# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Agent 的状态数据分两种:会话内的临时上下文和跨会话的长期知识。
前者是“用户刚才说了什么”、“工具返回了什么结果”,会话结束就该清空。后者是“用户三个月前的购买记录”、“历史工单的解决方案”,需要持久化并在未来对话中智能召回。
混用这两种数据会导致很多用户体验上的问题,比如:把临时上下文永久化,数据库会堆满无用的工具调用记录。把长期知识当临时数据处理,用户下次登录时 Agent 会忘记所有偏好。
而要解决这个问题,需要在架构层面将存储和检索逻辑做好分离。
在这一背景下,Google 在 2025 年开源了 Agent Development Kit(ADK),这是一个生产级的 Agent 开发框架:能够在架构层面强制分离会话内上下文和跨会话知识,避免开发者把这两种数据混在一起。
那么其运行逻辑是什么?如何使用,本文将重点解答。
ADK的核心设计逻辑在于,把状态管理作为框架的核心设计。
每个 Agent 实例天生带着 SessionService(会话内临时数据)和 MemoryService(跨会话长期知识)两个接口,避免了状态对象在代码层级间传递。
其中SessionService 支持内存、数据库、云托管三种后端,MemoryService 则是接口规范,具体存储后端由开发者选择。
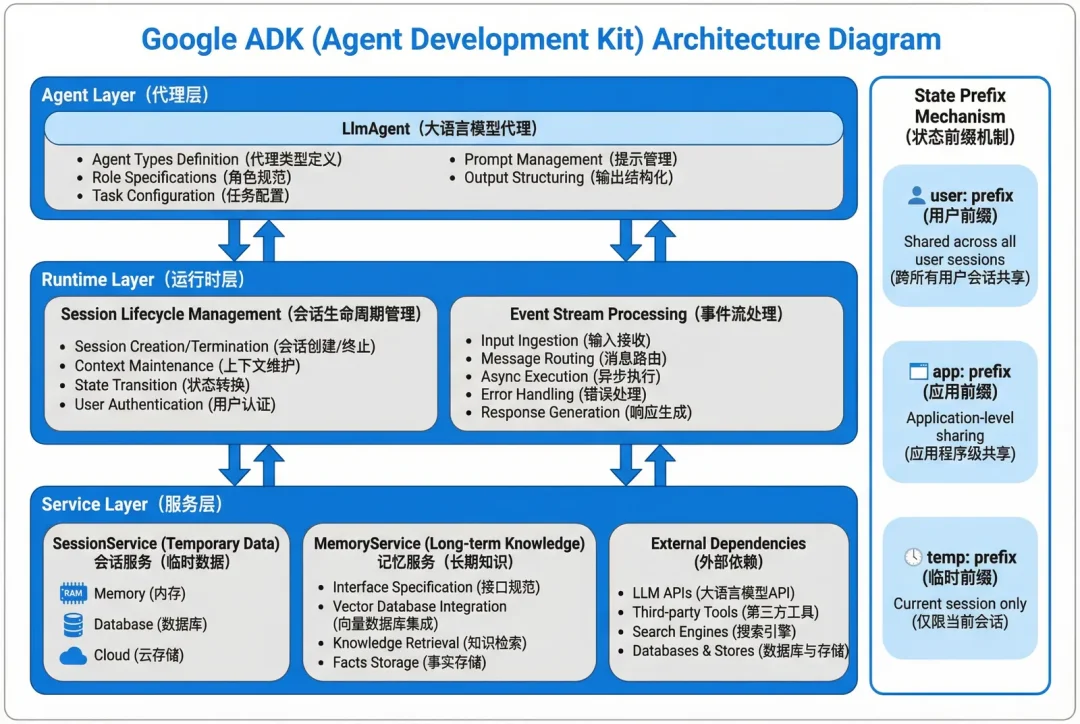
整体架构一共分三层:Agent 层定义智能体类型,Runtime 层管理 Session 生命周期和 Event 流,Service 层抽象外部依赖。核心是 Event 驱动模型,Agent 的每次操作被封装成 Event 追加到事件流,可以在任意时刻回放决策过程。
ADK 通过 state 的 prefix 机制细化数据作用域:user:前缀在用户的所有 Session 间共享,app:前缀在应用级别共享,temp:前缀仅在当前 Session 有效。
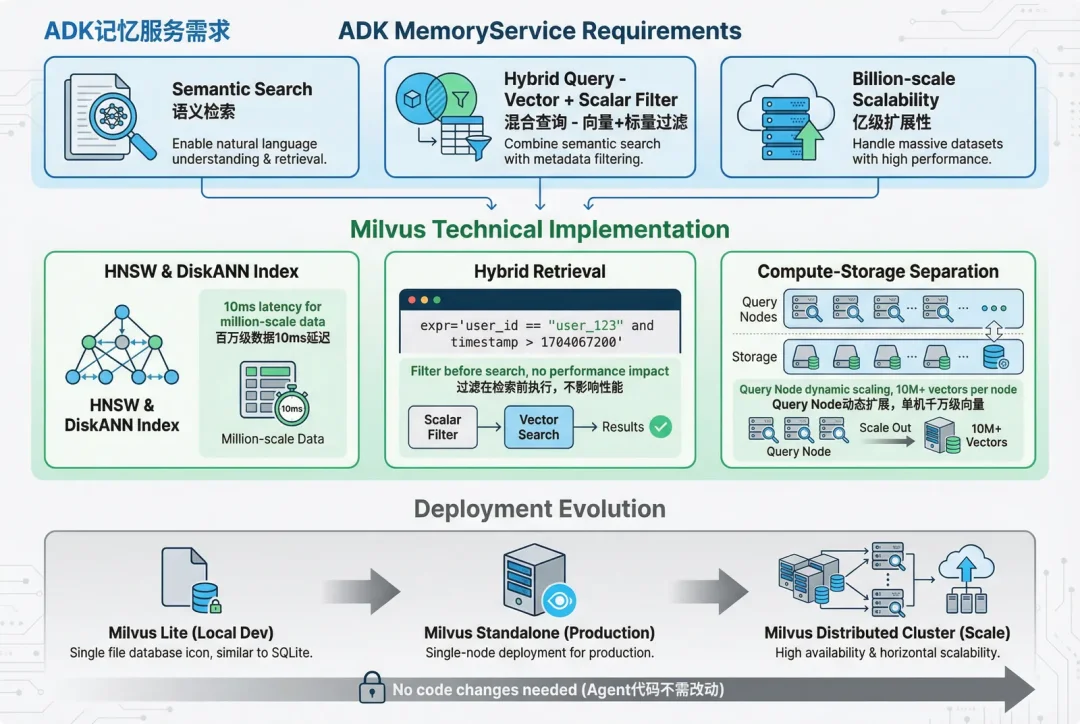
ADK 的 MemoryService 需要三个重点能力:语义检索、混合查询、亿级扩展性。
Milvus 在这三个维度上分别支持:
语义检索上,Milvus 支持 HNSW 和 DiskANN等十多种针对不同场景的高效向量索引算法,并能做到千万级数据下查询延迟可以控制在 10ms 以内。
混合检索上,Milvus 支持向量搜索+标量过滤;语义+关键词等针对不同内容、不同数据类型的高效检索,且不影响整体性能与召回率。
扩展性方面,Milvus 的计算存储分离架构支持 Query Node 的动态扩展,单机可以支撑千万级向量。
本文 Demo 主要使用 Milvus Lite或Milvus Standalone 进行本地开发测试。
实现一个技术客服 Agent,需求是:当用户提问时,Agent 能从历史工单中召回相似案例,避免重复解答。这个场景之所以典型,是因为它涉及了 Agent 记忆系统的三大难点:跨会话检索(用户今天问的问题,可能和上个月的工单相关)、用户隔离(不能把用户 A 的记忆召回给用户 B)、语义匹配(用户的提问方式千变万化,不能用精确匹配)。
环境准备:
1.Python3.11+
2.docker、dockercompos
3.Gemini-API-KEY
这部分是基础配置,确保程序能正常运行
pip install google-adk pymilvus google-generativeai
“”“
ADK + Milvus + Gemini 长期记忆 Agent
演示如何实现跨会话的记忆召回系统
”“”
import os
import asyncio
import time
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType, utility
import google.generativeai as genai
from google.adk.agents import Agent
from google.adk.tools import FunctionTool
from google.adk.runners import Runner
from google.adk.sessions import InMemorySessionService
from google.genai import types
wget <https://github.com/Milvus-io/Milvus/releases/download/v2.5.12/Milvus-standalone-docker-compose.yml> -O docker-compose.yml
docker-compose up -d
docker-compose ps -a

配置 Gemini API 和 Milvus 连接参数
