# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
文本提示图像分割(Text-prompted image segmentation)是实现精细化视觉理解的关键技术,在人机交互、具身智能及机器人等前沿领域具有重大的战略意义。这项技术使机器能够根据自然语言指令,在复杂的视觉场景中定位并分割出任意目标。
然而,当前主流的技术路径,如基于监督式微调(Supervised Fine-Tuning, SFT)的方法,正面临着根本性的瓶颈。这些方法本质上是静态的模式匹配,虽然在特定数据集上表现优异,但其泛化能力往往受限,形成了一个难以逾越的 “能力天花板”。尤其是在处理需要多步、复杂推理的未知指令时,性能会显著下降,其根源在于 SFT 方法在训练中忽略了动态的、显式的推理过程。
为了 shatter 这一能力天花板,我们引入了 LENS(Learning to Segment Anything with Unified Reinforced Reasoning)框架。LENS 摒弃了静态的 SFT,转而采用端到端的强化学习(Reinforcement Learning, RL)机制,将高层次的 “思考” 过程(即思维链推理)与像素级的 “执行” 过程(即图像分割)进行动态的联合优化。通过这种设计,LENS 旨在赋予分割模型真正的、上下文感知的推理能力,从而在根本上提升其在复杂任务中的鲁棒性和泛化性。
本文将深入介绍一下我们 AAAI 荣获 Oral 的工作,“会思考的分割大模型 LENS”。有幸在这次 AAAI 2026 得到了审稿人们一致正面的评价,并被 AC 和 PC 一致同意推荐为 Oral 论文。

在这个工作中,我们研究了分割大模型领域的一大一小两个关键问题,大问题就是老生常谈的 “泛化能力”,传统分割大模型对未见过的提示和领域的泛化能力往往有限;小问题则是隐藏的 “信息瓶颈”,此前的分割大模型从 “大脑思考”(MLLM)到 “分割解码”(SAM)之间往往只通过单一的分割 Token 传递信息,存在隐形的 “信息输送瓶颈”。
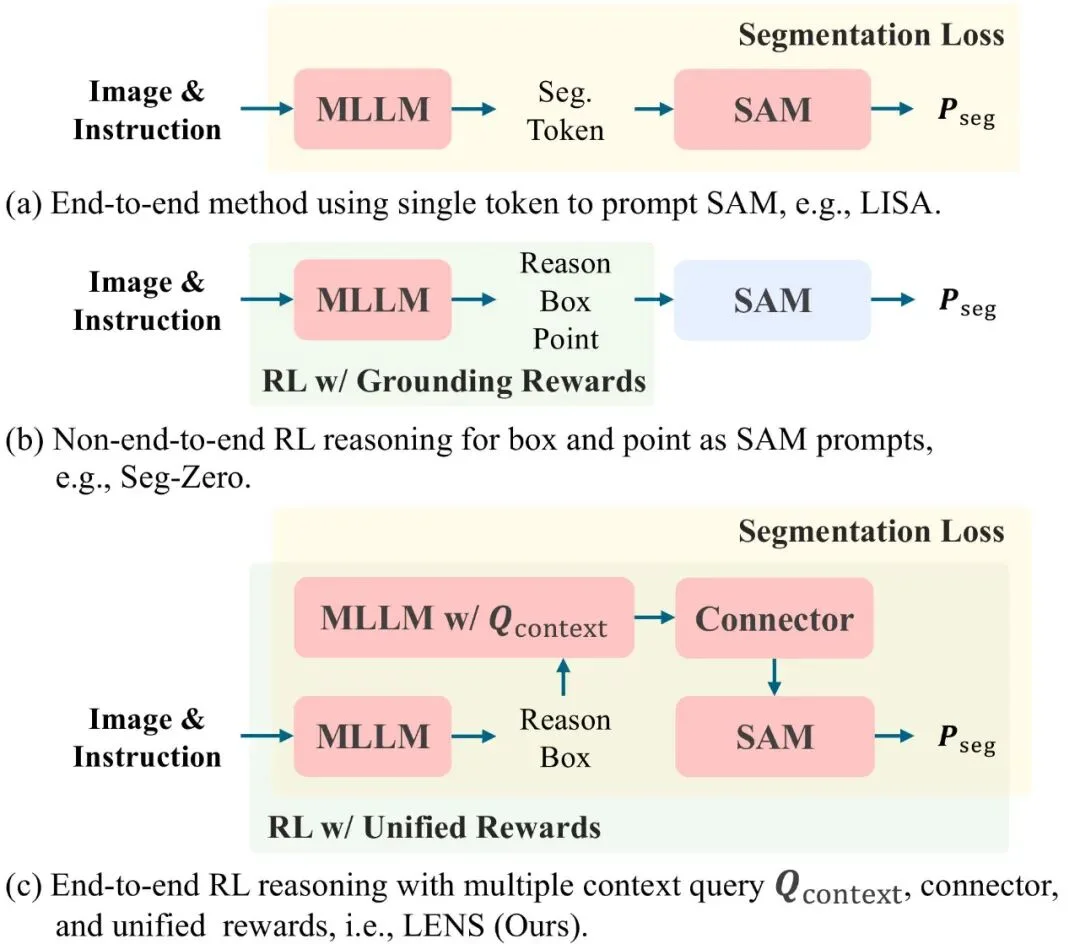
LENS 框架的核心设计在于通过端到端的联合优化,彻底打破传统模型中 “思考”(推理)与 “执行”(分割)之间的信息壁垒。
以往的方法,例如同期的优秀工作 Seg-Zero,采用的是非端到端的设计,即先由推理模型生成边界框和点提示,再交由现成的(off-the-shelf)SAM 进行分割。这种分离式流程的主要缺陷在于误差的单向传播。这意味着像 Seg-Zero 这样的非端到端模型是根本上脆弱的;它们的性能上限被其初始猜测的准确性所锁定。一旦推理阶段的定位出现偏差,下游的分割模型将无法纠正,最终必然导致分割失败。相比之下,LENS 通过其端到端的反馈闭环,具备了即便从不完美的初步定位中也能自我纠正的能力。

