# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
英伟达在开源模型上玩的很激进:
“最高效的开放模型家族”Nemotron 3,混合Mamba-Transformer MoE架构、NVFP4低精度训练全用上。

而且开放得很彻底:
不仅开放模型权重,还要把超过10万亿token的训练数据、预训练和后训练软件、训练配方全部公开。

与其他开源模型相比性能有竞争力,且速度快1.5-3.3倍。
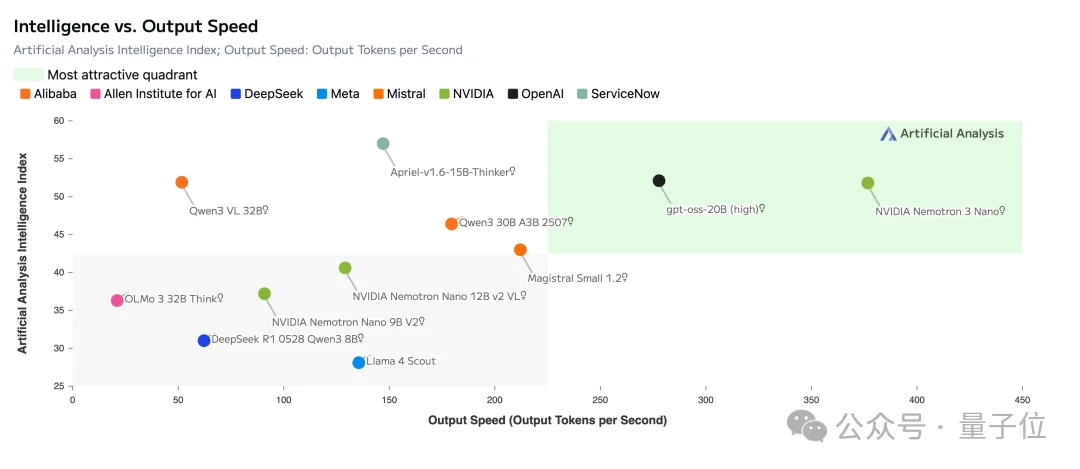
Nemotron 3在架构层面追求推理效率的最大化。
传统Transformer的自注意力机制需要对不断增长的KV Cache做线性扫描,序列越长,计算开销越大。
英伟达的解决方案是大量使用Mamba-2层替代自注意力层——Mamba层在生成时只需要存储固定大小的状态,不受序列长度影响。
以Nano型号为例,整个模型主要由交替堆叠的Mamba-2层和MoE层构成,自注意力层只保留了少数几个。
论文给出的层排布模式是:5个Mamba-2+MoE的重复单元,接3个同样结构的单元,再来1个包含注意力层的单元,最后是4个Mamba-2+MoE单元。
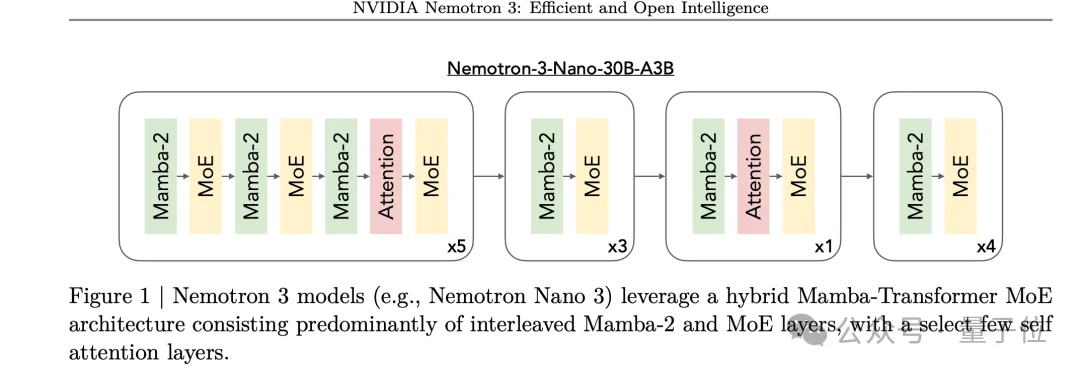
在8k输入、16k输出的典型推理场景下,Nemotron 3 Nano 30B-A3B的吞吐量是Qwen3-30B-A3B的3.3倍。序列越长,优势越明显。
与此同时,模型在长上下文任务上的表现并没有打折扣。