# ==================== 配置部分 ====================
# 1. Gemini API 配置
GOOGLE_API_KEY = os.getenv(“GOOGLE_API_KEY”)
if not GOOGLE_API_KEY:
raise ValueError(“请设置环境变量 GOOGLE_API_KEY”)
genai.configure(api_key=GOOGLE_API_KEY)
# 2. Milvus 连接配置
MILVUS_HOST = os.getenv(“MILVUS_HOST”, “localhost”)
MILVUS_PORT = os.getenv(“MILVUS_PORT”, “19530”)
# 3. 模型选择(免费层级额度最高的组合)
LLM_MODEL = “gemini-2.5-flash-lite” # LLM 模型:1000RPD
EMBEDDING_MODEL = “models/text-embedding-004” # Embedding 模型:1000 RPD
EMBEDDING_DIM = 768 # 向量维度
# 4. 应用配置
APP_NAME = “tech_support”
USER_ID = “user_123”
print(f“✓ 使用模型配置:”)
print(f“ LLM: {LLM_MODEL}”)
print(f“ Embedding: {EMBEDDING_MODEL} (维度: {EMBEDDING_DIM})”)
创建向量数据库的 Collection(类似关系数据库的表)
# ==================== 初始化 Milvus ====================
def init_milvus():
“”“初始化 Milvus 连接和 Collection”“”
# 第一步:建立连接
try:
connections.connect(
alias=“default”,
host=MILVUS_HOST,
port=MILVUS_PORT
)
print(f“✓ 已连接到 Milvus: {MILVUS_HOST}:{MILVUS_PORT}”)
except Exception as e:
print(f“✗ Milvus 连接失败: {e}”)
print(“提示:确保 Milvus 已启动”)
raise
# 第二步:定义数据结构(Schema)
fields = [
FieldSchema(name=“id”, dtype=DataType. INT64, is_primary=True, auto_id=True),
FieldSchema(name=“user_id”, dtype=DataType. VARCHAR, max_length=100),
FieldSchema(name=“session_id”, dtype=DataType. VARCHAR, max_length=100),
FieldSchema(name=“question”, dtype=DataType. VARCHAR, max_length=2000),
FieldSchema(name=“solution”, dtype=DataType. VARCHAR, max_length=5000),
FieldSchema(name=“embedding”, dtype=DataType. FLOAT_VECTOR, dim=EMBEDDING_DIM),
FieldSchema(name=“timestamp”, dtype=DataType. INT64)
]
schema = CollectionSchema(fields, description=“Tech support memory”)
collection_name = “support_memory”
# 第三步:创建或获取 Collection
if utility.has_collection(collection_name):
memory_collection = Collection(name=collection_name)
print(f“✓ Collection ‘{collection_name}’ 已存在”)
else:
memory_collection = Collection(name=collection_name, schema=schema)
# 第四步:创建向量索引
index_params = {
“index_type”: “IVF_FLAT”,
“metric_type”: “COSINE”,
“params”: {“nlist”: 128}
}
memory_collection.create_index(field_name=“embedding”, index_params=index_params)
