英伟达全模态大模型 Nemotron 3 Nano Omni 来了,几秒搞定老黄3分钟演讲,吞吐量同类9倍
英伟达全模态大模型 Nemotron 3 Nano Omni 来了,几秒搞定老黄3分钟演讲,吞吐量同类9倍英伟达于昨日正式推出全新多模态推理模型Nemotron 3 Nano Omni,将文本、视觉、语音三大模态能力深度融合至单一模型体系,目前可免费使用。
来自主题: AI资讯
9291 点击 2026-04-29 19:52
 搜索
搜索
英伟达于昨日正式推出全新多模态推理模型Nemotron 3 Nano Omni,将文本、视觉、语音三大模态能力深度融合至单一模型体系,目前可免费使用。

Google 最近发了 Gemini Embedding 2,他们第一个原生多模态向量模型。文本、图像、视频、音频、文档,全部映射到同一个 3072 维向量空间。这是 Omni Embedding(全模态向量模型)的大趋势:一个架构吃下所有模态,从 jina-embeddings-v4 到 Omni-Embed-Nemotron 再到 Omni-5,大家都在往这个方向收敛。

OpenClaw又迎重磅玩家!英伟达深夜带着Nemotron 3 Super炸场,1200亿参数专为Agent打造,性能直逼Claude Opus 4.6。推理狂飙3倍,吞吐量猛涨5倍,「龙虾」这是要上天了。