LENS 的整体架构由三大核心组件构成,它们协同工作,实现了从高级语义理解到精确像素输出的无缝衔接:

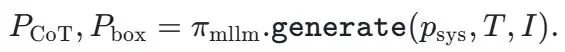

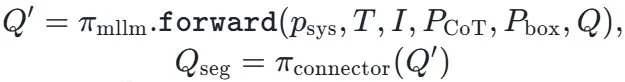
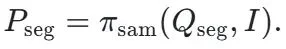
通过这种 “推理 - 桥接 - 分割” 三位一体的紧密耦合架构,LENS 实现了推理质量和分割精度的同步提升。这种设计使得最终的分割性能可以直接反作用于推理过程的优化,形成一个完整的闭环,为实现更高水平的通用分割能力奠定了基础。
LENS 框架同时在 “思考推理” 端也做出了改进,我们基于 Group Relative Policy Optimization(GRPO)方法构建了统一强化学习奖励机制(Unified Rewards Scheme)。该奖励机制是多维度的,同时监督以下三个层级的线索:

通过我们提出的联合优化(将统一的 GRPO 目标与监督分割损失相结合),LENS 能够从奖励驱动的推理改进和直接的分割监督中同时受益。值得一提的是,LENS 的端到端特性解决了定位错误(Grounding Error)向下游传播的问题,如上图右一右二所示,哪怕有些情况定位框是错的,强大的上下文查询(Context Query)也能带领分割模型走向正确。

核心结果方面,LENS 取得了文本提示分割任务的最先进性能(SoTA):LENS 在 RefCOCO 系列的基准测试中取得了 81.2% 的平均 cIoU,达到了世界最高水平。在 GroundingSuite-Eval 这类更具挑战性的零样本基准测试中,LENS 展现出卓越的域外泛化能力,cIoU 达到 78.3%,超越第二优方法接近 10%。
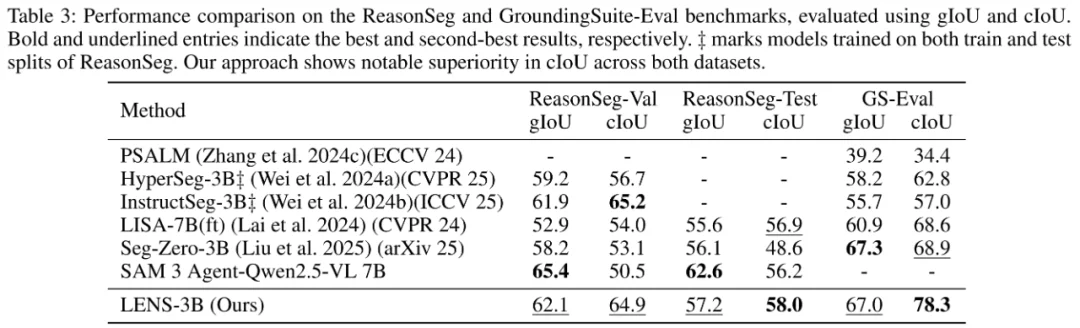
这些成果表明,LENS 这一类基于统一强化学习奖励驱动的 CoT 推理方法,能够显著提升文本提示下的分割能力。我们相信,LENS 为强化学习与视觉分割的无缝集成提供了新的思路,并有望推动更通用、更稳健的视觉 - 语言系统的研究。代码和预训练权重已开源(https://github.com/hustvl/LENS),感兴趣的朋友们欢迎研究和使用。我们也期待在 AAAI 2026 与学术界同行进行深入交流。
文章来自于“机器之心”,作者 “机器之心”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