print(f“✓ 已创建 Collection ‘{collection_name}’ 和索引”)
return memory_collection
# 执行初始化
memory_collection = init_milvus()
封装存储和检索逻辑,作为 Agent 的工具
# ==================== 记忆操作函数 ====================
def store_memory(question: str, solution: str) -> str:
“”“
存储一条解决方案到记忆库
Args:
question: 用户的问题
solution: 解决方案
Returns:
str: 存储结果消息
”“”
try:
print(f“\n【工具调用】 store_memory”)
print(f“ - question: {question[:50]}……”)
print(f“ - solution: {solution[:50]}……”)
# 使用全局 USER_ID(生产环境应从 ToolContext 获取)
user_id = USER_ID
session_id = f“session_{int(time.time())}”
# 关键步骤 1:将问题转换为 768 维向量
embedding_result = genai.embed_content(
model=EMBEDDING_MODEL,
content=question,
task_type=“retrieval_document”,# 指定为文档索引任务
output_dimensionality=EMBEDDING_DIM
)
embedding = embedding_result[“embedding”]
# 关键步骤 2:插入 Milvus
memory_collection.insert([{
“user_id”: user_id,
“session_id”: session_id,
“question”: question,
“solution”: solution,
“embedding”: embedding,
“timestamp”: int(time.time())
}])
# 关键步骤 3:刷新到磁盘(确保数据持久化)
memory_collection.flush()
result = f“✓ 已成功存储到记忆库”
print(f“【工具结果】 {result}”)
return result
except Exception as e:
error_msg = f“✗ 存储失败: {str(e)}”
print(f“【工具错误】 {error_msg}”)
return error_msg
def recall_memory(query: str, top_k: int = 3) -> str:
“”“
从记忆库检索相关历史案例
Args:
query: 查询问题
top_k: 返回的最相似结果数量
Returns:
str: 检索结果
”“”
try:
print(f“\n【工具调用】 recall_memory”)
print(f“ - query: {query}”)
print(f“ - top_k: {top_k}”)
user_id = USER_ID
# 关键步骤 1:将查询转换为向量
embedding_result = genai.embed_content(
model=EMBEDDING_MODEL,
content=query,
task_type=“retrieval_query”, # 指定为查询任务(和索引时不同)
output_dimensionality=EMBEDDING_DIM
)
query_embedding = embedding_result[“embedding”]
# 关键步骤 2:加载 Collection 到内存(首次查询需要)
memory_collection.load()
# 关键步骤 3:混合检索(向量相似度 + 标量过滤)
results = memory_collection.search(
data=[query_embedding],
anns_field=“embedding”,
param={“metric_type”: “COSINE”, “params”: {“nprobe”: 10}},
limit=top_k,
expr=f‘user_id == “{user_id}”’, # 🔑 用户隔离的关键
output_fields=[“question”, “solution”, “timestamp”]
)
# 关键步骤 4:格式化结果
if not results[0]:
result = “没有找到相关历史案例”
print(f“【工具结果】 {result}”)
return result
result_text = f“找到 {len(results[0])} 个相关案例:\n\n”
