# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
参数越小,智商越高?Gemini 3 Flash用百万级长上下文、白菜价成本,把自家大哥Pro按在地上摩擦。谷歌到底掏出了什么黑魔法,让整个大模型圈开始怀疑人生?
Gemini 3 Flash发布已经有段时间了,速度快3倍的同时智力反超Pro。
但是目前依然没人能够说明白:为啥Flash能比Pro还要「聪明」。
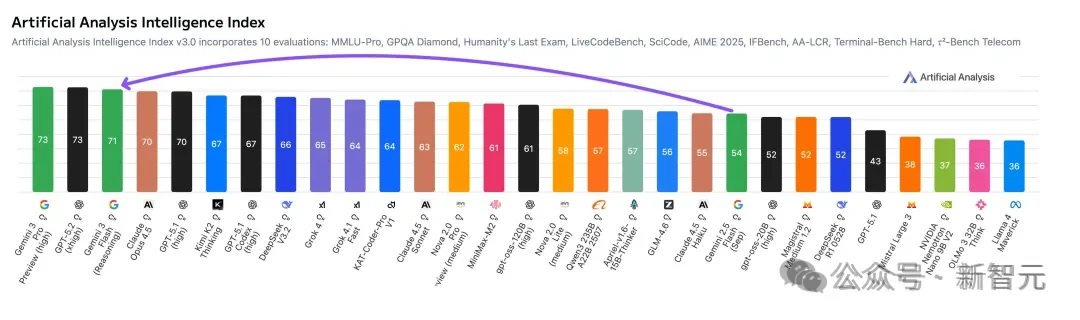
