# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在电影与虚拟制作中,「看清一个人」从来不是看清某一帧。导演通过镜头运动与光线变化,让观众在不同视角、不同光照条件下逐步建立对一个角色的完整认知。然而,在当前大量 customizing video generation model 的研究中,这个最基本的事实,却往往被忽视。


多视角身份一致、镜头环绕与多人物示例
近年来,视频生成领域中关于人物定制(customization)的研究迅速发展。绝大多数方法遵循一种相似范式:给定一张或少量人物图像 → 生成包含该人物的视频。这种范式隐含了一个关键假设:只要人物在某个视角下看起来像,就等价于「身份被保留」。但在真实的视频与电影语境中,这个假设并不成立。
为什么单视角身份是不够的?
面部轮廓、五官比例、体态与衣物形态,都会随观察角度发生系统性变化。
单张或少量图像无法覆盖侧脸、背面以及连续视角变化过程中的外观一致性。
当多个角色同框时,哪怕轻微的身份漂移都会变得非常明显。
因此,在具有真实 3D 相机运动的视频中,「identity preservation」本质上是一个 multi-view consistency 问题,而不是单帧相似度问题。
然而,令人遗憾的是,显式关注 multi-view identity preservation,在当前的视频定制化生成研究中仍然几乎没有被系统性地解决。
Virtually Being 的核心论点非常明确:如果希望模型真正「学会一个人的身份」,那么它必须看到这个人在不同视角(multi-view)和不同光照(various lighting)下的稳定外观。
换句话说,看清一个人,不是看清一张脸,而是理解这个人在空间中如何被观察,在光线变化下如何呈现。身份不是一个静态的 2D 属性,而是一个 4D(空间 + 时间)一致的概念,这正是 Virtually Being 所要系统性解决的问题。
为了解决 multi-view identity 被长期忽视的问题,我们从数据层面重新设计了人物定制流程。
通过这一过程,视频生成模型在训练阶段不再依赖零散的图像线索,而是反复观察同一个人在多视角、连续镜头运动下应当如何保持外观一致。
为了在身份定制的同时保持稳定的镜头控制能力,我们采用了一个清晰解耦的两阶段训练策略。
基于 ControlNet 架构,引入完整 3D 相机参数(Plücker 表示),在大规模公开视频数据上训练模型,使其学会相机运动如何影响视角变化与时间结构。这一阶段的目标,是让模型牢固掌握电影级的镜头语言。
在预训练模型基础上进行微调,使用 4DGS 渲染的多视角视频作为定制数据,为每个身份引入专属 token,将身份与多视角外观显式绑定,最终模型在推理时能够精确遵循输入的 3D 相机轨迹,在未见过的视角下仍然稳定呈现同一个人。
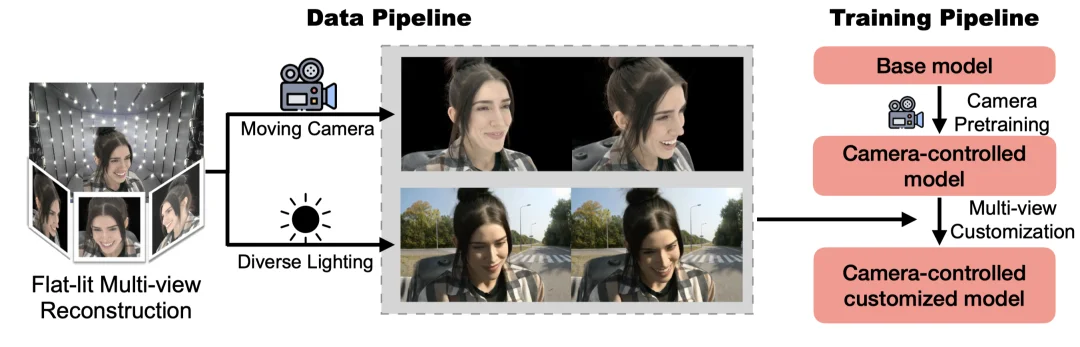
除了视角,光照同样是「看清一个人」的关键维度。
在真实电影中,人物身份并不是在单一光照条件下被认知的,而是在不同室内外环境,侧光、逆光、柔光等变化,不同光比与色温条件下逐步被观众确认。
在 Virtually Being 中,我们通过引入基于 HDR 的视频重打光数据,显著增强了生成视频中的光照真实感。在 4DGS 渲染基础上,对同一人物生成多种自然光照条件,覆盖真实拍摄中常见的照明变化范围,使模型学会在光照变化下,人物身份仍应保持稳定。
实验结果显示,引入重光照数据后,生成视频在用户研究中 83.9% 被认为光照更自然、更符合真实拍摄效果,缺乏该数据时,人物往往呈现平坦、缺乏层次的合成感。
在多人物视频生成中,multi-view identity preservation 的重要性进一步被放大。
只有当模型对每个角色在不同视角与光照条件下的身份都有稳定建模时,人物才能自然同框,空间关系才能保持一致,互动才不会显得拼接或混乱。
Virtually Being 支持两种多人物生成方式:

系统性实验表明,使用 multi-view 数据训练的模型,在 AdaFace 等身份指标上显著优于仅使用 frontal-view 数据的模型以及其他 video customization 的方法。缺失 multi-view 或 relighting 数据,都会导致身份一致性与真实感明显下降。用户研究结果同样明确偏好具备 multi-view 身份稳定性的生成结果。

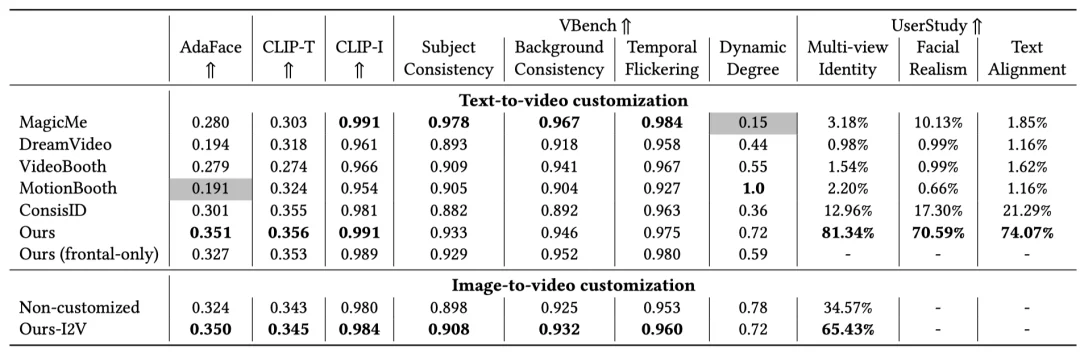
Virtually Being 并不仅仅提出了一个新框架,而是明确提出并验证了一个长期被忽视的观点:在视频生成中,身份不是一张图像,而是一个人在多视角与多光照条件下保持稳定的 4D 表现。通过系统性地引入 multi-view 表演数据与真实光照变化,我们为 customizing video generation model 提供了一条更贴近电影制作实际需求的解决路径。
文章来自于“机器之心”,作者 “徐源诚”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