for i, hit in enumerate(results[0]):
result_text += f“案例{i+1}(相似度:{hit.score:.2f}):\n”
result_text += f“问题: {hit.entity.get(‘question’)}\n”
result_text += f“解决方案: {hit.entity.get(‘solution’)}\n\n”
print(f“【工具结果】 找到 {len(results[0])} 个案例”)
return result_text
except Exception as e:
error_msg = f“检索失败: {str(e)}”
print(f“【工具错误】 {error_msg}”)
return error_msg
#使用
FunctionTool 包装函数
store_memory_tool = FunctionTool(func=store_memory)
recall_memory_tool = FunctionTool(func=recall_memory)
memory_tools = [store_memory_tool, recall_memory_tool]
核心:定义 Agent 的行为逻辑
# ==================== 创建 Agent ====================
support_agent = Agent(
model=LLM_MODEL,
name=“support_agent”,
description=“技术支持专家 Agent,能够记忆和召回历史案例”,
# 关键:Instruction 决定了 Agent 的行为模式
instruction=“”“你是一个技术支持专家。严格按照以下流程处理:
<b>当用户提出技术问题时:</b>
1. 立即调用 recall_memory 工具查找历史案例
- 参数 query: 直接使用用户的问题文本
- 不要询问任何其他信息,直接调用
2. 根据检索结果回答:
- 如果找到相关案例:说明找到了相似的历史案例,并参考其解决方案回答
- 如果没找到:说明这是新问题,根据你的知识库回答
3. 回答完毕后,询问:”这个方案是否解决了您的问题?“
<b>当用户确认问题已解决时:</b>
- 立即调用 store_memory 工具存储这次问答
- 参数 question: 用户最初的问题
- 参数 solution: 你提供的完整解决方案
<b>重要规则:</b>
- 必须先调用工具,再回答
- 不要询问 user_id 或任何其他参数
- 只有看到”解决了“、”好了“、”谢谢“等确认词时才存储记忆
”“”,
tools=memory_tools
)
演示跨会话记忆召回的完整流程
# ==================== 主程序 ====================
async def main():
“”“演示跨会话记忆召回”“”
# 创建 Session 服务和 Runner
session_service = InMemorySessionService()
runner = Runner(
agent=support_agent,
app_name=APP_NAME,
session_service=session_service
)
# ========== 第一轮对话:建立记忆 ==========
print(“\n” + “=”*60)
print(“第一轮对话:用户提问并存储方案”)
print(“=”*60)
session1 = await session_service.create_session(
app_name=APP_NAME,
user_id=USER_ID,
session_id=“session_001”
)
# 用户第一次提问
print(“\n【用户】: Milvus 连接超时怎么办?”)
content1 = types. Content(
role=‘user’,
parts=[types. Part(text=“Milvus 连接超时怎么办?”)]
)
async for event in runner.run_async(
user_id=USER_ID,
session_id=session1.id,
new_message=content1
):
if event.content and event.content.parts:
for part in event.content.parts:
if hasattr(part, ‘text’) and part.text:
print(f“[Agent]: {part.text}”)
# 用户确认问题解决
print(“\n【用户】: 问题解决了,谢谢!”)
content2 = types. Content(
role=‘user’,
parts=[types. Part(text=“问题解决了,谢谢!”)]