英伟达在开源模型上玩的很激进: “最高效的开放模型家族”Nemotron 3,混合Mamba-Transformer MoE架构、NVFP4低精度训练全用上。而且开放得很彻底:
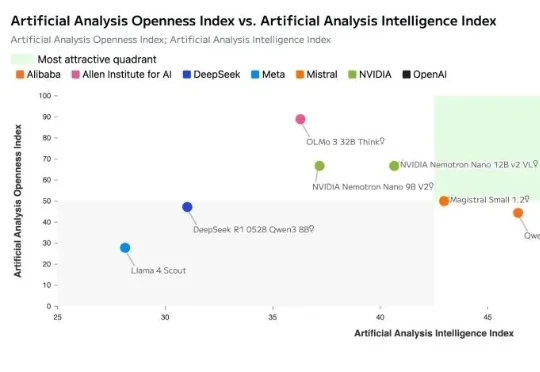
就在刚刚,英伟达正式开源发布了其新一代AI模型:NVIDIA Nemotron 3。Nemotron 3 系列由三种型号组成:Nano、Super 和 Ultra。官方介绍其具备强大的智能体、推理和对话能力。
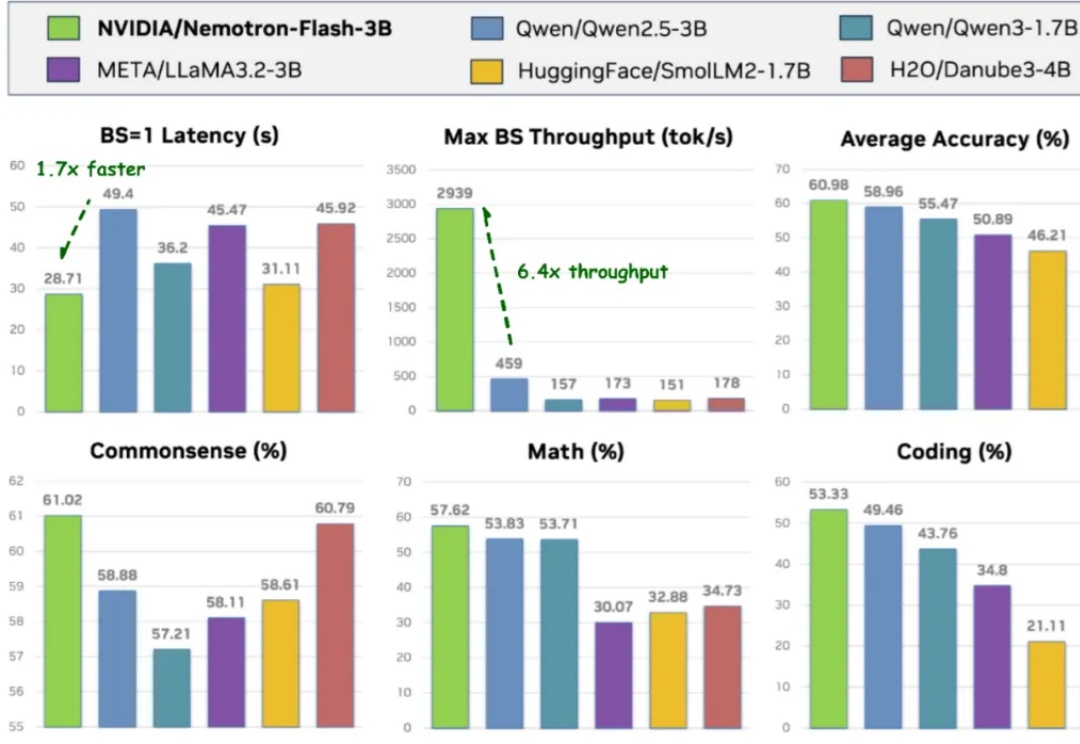
导读 过去两年,小语言模型(SLM)在业界备受关注:参数更少、结构更轻,理应在真实部署中 “更快”。但只要真正把它们跑在 GPU 上,结论往往令人意外 —— 小模型其实没有想象中那么快。
Transformer 架构对计算和内存的巨大需求使得大模型效率的提升成为一大难题。为应对这一挑战,研究者们投入了大量精力来设计更高效的 LM 架构。
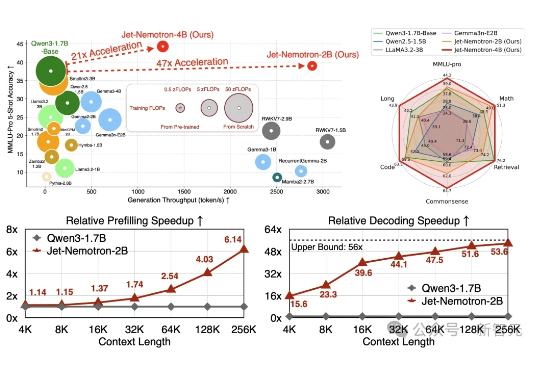
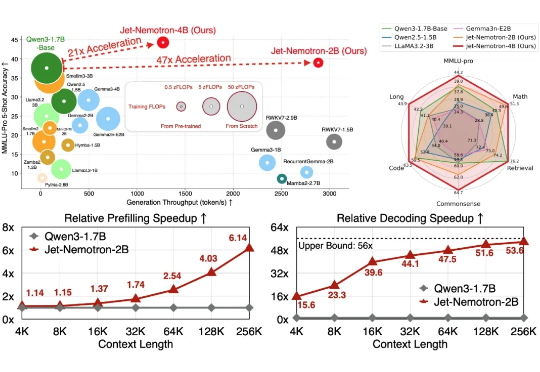
Jet-Nemotron是英伟达最新推出的小模型系列(2B/4B),由全华人团队打造。其核心创新在于提出后神经架构搜索(PostNAS)与新型线性注意力模块JetBlock,实现了从预训练Transformer出发的高效架构优化。
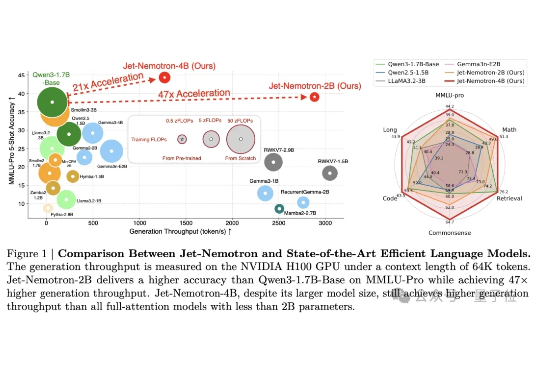
英伟达开源又放大招了! 韩松团队推出了一款全新的基于后神经架构搜索的高效语言模型——Jet-Nemotron。
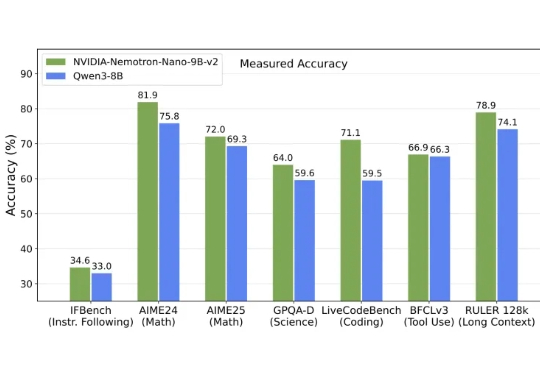
英伟达发布全新架构9B模型,以Mamba-Transformer混合架构实现推理吞吐量最高提升6倍,对标Qwen3-8B并在数学、代码、推理与长上下文任务中表现持平或更优。