论文展示了一组RULER基准测试的结果:在100万token输入长度下,Nemotron 3 Nano基座模型拿到了68.2分,而在同样条件下训练的Nemotron 2 Nano 12B只有23.43分,出现了断崖式下跌。MoE混合架构在长度外推上的鲁棒性明显更好。
针对Super和Ultra这两个更大的模型,英伟达提出了LatentMoE架构,在潜在空间中进行专家计算。
MoE层在实际部署时会遇到两类瓶颈:
低延迟场景下,每次只处理几十到几百个token,此时从显存读取专家权重成为主要开销。
高吞吐场景下,一次处理数千token,此时专家间的all-to-all通信成为瓶颈。两种情况下,开销都与隐藏维度d线性相关。
LatentMoE的做法是:先把token从原始隐藏维度d投影到一个更小的潜在维度ℓ(通常是d的四分之一),在这个低维空间里完成专家路由和计算,最后再投影回原始维度。
这样一来,每个专家的权重加载量和通信量都降低了d/ℓ倍。省下来的计算预算被用于增加专家数量和每个token激活的专家数。
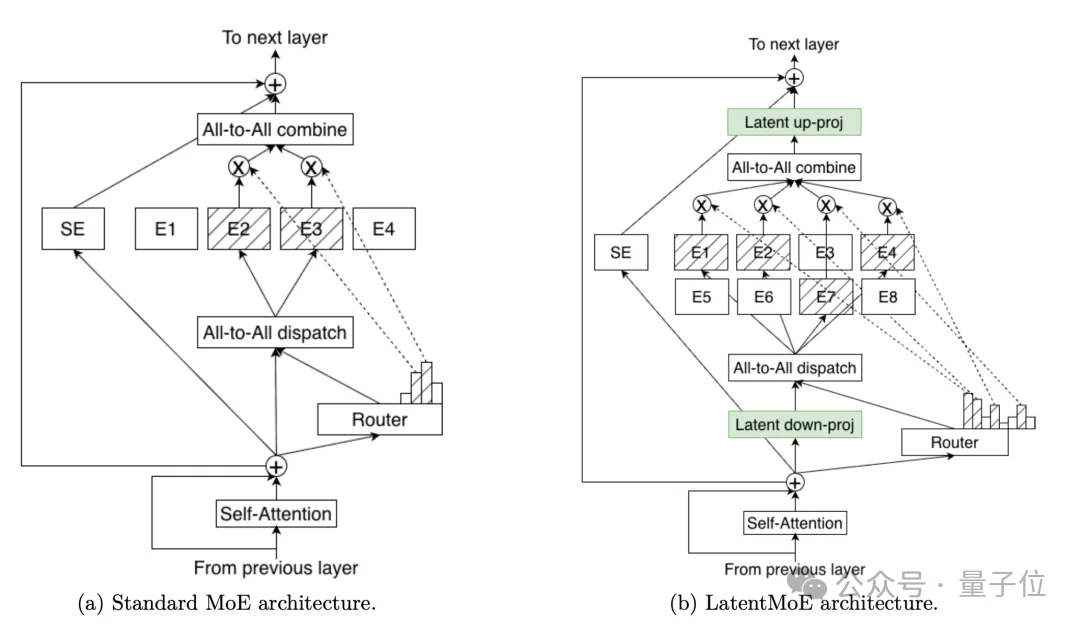
标准MoE用128个专家、激活6个;LatentMoE用512个专家、激活22个。
两者的总参数量和激活参数量几乎相同(都是8B激活、73B总参),但LatentMoE在所有下游任务上都取得了更好的成绩——MMLU-Pro从48.30提升到52.87,代码任务从51.95提升到55.14,数学任务从78.32提升到80.19。