为何一个在参数规模上显著缩减的模型,能够在更大规模的模型擅长的领域实现超越?
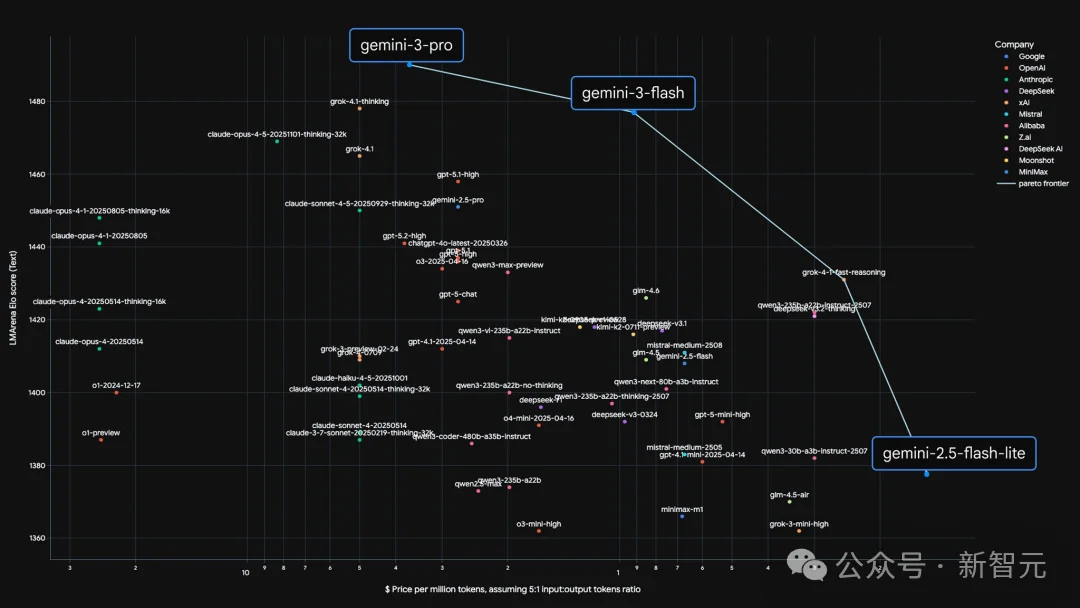
长期以来,业界奉行着「参数即正义」的信条,认为更大的模型(更多的参数量)必然带来更强的智能表现。
然而,Gemini 3 Flash的出现打破了这一线性逻辑,它不仅在成本和速度上保持了「Flash」系列的轻量级特征,更在多项关键基准测试中,尤其是涉及复杂推理和超长上下文的任务上,击败了前一代甚至当代的「Pro」级模型。
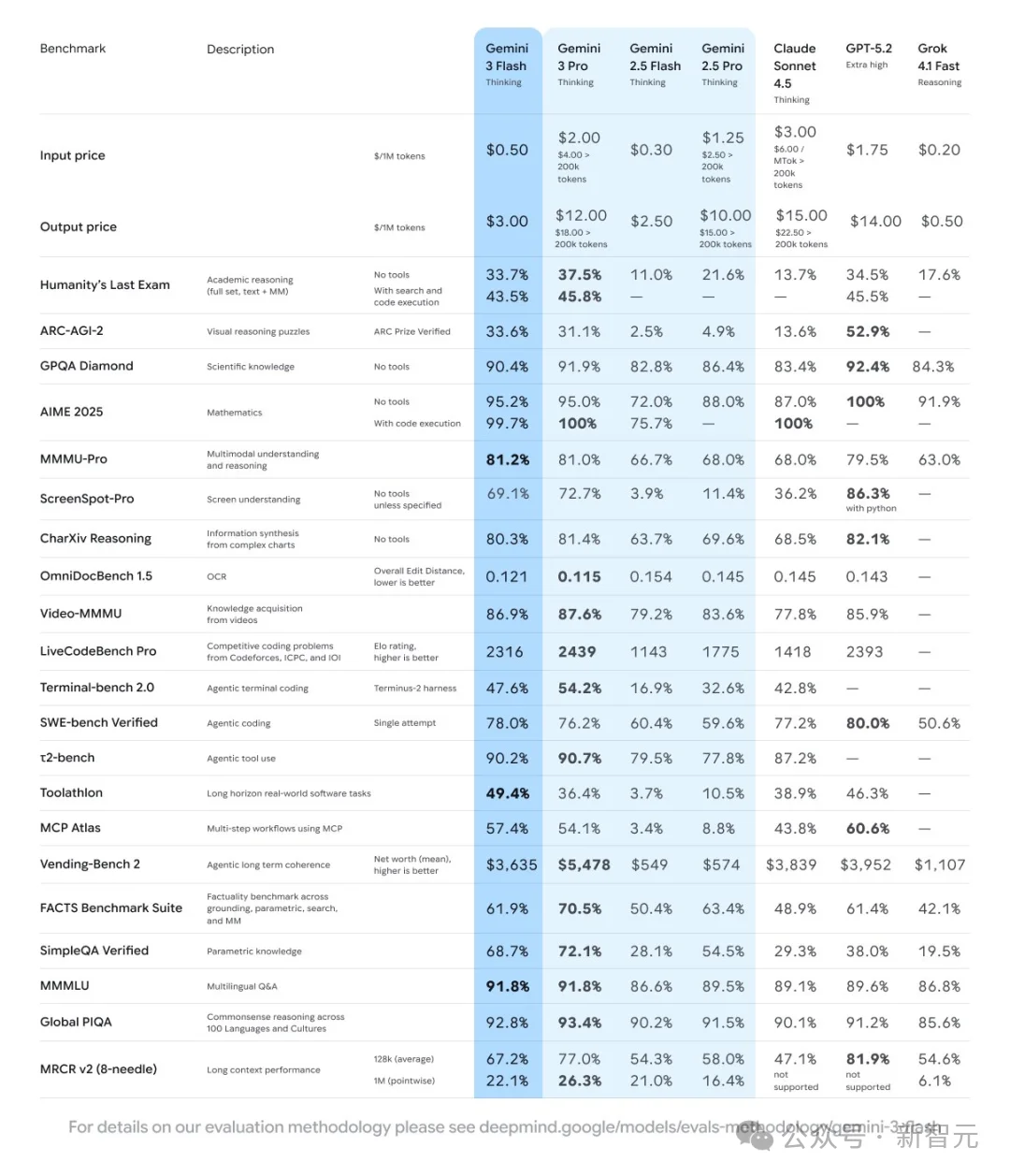
