# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在大语言模型和文生图领域,强化学习(RL)已成为提升模型思维链与生成质量的关键方法。
但当我们将目光转向更为复杂的文本到3D生成时,这套方法还会还管用吗?
近期,一项由西北工业大学、北京大学、香港中文大学、上海人工智能实验室、香港科技大学合作开展的研究系统性探索了这一重要问题。

论文链接:https://arxiv.org/pdf/2512.10949
代码链接:https://github.com/Ivan-Tang-3D/3DGen-R1
在LLM推理和2D文生图中,RL已经证明可以显著提升CoT推理能力和生成质量。但3D物体更长、更稠密、更具几何约束。
因此相关方向研究常面临这几个问题:
1. 奖励如何同时刻画语义对齐、几何一致性和视觉质量?
2. 现有RL算法是否适合自回归式3D生成?
3. 缺乏专门考察“3D推理能力”的Benchmark,难以系统评估RL的真实贡献。
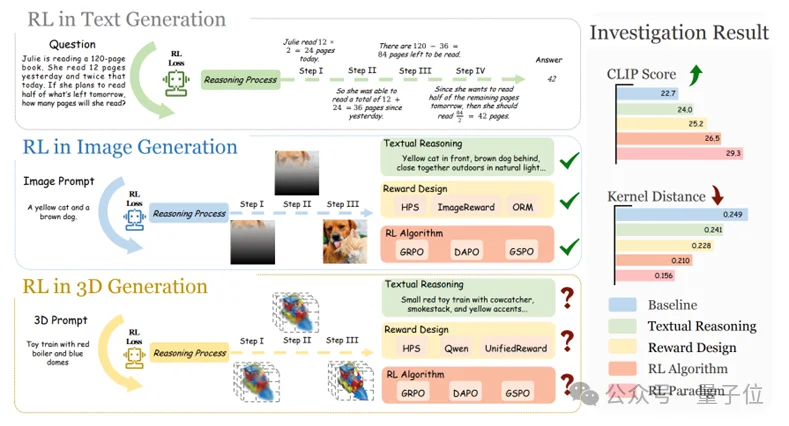

经过系统对比人类偏好、文本对齐、多视图一致性、3D美学等多种奖励组合。研究团队发现:
1)对齐人类偏好信号是提升整体3D质量的关键。其他奖励维度单独使用时带来的提升有限,但在叠加到偏好奖励之上时能够持续带来增益;
2)对于同一奖励维度而言,专门化的奖励模型通常比大型多模态模型(LMMs)表现出更强的鲁棒性。然而,通用多模态模型(Qwen-VL)在3D相关属性上出乎意料地鲁棒,为“低成本奖励”提供可能。
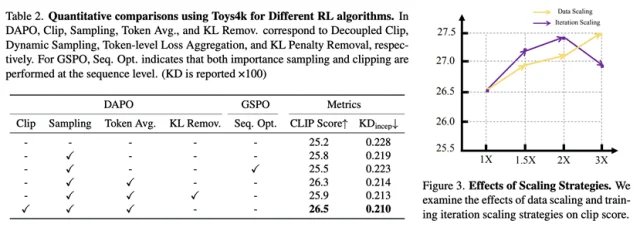
评估GRPO、DAPO、GSPO等在3D自回归生成中的表现。主要Insight:
1)相比序列级操作,3D自回归生成中的强化学习更偏好token级策略。如表2所示,在相同奖励模型配置下,token级平均策略带来的提升显著大于序列级的重要性采样与剪切方法(GSPO)。
2)简单的技巧即可稳定训练,尤其是Dynamic Sampling,只要策略更新受控。完全移除KL惩罚会导致性能下降;而像Decoupled Clip这类更可控的方法,通过鼓励对低概率token的探索,仍能带来性能增益。
3)扩大量级的训练数据能够有效缓解偏好奖励带来的偏差并提升整体表现;适度增加RL迭代也能进一步优化模型,但过度训练可能损害泛化能力。

构建首个针对3D推理场景的系统评测基准MME-3DR:由空间&结构几何,机械可供性与物理合理性,生物/有机形态,长尾稀有实体和风格化/抽象形态五类组成。
MME-3DR希望更关注“在困难约束下是否还能保持一致、合理、可解释”,而非只展示多样性。研究团队发现:
1)近期的Text-to-3D模型在机械结构和非刚性生物体上表现尚可,但在其余三个类别上仍存在明显不足。RL训练在所有五类任务上都带来了显著提升。如图中雷达图所示。
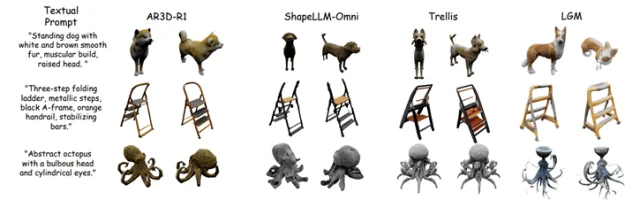
2)MME-3DR能同时评估隐式推理与通用3D生成能力。图中柱状图显示,在随机采样的Toys4K测试集上,Trellis明显优于ShapeLLM-Omni。这一性能差距在MME-3DR中依然保持,进一步验证了其多样化物体覆盖带来的评测有效性。
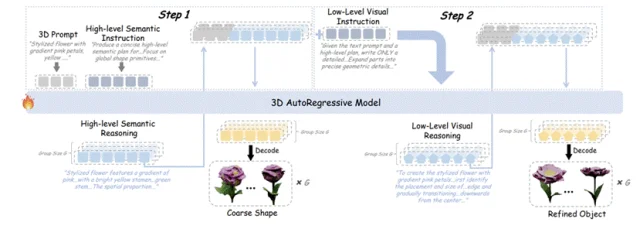
把3D生成看作天然的coarse-to-fine过程:
Step 1:高层语义先决定整体几何骨架;
Step 2:在几何稳定的前提下细化纹理与局部结构。
对两个step团队单独设计专有奖励模型集成进行监督,基于此提出层次化RL范式Hi-GRPO,并实现首个RL加持的Text-to-3D自回归模型AR3D-R1。
1. 不仅仅是“调美观”:
在MME-3DR上,RL训练后的模型在空间几何、一致性和物理可行性等维度都有显著提升,表现出隐式3D推理能力的增强。
2. 范式对齐结构先验很重要:
尊重“先几何、后纹理”的层次结构设计(Hi-GRPO),比简单在最终图像上打分更有效,也更可解释。
3. 性能与稳定性的二元博弈:
奖励过于稀疏或RL迭代数过大,会带来训练不稳和模式坍缩;高质量人类偏好或强多模态奖励,可以在同等训练预算下取得更高回报。
4. 同时,结果清晰的显示出当前模型的能力边界:
对极复杂几何、长尾概念和强风格化场景,模型仍会“逻辑崩坏”;真正可扩展的 3D RL 仍受限于算力与奖励获取成本。


论文标题:Are We Ready for RL in Text-to-3D Generation? A Progressive Investigation
作者单位:西北工业大学、北京大学、香港中文大学、上海人工智能实验室、香港科技大学
文章来自于“量子位”,作者 “3DGenR1团队”。



【开源免费】LGM是一个AI建模的项目,它可以将你上传的平面图片,变成一个3D的模型。
项目地址:https://github.com/3DTopia/LGM?tab=readme-ov-file
在线使用:https://replicate.com/camenduru/lgm