)
async for event in runner.run_async(
user_id=USER_ID,
session_id=session1.id,
new_message=content2
):
if event.content and event.content.parts:
for part in event.content.parts:
if hasattr(part, ‘text’) and part.text:
print(f“[Agent]: {part.text}”)
# ========== 第二轮对话:召回记忆 ==========
print(“\n” + “=”*60)
print(“第二轮对话:新会话但能召回记忆”)
print(“=”*60)
session2 = await session_service.create_session(
app_name=APP_NAME,
user_id=USER_ID,
session_id=“session_002”
)
# 用户在新会话中提类似问题
print(“\n【用户】: Milvus 连不上了”)
content3 = types. Content(
role=‘user’,
parts=[types. Part(text=“Milvus 连不上了”)]
)
async for event in runner.run_async(
user_id=USER_ID,
session_id=session2.id,
new_message=content3
):
if event.content and event.content.parts:
for part in event.content.parts:
if hasattr(part, ‘text’) and part.text:
print(f“[Agent]: {part.text}”)
# 程序入口
if __name__ == “__main__”:
try:
asyncio.run(main())
except KeyboardInterrupt:
print(“\n\n 程序已退出”)except Exception as e:
print(f“\n\n 程序错误: {e}”)
import traceback
traceback.print_exc()
finally:
try:
connections.disconnect(alias=“default”)
print(“\n✓ 已断开 Milvus 连接”)
except:
pass
export GOOGLE_API_KEY="your-gemini-api-key"
python milvus_agent.py
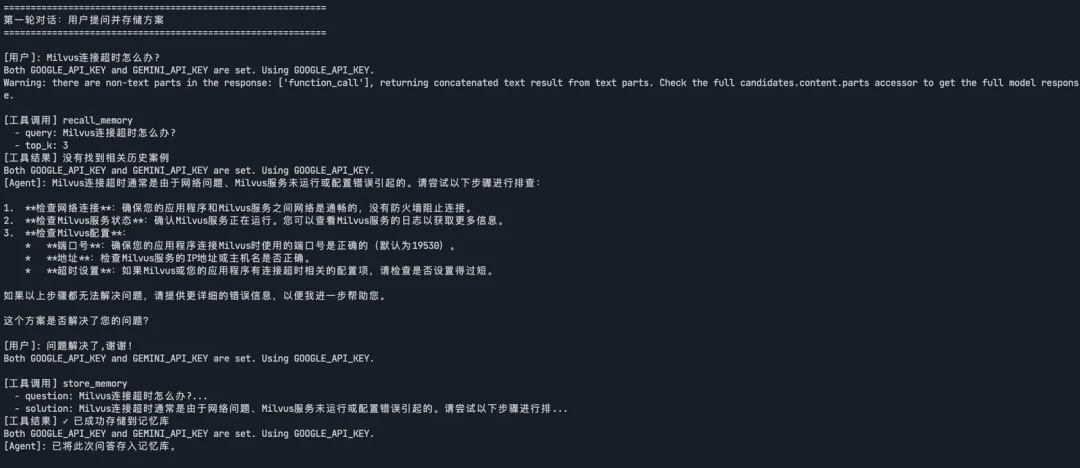

运行结果展示了完整的记忆召回流程:第一轮对话中,Agent 回答了“Milvus 连接超时”的问题并存入记忆库;第二轮启动新会话后,用户换了个说法问“Milvus 连不上了”,向量检索直接匹配到了之前的案例并给出方案。整个过程 Agent 自己决定什么时候该检索历史、什么时候该存储记忆,跨会话召回、语义匹配、用户隔离这几个关键功能。
ADK 通过 SessionService 和 MemoryService 分离短期上下文和长期知识,Milvus 通过向量检索实现语义匹配和混合查询。
如果你的项目符合“生产环境+工具重度+GCP 基础设施”这三个条件,ADK 值得尝试。如果只是快速验证想法,LangChain 依然是更灵活的选择。
至于记忆系统,不管你用哪个框架,向量数据库都是绕不过去的技术选型。Milvus 的优势在于开源可本地部署、单机支撑千万级向量、支持向量和标量的混合检索,这三点在生产环境中缺一不可。

Zilliz黄金写手:尹珉
文章来自于“Zilliz”,作者 “尹珉”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