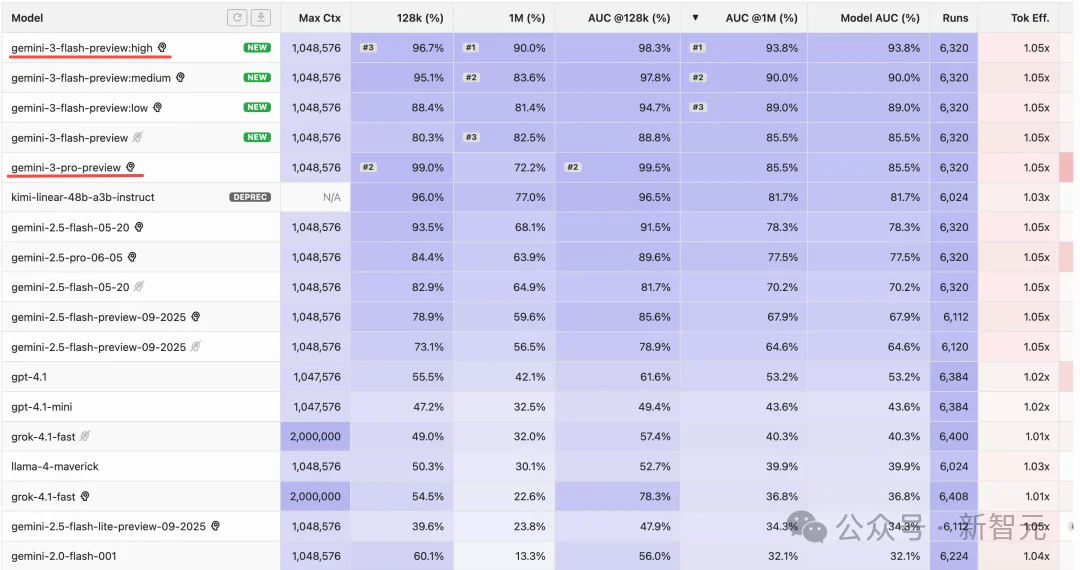
而且最近有人发现,在长下文测试中,Gemini 3 Flash更是遥遥领先!
在OpenAI的MRCR基准测试中,Gemini 3 Flash在100万上下文长度下达到了90%的准确率!
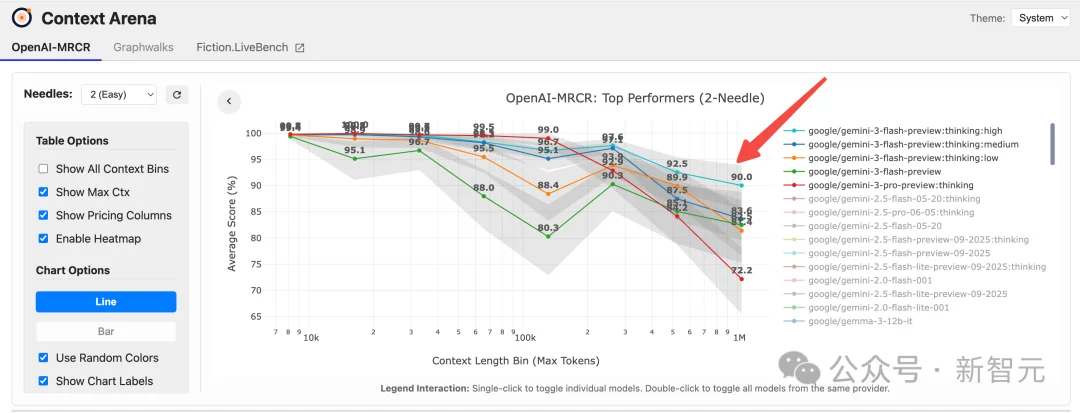
这一表现在所有模型中均属最先进水平,大多数顶尖模型甚至无法突破256k的上下文长度。
那么谷歌到底用了什么黑魔法?
Gemini 3 Flash凭什么在百万长文本与低成本间实现「降维打击」?
