# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
清华大学等多所高校联合发布SR-LLM,这是一种融合大语言模型与深度强化学习的符号回归框架。它通过检索增强和语义推理,从数据中生成简洁、可解释的数学模型,显著优于现有方法。在跟车行为建模等任务中,SR-LLM不仅复现经典模型,还发现更优新模型,为机器自主科学发现开辟新路径。
长久以来,神经网络因其「黑箱」本质,虽具备强大的函数逼近能力,却难以生成人类可理解的显式规律,以至于科学界曾质疑:AI能否像牛顿那样,从观测数据中自主发现如万有引力定律般简洁而普适的解析表达式?
正是在这一背景下,符号回归因其能够从数据中直接推获得形式明确、结构清晰的数学模型而备受关注。
清华大学、中国科学院自动化研究所、格拉斯哥大学、剑桥大学、欧布达大学、南加州大学、澳门科技大学的研究团队联合提出SR-LLM,一种融合大语言模型与深度强化学习的新型符号回归框架,其核心在于引入检索增强的增量生成机制:
通过构建外部知识库,系统可动态检索与当前任务最相关的先验知识,并借助LLM的语义推理能力,将这些知识转化为具有物理意义的小型符号组合;随后,利用深度强化学习将这些符号模块高效组装为复杂但高度可解释的解析表达式。

