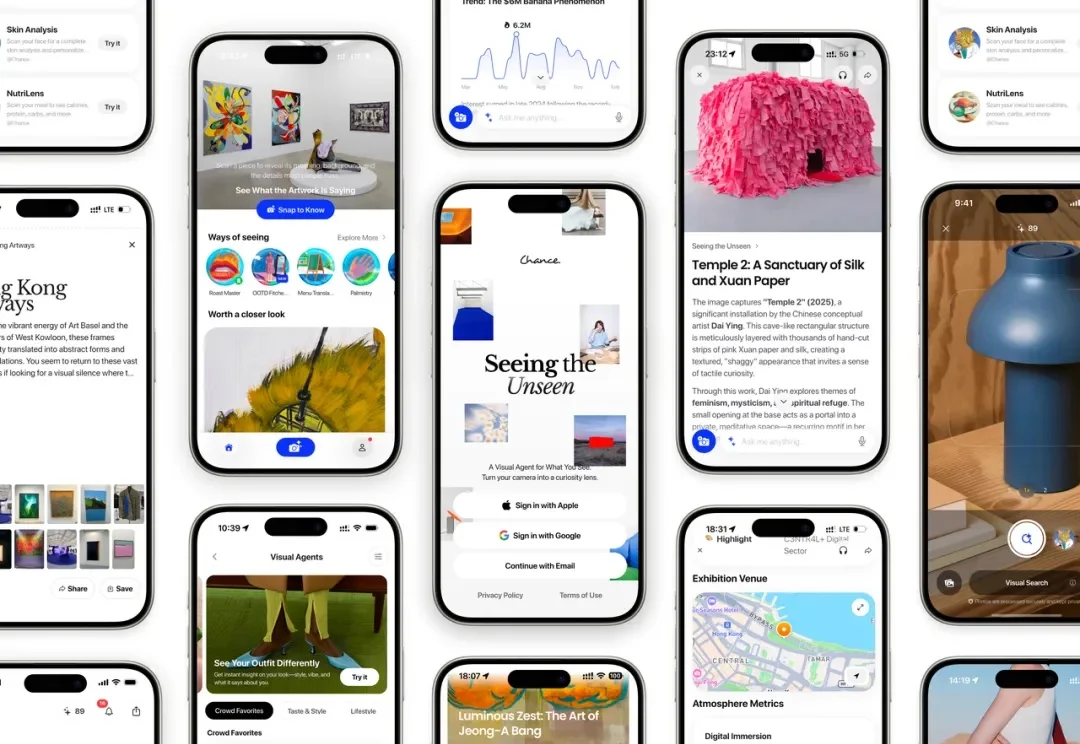
深度|10人团队登顶视觉推理榜,Chance AI 超过GPT、Gemini和人类专家
深度|10人团队登顶视觉推理榜,Chance AI 超过GPT、Gemini和人类专家过去两年,多模态模型的竞争看起来像一场“造眼睛”的竞赛:更高的图像分辨率、更多的视觉 token、更大的模型,以及更昂贵的训练。行业似乎默认,只要第一次看得足够清楚,AI 就能从“看见”抵达“洞见”。
来自主题: AI资讯
9971 点击 2026-07-30 11:34
 搜索
搜索
过去两年,多模态模型的竞争看起来像一场“造眼睛”的竞赛:更高的图像分辨率、更多的视觉 token、更大的模型,以及更昂贵的训练。行业似乎默认,只要第一次看得足够清楚,AI 就能从“看见”抵达“洞见”。

据英国《金融时报》7 月 29 日报道,谷歌 DeepMind 已经重组了曾打造诺贝尔奖级成果 AlphaFold 的核心团队:不再保留独立的 AlphaFold 团队,而是将相关研究人员分流至多个战略项目。这一调整被视为 DeepMind 将重心进一步转向 Gemini 大模型和 AI Agent 的重要信号。

近日,Meta 首席 AI 官、被称为公司“最高薪员工”的 Alexandr Wang,因一句简单却极具挑衅意味的话引起热议:“gemini who?(Gemini,谁啊?)”这场口水战的背后,其实是一场 AI 巨头之间的公开较量——Meta 最新模型 Muse Spark 1.1 在一份模型排行榜中超过了谷歌刚发布的 Gemini 3.6 Flash

谷歌的前端功底有多深,不需要任何人来认证。

如果你从去年就开始用 Gemini,那感觉就像看着自家兄弟慢慢得了阿尔茨海默症。按理说,一家公司发新模型,通常是来打脸这种调侃的。可就在刚刚,Google 一口气发了三个新模型之后,网友非但没收回这句话,反而笑得更大声了。多少有种他们都不看好你,可偏偏你最不争气的即视感。

刚刚,The Information报道,Google正在搞一颗代号「Frozen v2」的服务器芯片,打算把Gemini的部分架构直接固化进硬件里。

彭博社的一则独家报道如同一盆冰水,浇灭了所有人的热情:Gemini 3.5 Pro发布延期了,而且不是延期几天,是数月的大延期!本该是载入史册的发布,被谷歌自己按下了暂停。

最新消息终于来了——Gemini 3.5 Pro或将于7月17日正式上线。更有意思的是,这个日期恰好与国产大模型DeepSeek V4正式版的发布窗口正面重合。那么这一次,谷歌拿出的究竟是“真金”还是“虚火”?不妨从三个维度拆解一下。

过去几年,大语言模型几乎成为了AI的代名词。从ChatGPT到Google DeepMind推出的Gemini,从Anthropic开发的Claude到中国的DeepSeek,人们讨论更多的是聊天机器人、推理能力和生成内容。但如果问Google DeepMind CEO、2024年诺贝尔化学奖得主Demis Hassabis(下简称“哈萨比斯”)
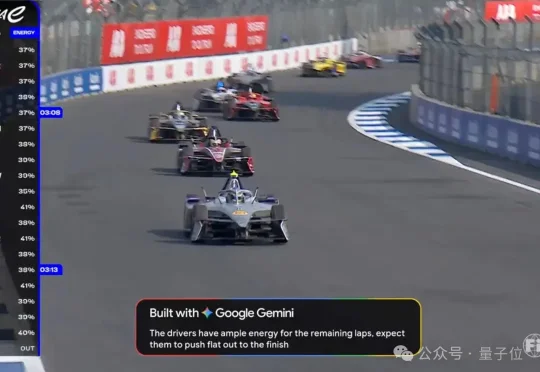
Gemini,入局电动版F1赛车了。Formula E,aka电动方程式,如今有Gemini扮演「解说员」,为数百万观众全程提供实时分析。 此前,FE还联合Gemini做了一次极限挑战。电池只剩1%,要从法国阿尔卑斯山上溜下来,靠刹车回收能量,然后跑完摩纳哥赛道一整圈。