知名AI研究员@bycloudai在深入评测后指出,谷歌可能在模型架构研究上已处于「遥遥领先」的隐形地位。
这一表现打破了行业常规认知:它既没有像标准注意力机制那样产生高昂算力成本,也没有像常见的线性注意力或SSM混合模型那样导致知识推理能力下降。
Gemini 3 Flash似乎掌握了某种未知的「高效注意力机制」,令外界对其背后的技术原理直呼「看不懂」但大受震撼。
再挖掘Gemini 3 Flash的黑魔法钱,有必要先介绍一下这个评测标准。
在2023年至2024年间,评估大语言模型长上下文能力的主流方法是「大海捞针」(Needle In A Haystack,NIAH)。
该测试将一个特定的事实(针)插入到长篇文档(大海)的随机位置,要求模型将其检索出来。
然而,随着模型上下文窗口扩展至128k甚至1M token,NIAH测试迅速饱和。
Gemini 1.5 Pro、GPT-4 Turbo等早期模型在该测试中均能达到近乎100%的准确率。
NIAH本质上测试的是检索能力,而非推理能力。
它要求模型找到信息,但不要求模型理解信息之间的复杂依赖关系。
这导致了一种错觉:似乎所有模型都完美掌握了长上下文。
但在实际的企业级应用(如法律文档分析、代码库理解)中,用户不仅需要模型找到「条款A」,还需要模型理解「条款A」与「条款B」在特定条件下的冲突,这种高阶能力是NIAH无法覆盖的。
正是在这种背景下,Context Arena应运而生。
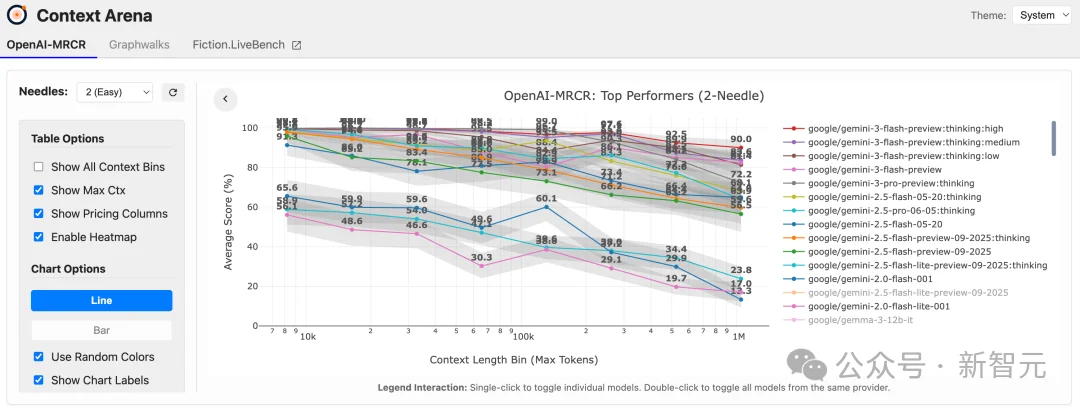
这是一个由独立研究者(如Dillon Uzar等人)维护的、专注于长上下文理解能力评估的基准平台。
Context Arena不仅仅是一个排行榜,它是一个针对大模型「注意力缺陷」的诊断工具看,衡量模型「智商」和长程记忆稳定性的试炼场。
Context Arena最具杀伤力的武器是MRCR(Multi-Round Co-Reference Resolution)基准测试。
OpenAI受到Gemini的启发,也搞了一个OpenAI-MRCR,就是一开始上面所说的评测基准。

这是一个设计精巧的压力测试,旨在击穿那些使用近似注意力机制(如线性注意力或稀疏注意力)的模型的防线。
测试机制是这样的,MRCR会生成一段极长的、多轮次的合成对话或文本。
在这些文本中,系统会植入多个高度相似的「针」(Needles)。
例如,文本中可能包含8首关于「貘」(tapir)的诗,每首诗的风格略有不同但主题一致。
挑战点在于系统会向模型提出极其刁钻的指令,如:「请复述关于貘的第二首诗」或「找出第四次提到貘时的具体描述」。
在Context Arena的MRCR榜单上,Gemini 3 Flash展现出了惊人的统治力。

这直接证明了Gemini 3 Flash并未为了速度而牺牲核心的「注意力精度」。
