AI看图一本正经胡说八道?「一拉一推」让模型看得全又准|微软x清华
AI看图一本正经胡说八道?「一拉一推」让模型看得全又准|微软x清华随着视觉-语言模型(VLM)推理能力不断增强,一个隐蔽的问题逐渐浮现: 很多错误不是推理没做好,而是“看错了”。
来自主题: AI技术研报
8463 点击 2026-02-09 14:56
 搜索
搜索
随着视觉-语言模型(VLM)推理能力不断增强,一个隐蔽的问题逐渐浮现: 很多错误不是推理没做好,而是“看错了”。

近日,来自 Meta、香港科技大学、索邦大学、纽约大学的一个联合团队基于 JEPA 打造了一个视觉-语言模型:VL-JEPA。据作者 Pascale Fung 介绍,VL-JEPA 是第一个基于联合嵌入预测架构,能够实时执行通用领域视觉-语言任务的非生成模型。
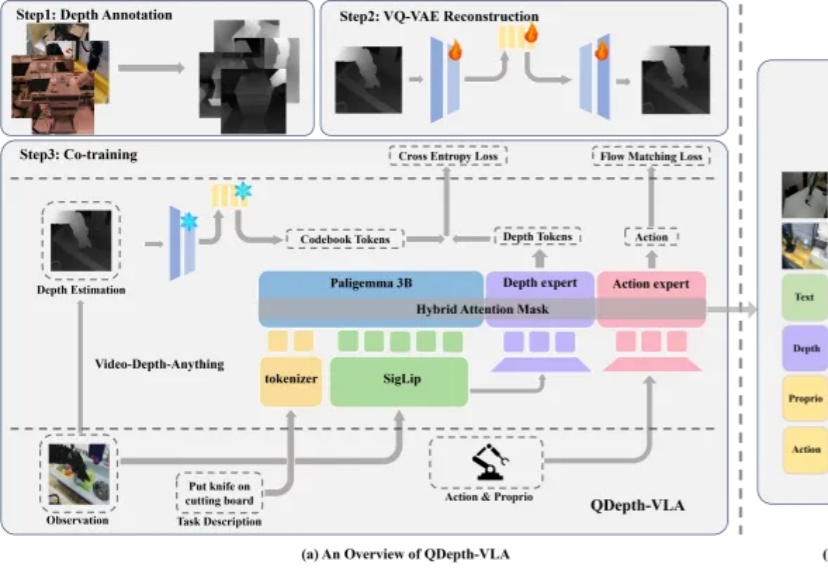
视觉-语言-动作模型(VLA)在机器人操控领域展现出巨大潜力。通过赋予预训练视觉-语言模型(VLM)动作生成能力,机器人能够理解自然语言指令并在多样化场景中展现出强大的泛化能力。然而,这类模型在应对长时序或精细操作任务时,仍然存在性能下降的现象。