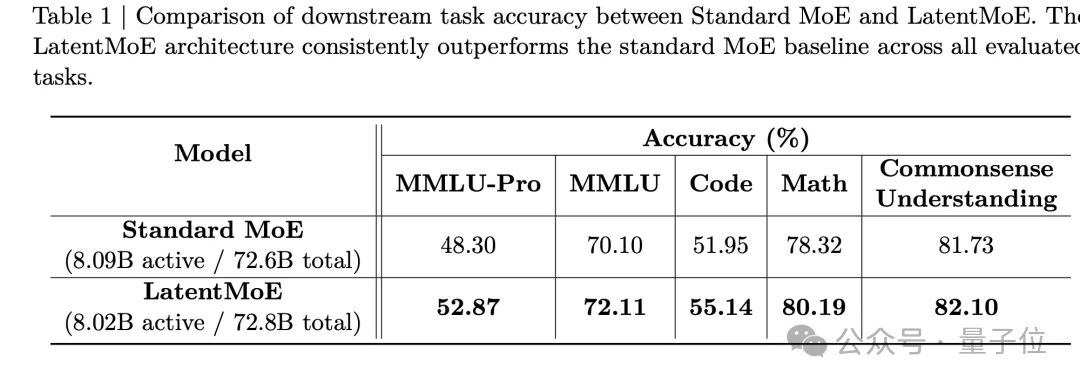
需要注意的是,路由门控网络、共享专家计算以及非专家层仍然保留在原始维度,因为这些部分对瓶颈的贡献很小。
Super和Ultra还采用了NVFP4格式进行训练,这是英伟达在低精度训练上的又一次探索。
NVFP4是一种4位浮点格式,采用E2M1的元素格式(2位指数、1位尾数),配合16元素的微块缩放和E4M3格式的块缩放因子。在GB300上,FP4的峰值吞吐量是FP8的3倍。
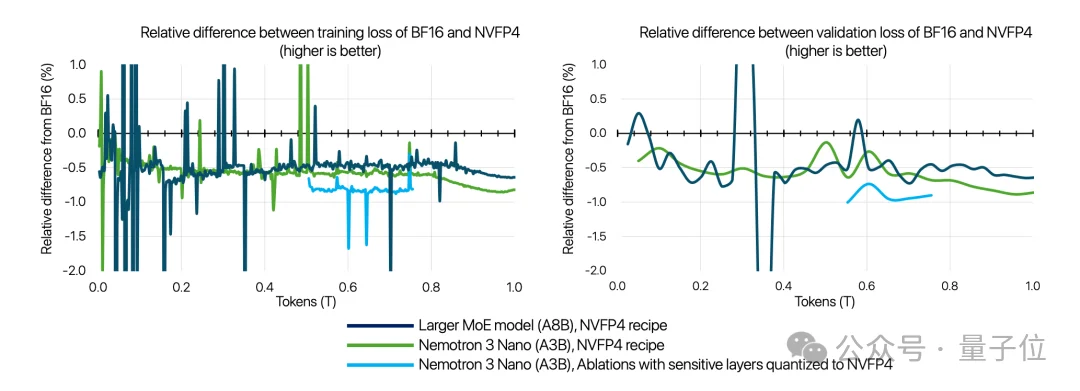
论文显示,团队已经用NVFP4格式稳定训练了高达25万亿token。与BF16训练相比,Nano模型的损失差距控制在1%以内,8B激活参数的更大模型差距进一步缩小到0.6%以内。
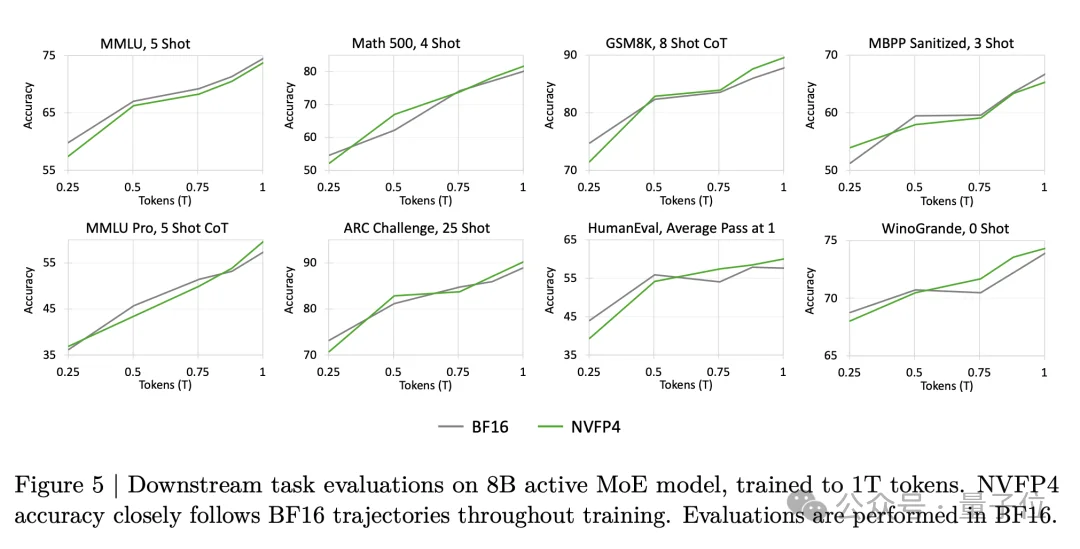
在MMLU、GSM8K、HumanEval等下游任务上,NVFP4训练的模型与BF16版本的准确率曲线几乎完全重合。
不过并非所有层都适合量化到NVFP4。团队发现Mamba输出投影层在量化后会出现高达40%的flush-to-zero现象,因此保留在MXFP8精度;QKV投影和注意力投影保留在BF16以维持少量注意力层的保真度;网络最后15%的层也保持高精度以确保稳定性。MTP层和潜在投影由于对推理时间影响很小,同样保留在BF16。
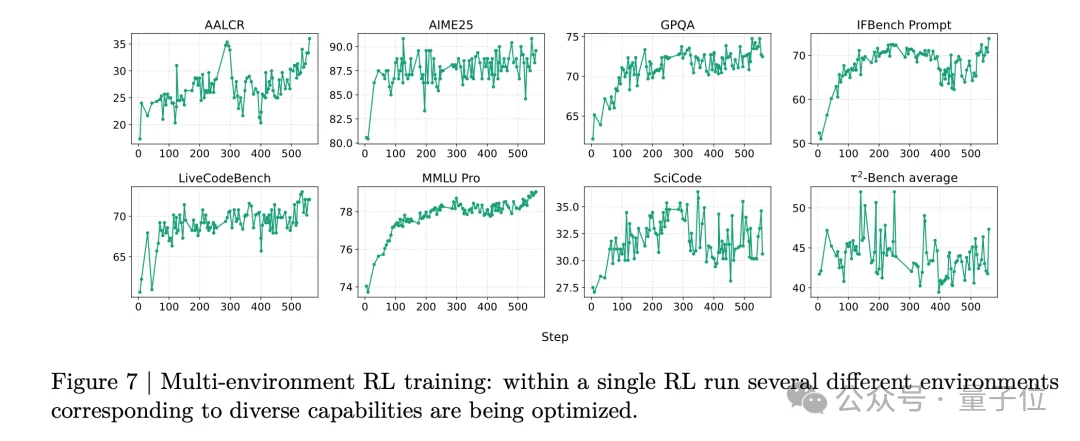
