的 Y-Decoder 选择性地解码,从而实现高效且及时的更新。
VL-JEPA 的优势也得到了实验验证。
该团队将其与经典的 token 生成式 VLM 进行了比较 :两种设置使用相同的视觉编码器、空间分辨率、帧率、训练数据、批量大小和迭代次数等,唯一的区别在于目标是在 token 空间还是嵌入空间。
在这种匹配的训练条件下,VL-JEPA 在零样本描述生成和分类上提供了一致的更高性能,同时使用的可训练参数大约只有一半,这表明嵌入空间监督提高了学习效率。
除了训练阶段,VL-JEPA 还通过选择性解码(selective decoding)带来了显著的推理效率提升,即仅在预测的嵌入流发生显著变化时才进行解码。
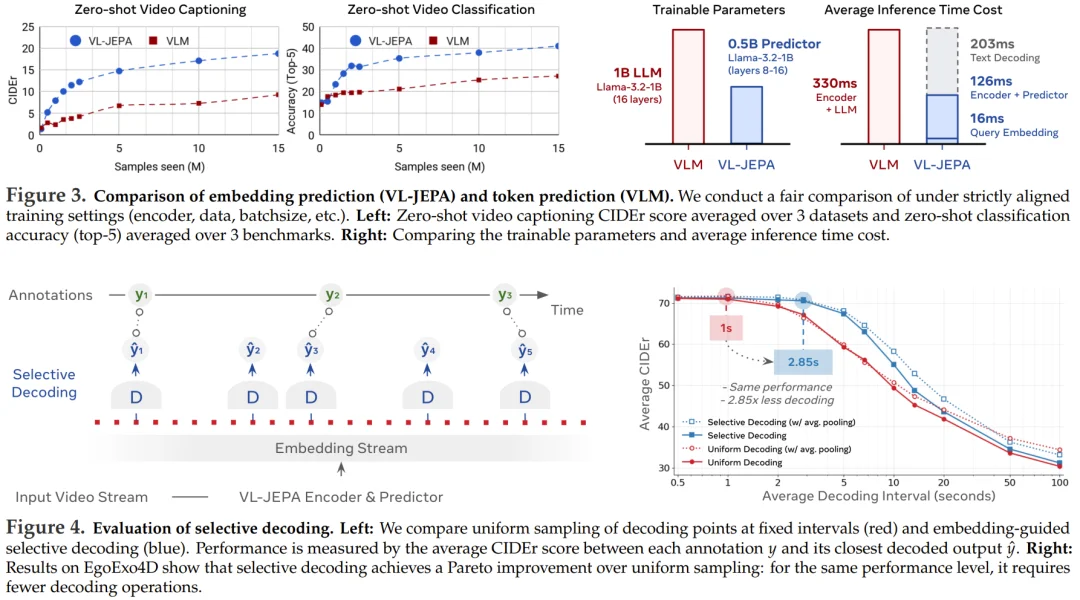
实验表明,该策略将解码操作次数减少了约 2.85 倍,同时保持了以平均 CIDEr 分数衡量的整体输出质量。
该团队最终的 VL-JEPA 模型分两个阶段训练:
第一阶段产生的模型称为 VL-JEPA_BASE,在零样本分类和文本到视频检索方面进行了评估。
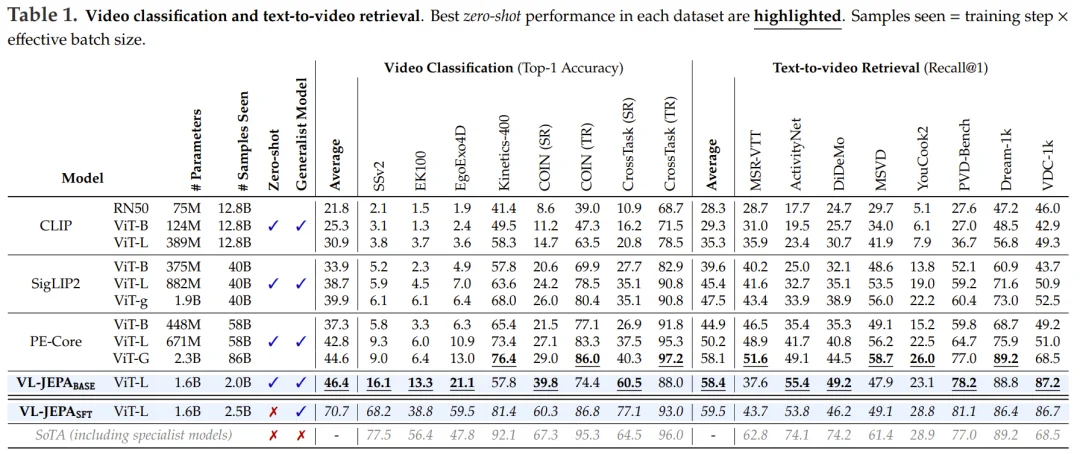