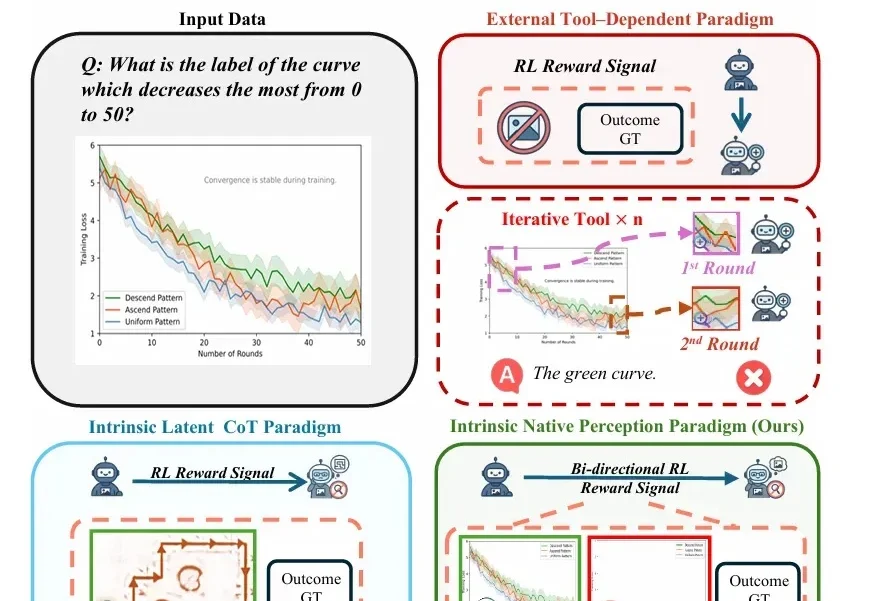
当今的 AI 智能体(Agent)越来越强大,尤其是像 VLM(视觉-语言模型)这样能「看懂」世界的智能体。但研究者发现一个大问题:相比于只处理文本的 LLM 智能体,VLM 智能体在面对复杂的视觉任务时,常常表现得像一个「莽撞的执行者」,而不是一个「深思熟虑的思考者」。
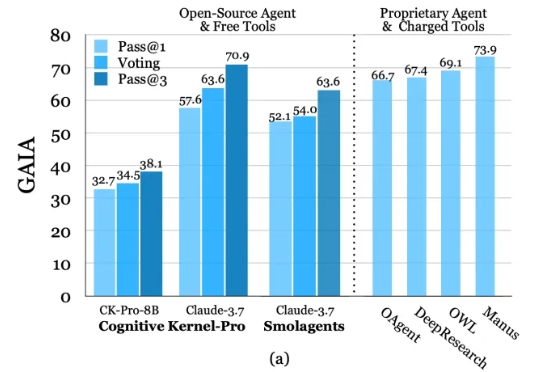
深度研究智能体(Deep Research Agents)凭借大语言模型(LLM)和视觉-语言模型(VLM)的强大能力,正在重塑知识发现与问题解决的范式。
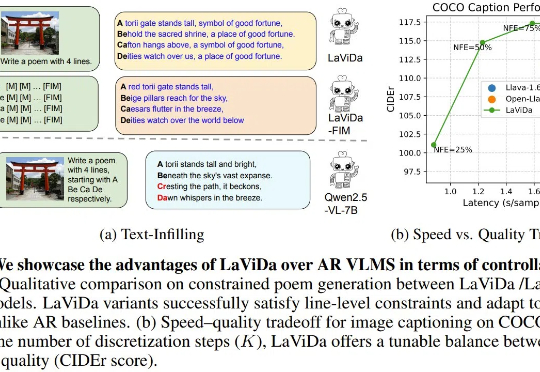
近段时间,已经出现了不少基于扩散模型的语言模型,而现在,基于扩散模型的视觉-语言模型(VLM)也来了,即能够联合处理视觉和文本信息的模型。今天我们介绍的这个名叫 LaViDa,继承了扩散语言模型高速且可控的优点,并在实验中取得了相当不错的表现。
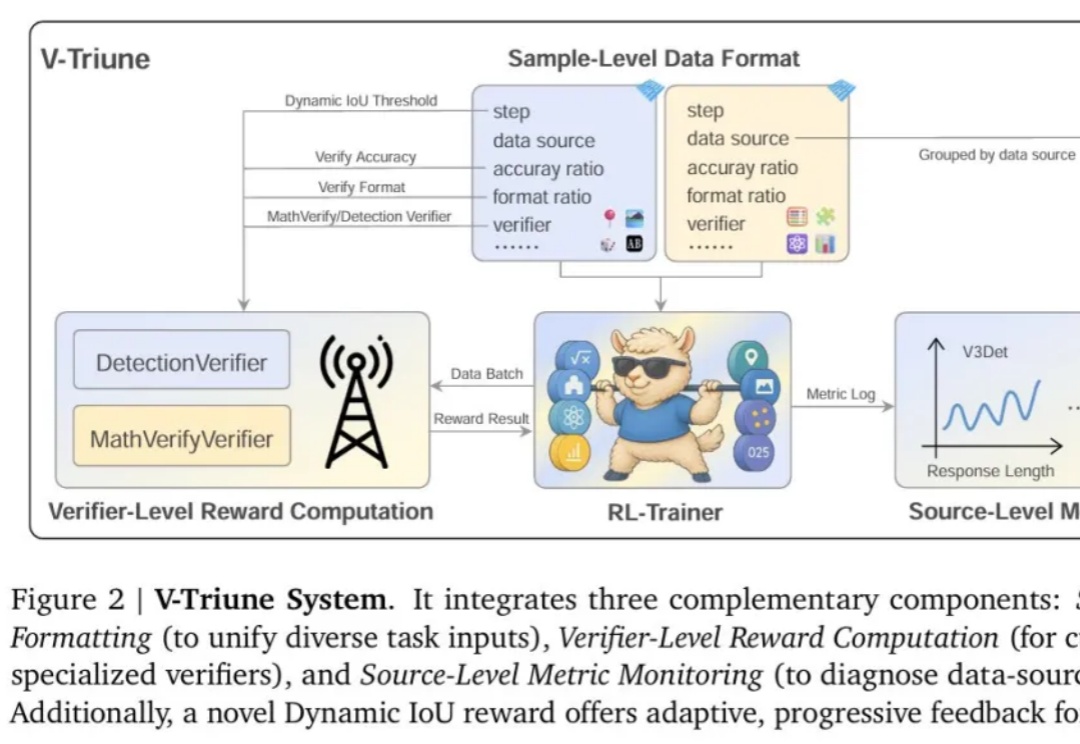
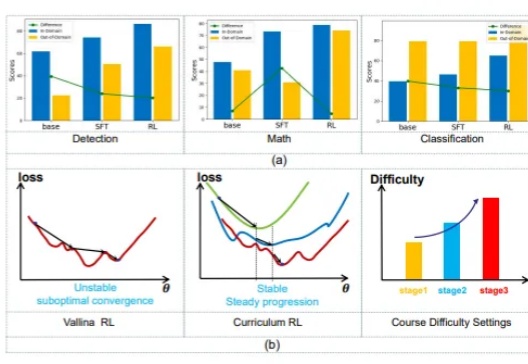
强化学习 (RL) 显著提升了视觉-语言模型 (VLM) 的推理能力。然而,RL 在推理任务之外的应用,尤其是在目标检测 和目标定位等感知密集型任务中的应用,仍有待深入探索。
近年来,随着大型语言模型(LLMs)的快速发展,多模态理解领域取得了前所未有的进步。像 OpenAI、InternVL 和 Qwen-VL 系列这样的最先进的视觉-语言模型(VLMs),在处理复杂的视觉-文本任务时展现了卓越的能力。

幻觉(Hallucination),即生成事实错误或不一致的信息,已成为视觉-语言模型 (VLMs)可靠性面临的核心挑战。随着VLMs在自动驾驶、医疗诊断等关键领域的广泛应用,幻觉问题因其潜在的重大后果而备受关注。

本文提出了一种名为MedUnA的方法,旨在解决医疗图像分类中因缺乏标注数据而导致的监督学习挑战。MedUnA利用视觉-语言模型(VLMs)中的视觉与文本对齐特性,通过无监督学习来适应医疗图像分类任务。