Nemotron 3的后训练采用了多环境强化学习,覆盖数学推理、竞赛编程、指令遵循、软件工程、搜索、对话、通用工具使用、长上下文等多种任务。
与之前分阶段训练不同能力的做法不同,这次英伟达选择同时训练所有任务。
论文指出,这种同步训练方式更稳定,更不容易出现reward hacking,也避免了分阶段训练常见的能力退化问题。
AIME25数学分数从80提升到90,LiveCodeBench从65提升到72,τ²-Bench工具使用从40提升到50左右,全程呈稳定上升趋势。
高效的推理吞吐量在这里发挥了重要作用。
大规模RL需要生成海量rollout样本,Nemotron 3的混合架构相比其他开源模型有显著优势。
团队还采用了异步RL架构来解耦训练和推理,并利用多token预测加速rollout生成。训练算法方面使用GRPO配合masked importance sampling来处理训练策略和rollout策略之间的差异。
整个后训练软件栈以Apache 2.0协议开源,包括NeMo-RL(可扩展RL训练)和NeMo-Gym(RL环境集合)两个仓库。
此外,Nemotron 3还支持推理时的思维预算控制。
用户可以指定思维链的最大token数,当模型达到预算时,追加一个标记即可让模型基于部分思维链生成最终回答。
论文给出了准确率与平均生成token数之间的权衡曲线,这为实际部署中的效率-精度平衡提供了细粒度控制。
论文地址:https://arxiv.org/abs/2512.20856
文章来自于微信公众号 “量子位”,作者 “量子位”