VL-JEPA_BASE 在平均分类准确率(跨 8 个数据集)和检索 recall@1(跨 8 个数据集)方面优于 CLIP、SigLIP2 和 Perception Encoder 模型。
经过第二阶段后,得到的 VL-JEPA_SFT 由于接触了域内训练数据,分类性能显著提高。
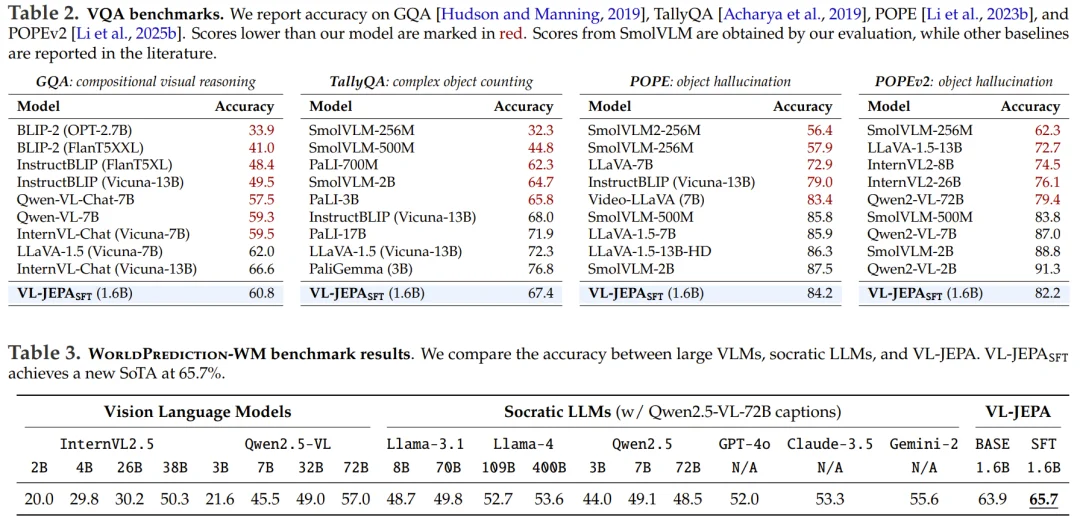
作为一个统一的通用模型,VL-JEPA_SFT 接近了针对单个基准优化的专用模型的性能。同时,VL-JEPA_SFT 展现了有效的 VQA 能力,在涵盖组合视觉推理、复杂对象计数和对象幻觉的四个数据集上,达到了与 InstructBLIP 和 Qwen-VL 等成熟 VLM 系列相当的性能。
以下视频演示了使用 VL-JEPA 进行机器人实时状态跟踪 (RoboVQA):

该团队也进行了消融实验验证 VL-JEPA 各组件的有效性。更多详情请参阅原论文。
文章来自于微信公众号 “机器之心”,作者 “机器之心”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