论文链接:https://doi.org/10.1073/pnas.2516995122
这一设计使SR-LLM能够真正「站在巨人的肩膀上」进行科学探索,正如AlphaGo通过学习人类棋谱提炼高阶策略,SR-LLM则通过整合领域专家知识与历史搜索经验,引导模型聚焦于语义合理、结构优雅的解空间区域。在标准符号回归基准上的实验表明,SR-LLM显著优于现有方法;
更关键的是,在人类跟车行为建模这一尚无共识的开放问题中,它不仅成功复现了经典跟驰模型的核心结构,还从真实车辆轨迹中发现了拟合性能更优、物理意义更清晰的新模型。
展望未来,研究团队致力于发展一种类似AlphaZero的自举范式:在完全无先验知识的条件下,通过随机探索与自我优化,让系统自主构建初始知识库,并逐步演化出可解释的科学规律。
SR-LLM不仅是一个实用工具,更是一条通向机器自主科学发现的新路径。
在AI飞速发展的今天,我们早已习惯用神经网络拟合复杂数据。但长久以来,我们只能得到大量神经元堆叠而成的人们难以解析分析的复合函数,却难以像牛顿那样从现象中提炼出如万有引力定律般简洁、普适的科学规律。
但你有没有想过——能不能让AI不仅「会算」,还能「发现新的人类能看懂的定理公式」?
这正是符号回归(Symbolic Regression, SR)的目标:从数据中自动归纳出准确、简洁、可解释、具有泛化能力的数学表达式。
符号回归的基本范式可以描述如下:给定一组输入量X∈R^(n×d)与响应Y∈R^n(其中n表示数据集的大小,d表示输入量的维度),找出用输入量字符、运算字符、常数字符等基本字符组成的可解释函数f:X→Y,用以表示输入与响应之间的映射关系。
不同于目前流行的深度学习方法对于数据对(X,Y)的黑箱拟合,符号回归方法能得到更为简洁与可解释的结果,因此它的输出通常是更易于人类理解的,在物理、化学、金融等不同学科的应用场景下能够推动人类对相应领域的认知进程。
然而,现实充满挑战:数学表达式的搜索空间极其庞大,真实数据常受噪声干扰,表达式结构与参数需联合优化,并且搜索出的数学表达式内嵌的组合逻辑难以被人类理解——传统方法如遗传编程往往在复杂问题面前「卡壳」,要么搜索效率低,要么容易陷入局部最优,难以兼顾精度与可解释性。
最近,大语言模型在自然语言处理、计算机视觉等多个领域取得了巨大成功。得益于庞大的参数规模与丰富的预训练语料,大语言模型的语义理解、基于上下文的推理等能力达到了前所未有的高度。
注意到大语言模型这些优秀的能力,SR-LLM将LLM应用到符号回归领域,为树搜索提供剪枝与引导,为该领域的发展方向打开了新大门。
其核心思想是:把符号回归变成一个「增量式生成」任务,并借助大语言模型的强大推理能力来引导强化学习,不断搜索更好的定理公式。
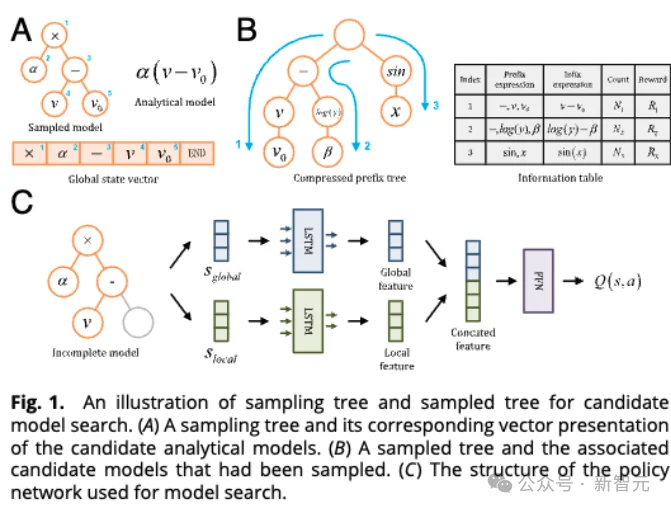
具体而言,SR-LLM的四大关键技术为:
1. Radix树存储公式搜索中获得的历史经验
所有已探索的公式被高效压缩存储在压缩前缀树中。这不仅节省内存,还能快速检索相似结构,避免重复探索。
2.双阶段强化学习搜索
第一阶段:采用「风险寻求」策略,只奖励表现最好的公式,快速聚焦高潜力区域;
第二阶段:切换到Soft Actor-Critic (SAC),利用经验回放跳出局部最优,稳健逼近全局解。
这一设计保障了SR-LLM在不借助LLM时基础的搜索能力。
3. LLM 驱动的检索增强生成
SR-LLM设计了从优秀表达式汲取公式组合知识的「反思模块」,用于将DRL探索到的优秀结果集群到外部知识库中,指导后续搜索。
「推理模块」与「反思模块」的设计使得SR-LLM在现有所有符号回归方法中脱颖而出,过去的工作只会提供优秀模型的具体解析式,而SR-LLM则额外告知人类专家这些公式是如何组合来的。
4. LLM 驱动的知识提取和利用
SR-LLM利用大语言模型对数学表达式的语义理解能力,结合外部知识库(包含领域专家模型、已经被DRL验证过的优秀表达式),利用「推理模块」动态构造提示词,引导模型生成更合理、更贴近真实规律的符号组合。
通过使用大语言模型推理的新组合字符,有效减少了表达式树所需的节点规模,进而大大缩减了搜索空间;
此外,大语言模型可以对新的字符组合提供足够的可解释性保障,进而能够引导树搜索找到更易于人类理解的字符表达式。