我们来对比一下常见的注意力机制。
标准注意力是平方级的,所以诞生了一种新技术叫做线性注意力。


另外一种还有稀疏注意力。
稀疏注意力保留了标准注意力的高精度,但通过只计算「重要」的部分来降低计算量。
比如,DeepSeek的DSA(DeepSeek Sparse Attention)。
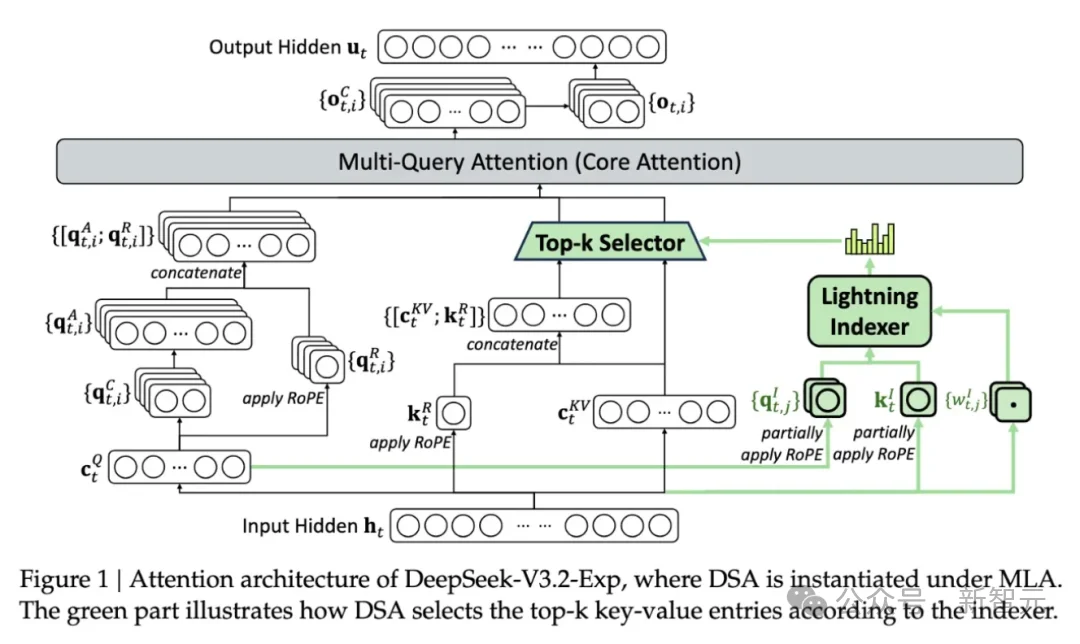
DeepSeek认为,对于任何一个查询,绝大多数历史信息都是无关的。因此,没必要计算全量的注意力。
DSA使用一种启发式算法(如Lightning Indexer),快速筛选出最相关的Top-K个 token或块(Block),只对这些部分进行精细计算。
此外还有一些混合架构,比如Gemini的策略。
虽然谷歌未公开细节,但业界推测Gemini 3 Flash也是一种高度复杂的混合架构,可能在底层使用Infini-attention处理超长历史,在顶层使用标准注意力进行逻辑推理,并结合MoE(混合专家模型)来进一步降低计算成本。
总结来说,谷歌之所以能让Gemini 3 Flash实现「轻量级打Pro」,并非依赖单一的黑科技,而是基于TPU硬件、算法架构、训练数据三位一体的深度优化:
「Flash」一词在谷歌的产品线中历史悠久,从Gemini 1.5 Flash开始,它就被定位为高吞吐量、低延迟的工具,主要用于简单任务的快速处理。
这种定位在用户心中植入了一个根深蒂固的假设:Flash模型是Pro模型的蒸馏版本。
在传统的模型压缩理论中,蒸馏意味着学生模型只能逼近但永远无法超越教师模型的表现。
因此,当Gemini 3 Flash发布时,绝大多数分析师和开发者将其视为一个更便宜的API端点,而非一个推理引擎的革新。
然而,上面的数据告诉我们,Gemini 3 Flash正在讲述一个完全不同的故事。
这种「轻量级反而更强」的现象,不能简单地用更精细的数据清洗或更长的训练时间来解释。
它暗示了底层架构的根本性变化——一种不再单纯依赖参数规模堆叠,而是依赖于更高效的信息路由与记忆机制的新型架构。
Gemini 3 Flash的核心战略意义在于它打破了AI经济学中的线性增长法则。
在过去,要获得10%的智能提升,通常需要10倍的算力投入。
但Gemini 3 Flash以$0.50/1M输入 token的极低价格,提供了GPQA Diamond基准测试中90.4%的博士级推理能力。
这意味着谷歌不仅仅是在打价格战,而是在进行一场架构层面的降维打击。
当一个模型的推理成本低到可以忽略不计,且其长上下文召回能力达到完美(>99%)时,它就不再仅仅是一个聊天机器人,而是一个可以吞噬整个企业知识库、实时重构代码库、并自主进行多轮迭代的「智能代理」(Agent)。
是的,如果一个模型足够的轻量、又能够记住足够的东西、关键是又很便宜,那其他「智能体」还怎么生存?
这种能力的解锁,使得Gemini 3 Flash成为了当前AI智能体爆发的关键推手。
在Pokémon游戏通关测试和SWE-bench代码修复任务中,Flash模型的表现之所以能超越Pro模型,正是因为其低延迟和低成本允许代理在单位时间内进行更多的「思考-行动-反思」循环。
这种通过高频迭代来弥补单次推理深度不足(甚至在很多时候单次推理并不弱)的策略,正是当前AI进化的主要趋势。
结合Gemini 3 Flash在Context Arena的MRCR基准测试中100万上下文90%准确率的惊人表现,以及其低廉的推理成本,最合理的推测是:
Gemini 3 Flash大规模应用了谷歌DeepMind最新的「Titans」架构或其变体。

根据谷歌发表的Titans论文,这是一种结合了Transformer和神经记忆的新型架构。
这些框架让AI模型能够更快地工作,并通过更新核心内存在运行时处理大规模上下文。

Titans包含三个部分:
与传统的RNN(存储固定状态向量)不同,Titans的长期记忆是一个深度神经网络(MLP)。
当模型处理输入时,它不仅仅是把信息存入缓存,而是通过梯度下降实时更新这个MLP的权重。
模型在推理阶段(TestTime)实际上是在「学习」当前的上下文。
它利用一个「惊奇度」(Surprise Metric)指标来衡量新信息的重要性。
如果一段信息(比如用户指定的随机哈希码)出乎模型的预料(High Surprise),模型就会通过梯度更新将其刻入长期记忆网络中。
为什么Titans完美解释了Gemini 3 Flash的表现?
1.无限上下文与线性复杂度:
Titans的MAC(Memory as Context)变体允许将历史信息压缩进神经网络权重,而非无限增长的KVCache。这解释了为什么Flash能以极低的内存占用处理百万级 token,且速度极快(线性推理)。
2.MRCR的高分:
在MRCR测试中,模型需要记住非常具体的细节(Needles)。在Titans架构下,这些独特的、重复出现的「Needles」会产生高惊奇度信号,从而被优先「学习」进记忆模块,而大量的干扰文本则会被遗忘门过滤。这比基于相似度检索的传统注意力机制更能抵抗噪声。