SR-LLM将这些功能模块巧妙的融合在一起,构建出一位自我驱动的「AI科学家」:
先根据人类已经积累的知识,大胆猜测一些不错的备选公式,接着通过LLM学习这些公式的优点和可能有用的字符表达式片段,然后使用LLM引导的强化学习持续改进搜索新的公式,反复验证、修正、提炼,最终交出最强的简洁优美的候选定理公式。
研究团队在标准符号回归基准和真实世界场景上进行了大量实验:
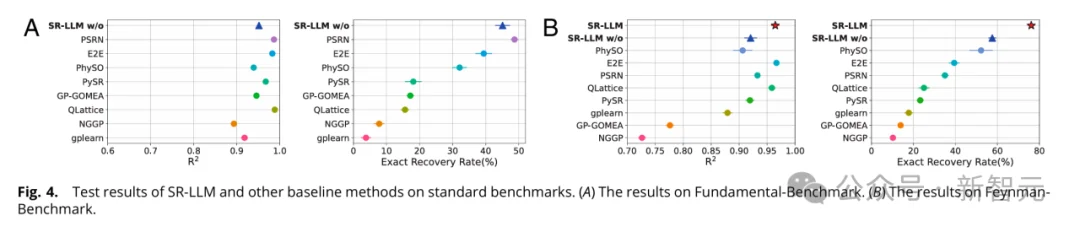
在Fundumental-Benchmarks与Feyman-Benchmarks上,显著优于PSRN,PhySO等主流方法;
在含噪数据下依然保持高鲁棒性,不易过拟合;
生成的公式结构简洁、物理意义明确;
支持多目标权衡:通过调整拟合精度、专家相似度、复杂度三项得分的权重,灵活适应不同任务需求。
更重要的是:它不是黑箱!每一个输出都是人类可读、可验证、可推广的数学表达式。
研究人员还将SR-LLM应用于「跟驰模型发现」这一具体任务,以验证其在处理真实复杂交通数据中的可行性。
跟驰模型作为刻画驾驶员纵向行为的核心工具,在交通流特性分析、微观交通仿真、以及无人驾驶车辆的决策与控制等关键领域具有不可替代的作用。
一个兼具高拟合精度与清晰物理意义的跟驰模型,不仅能够提升仿真系统的可信度,还能为理解人类驾驶决策机制提供理论支撑。
然而,从真实轨迹数据中自动发现高质量的跟驰模型仍是一项极具挑战的任务:一方面,实际采集的轨迹数据通常包含大量有偏噪声,严重干扰模型结构的准确识别;
另一方面,跟驰行为本身涉及多种经验性变量与非线性关系,其可能的模型组合空间极为庞大且复杂,难以通过人工方式高效探索。
针对上述问题,研究人员将SR-LLM应用于「跟驰模型发现」这一具体任务,在真实NGSIM轨迹数据上开展实验,在该任务上面的成功应用能够证实SR-LLM以此类推应用到物理、化学等广泛学科领域的潜力。
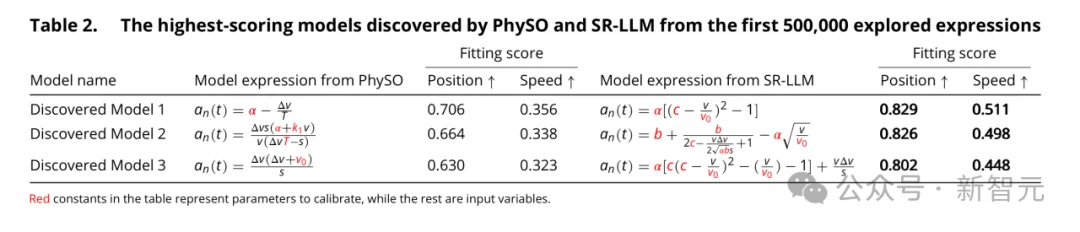

结果表明,SR-LLM不仅能在专家知识引导下成功复现经典跟驰模型,还能融合先验知识自动生成具有明确物理解释的新颖高性能模型,新模型在一些边缘数据下能够克服经典跟驰模型在遭遇突发速度变更时拟合能力变弱的缺点,充分验证了其在处理复杂真实交通数据中的有效性与潜力。
SR-LLM的成功表明,大语言模型不仅是解释已有知识的高水平教师,更是科学发现的智能协作者、乃至独立主导科学探索的智能发现者。通过将LLM强大的语义推理能力与符号回归对可解释性、简洁性与普适性的追求深度融合,迈出了「AI for Science」的关键一步。
正如AlphaGo通过学习人类棋谱提炼高阶策略,SR-LLM通过整合领域专家知识与历史搜索经验,引导模型聚焦于语义合理、结构优雅的解空间区域,这一设计使SR-LLM能够真正「站在巨人的肩膀上」进行科学探索。

展望未来,研究团队致力于发展一种类似AlphaZero的自举范式:在完全无先验知识的条件下,通过随机探索与自我优化,让系统自主构建初始知识库,并逐步演化出可解释的科学规律。
SR-LLM不仅是一个实用工具,更是一条通向机器自主科学发现的新路径,也许下一次某个学科领域的重大科学突破,就诞生于这样一个「会思考、能表达、敢创新」的AI科学家之手。
参考资料:
https://doi.org/10.1073/pnas.2516995122
文章来自于“新智元”,作者 “LRST”。



【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