3.自适应能力:
用户反馈称Gemini 3 Flash似乎能「学会」用户的纠正。这正是Titans「测试时学习」特性的体现——模型在对话过程中动态调整了参数。
在这两篇新论文《Titans》和《MIRAS》中,谷歌提出了一种架构和理论蓝图,结合了RNN的速度与变换器精度。
Titans是具体的架构(工具),MIRAS是理论框架(蓝图),用于推广这些方法。
它们共同推动了测试时间记忆的概念,即AI模型通过在模型运行时加入更强大的「惊喜」指标(即意外信息片段)来维持长期记忆的能力,无需专门的离线再训练。

一个有效的学习系统需要不同但相互关联的记忆模块,这反映了人脑对短期记忆和长期记忆的分离。
虽然注意力机制在精确短期记忆方面表现出色,Titans引入了一种新型神经长期记忆模块,它不同于传统RNN中的固定大小向量或矩阵记忆,它充当深度神经网络。
该内存模块提供了显著更高的表达能力,使模型能够在不丢失重要上下文的情况下总结大量信息。模型不仅仅是做笔记,而是理解并综合整个故事。
关键是,泰坦不仅仅是被动存储数据。
它主动学习如何识别并保留连接整个输入中Token的重要关系和概念主题。这项能力的一个关键方面是我们所说的「惊喜指标」。
在人类心理学中,我们知道我们会很快且容易地忘记例行公事、预期中的事件,但会记住打破常规的事情——意外、惊喜或情绪激动的事件。
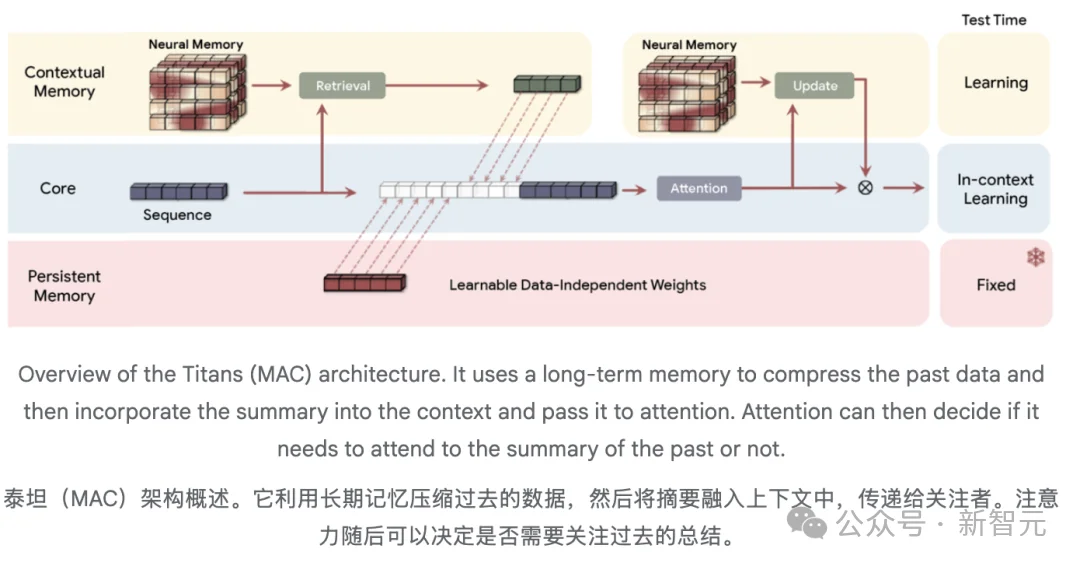
在《泰坦》的语境中,「惊讶指标」指的是模型检测到当前记忆与新输入信息之间的巨大差异。
该模型将这个内部误差信号(梯度)当作数学上的等价物,比如说:「这是意外且重要!」这使得泰坦架构能够选择性地更新其长期记忆,只包含最新颖且破坏上下文的信息,从而保持整体流程的快速和高效。
泰坦通过整合两个关键要素来完善这一机制:
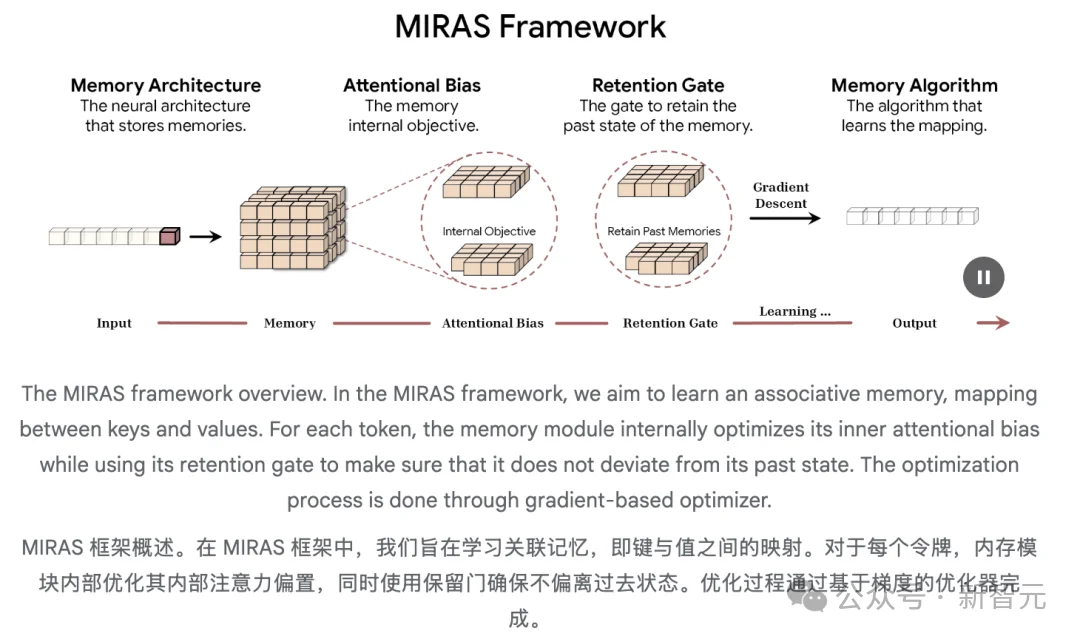
序列建模的每一项重大突破,从现代变换器到新的闪电高速线性RNN,本质上都是同一件事:一个高度复杂的联想记忆模块。
因此,MIRAS独特且实用的,在于它对AI建模的看法。它不再看到多样化的架构,而是看到解决同一问题的不同方法:高效地将新信息与旧记忆结合,同时不遗忘核心概念。
MIRAS通过四个关键设计选择定义了序列模型:
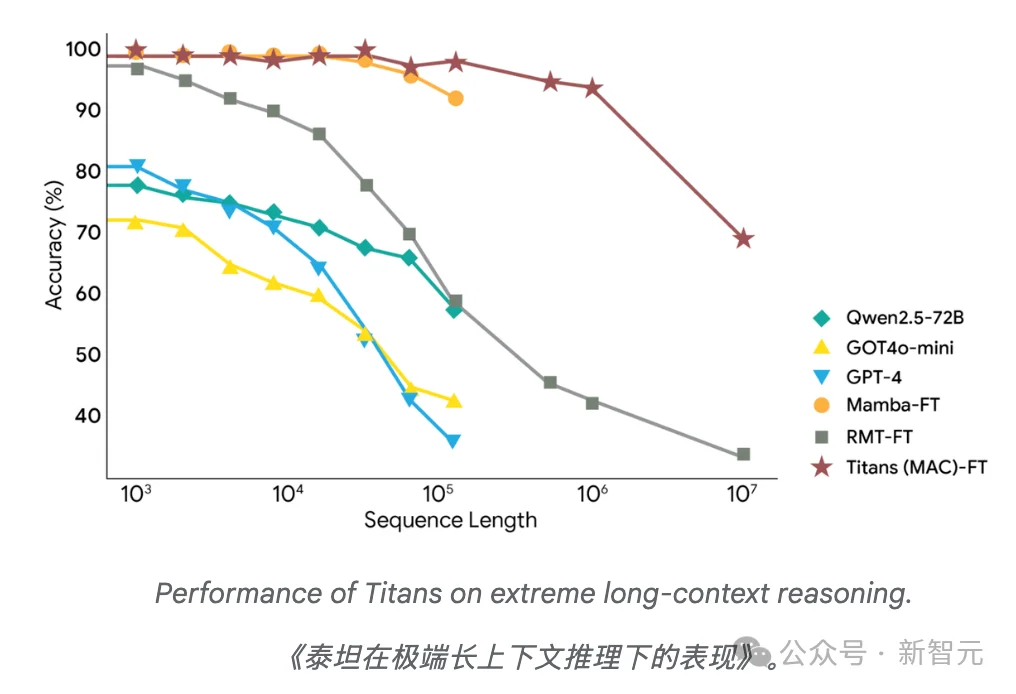
这些新架构最显著的优势是能够处理极长的上下文。
这一点在BABILong基准测试中得到了体现,该任务需要在极长的文档中对事实进行推理。
在这一充满挑战的环境中,Titans的表现优于所有基线,包括像GPT-4这样极其庞大的模型,尽管参数远少于GPT-4。
Titans进一步展示了能够有效扩展到超过200万个令牌的上下文窗口。
Titans和MIRAS框架的引入标志着序列建模的重大进展。
通过将深度神经网络作为记忆模块,在数据流入时学习记忆,这些方法克服了固定大小的循环状态的局限。
此外,MIRAS提供了强大的理论统一,揭示了在线优化、联想记忆与架构设计之间的联系。
这项研究为新一代序列模型打开了大门,这些模型结合了RNN的高效与长上下文人工智能时代所需的表达能力。
分别向Gemini和GPT询问了Gemini 3 Pro和Flash的参数大小。
Gemini 3 Flash的回答:
基于截至2025年12月的最新行业信息和技术分析,官方并未公开Gemini 3 Pro和Gemini 3 Flash的确切模型参数大小。这是谷歌自 Gemini 1.0以来的一贯策略,主要为了保护架构机密。
不过,根据技术白皮书的推断、行业泄露信息以及对其性能(Token 生成速度和显存占用)的逆向分析,目前的主流估算(数量级)如下

GPT 5.2的回答:

总之,Pro和Flash这两模型的参数数量级差了将近5~10倍(估算)。因此,Flash的使用体验远超预期,才会引起社区广泛的讨论。
参考资料:
https://research.google/blog/titans-miras-helping-ai-have-long-term-memory/
https://x.com/bycloudai/status/2002347892535930934
文章来自于“新智元”,作者 “定慧”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
