# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
LLM的下一个推理单位,何必是Token?
刚刚,字节Seed团队发布最新研究——
DLCM(Dynamic Large Concept Models)将大模型的推理单位从token(词) 动态且自适应地推到了concept(概念)层级。

DLCM通过端到端地方式学习语义边界,动态地将Token序列分割成概念,在压缩后的概念空间中进行深度推理,并借助因果交叉注意力将概念级推理结果重构为Token级预测。
由此,传统LLM中基于均匀、冗余Token信息密度的计算分配,被转化为面向概念的动态推理与自适应算力分配。
在以推理为主的基准任务上,DLCM在将推理阶段FLOPs降低34%的同时,还将平均准确率提升了2.69%。
这也意味着,大模型的推理效率并不必然依赖更密集的Token级计算,而可以通过更高层级的语义组织来获得。
接下来,我们具体来看。
如上所说,DLCM的核心在于学习动态的Token-概念映射,实现了计算资源的自适应分配。
之所以这样做主要有两方面原因:
一方面,在自然语言中,信息的分布并不是均匀的,而是集中在集中在少数语义转换的节点上。
然而,在当前的LLM中,所有token被统一处理,信息密度不均匀的自然语言消耗了同样的计算量,造成了大量的冗余与模型容量的错配。
另一方面,此前基于潜在推理的框架,如大型概念模型(Large Concept Model, LCM)等,不仅需要单独训练编码器和解码器,还依赖人为划分的固定的、句子级别的粒度,缺乏拓展性与自适应性。
针对这些问题,DLCM通过一种分层的下一token预测框架,将计算重心转移到压缩后的语义空间,实现了更高效的深度推理。

具体来说,这一框架包含四个阶段:
首先,在编码阶段,DLCM通过一个编码器,提取细粒度的Token级表示,捕获局部上下文信息,作为边界检测和最终Token级解码的基础。
接下来,在动态分割阶段,模型基于Token级表示,计算相邻Token之间在潜在空间中的局部不相似性(使用余弦距离),当不相似度超过阈值时,模型判断为一个语义断点(概念边界)。
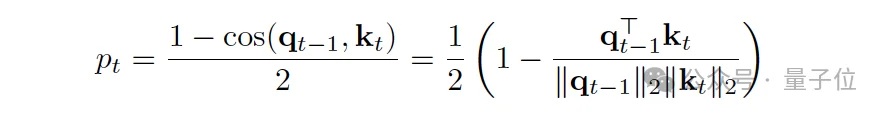
与固定句子长度不同,DLCM端到端地学习这些边界,实现内容自适应的分割。
它将同一片段内(即同一概念内)的所有Token表示进行均值池化(Mean Pooling),然后投影到更高维度的概念维度上,最终形成一个长度大大压缩的概念序列 。
然后,在概念级推理阶段,模型将上面得到的概念序列在压缩空间中进行深度的、高容量的推理,得到经过深度推理和信息整合后的概念表示。
最后,在Token级解码阶段,DLCM利用经过推理的概念表示,重构并预测下一个token。
由此,DLCM通过以上四个步骤,成功地将计算分配从低效的Token-Token交互,转移到高效的Token-概念-Token 交互,实现了计算资源的自适应、结构化利用。
虽然DLCM架构在设计上实现了Token级和概念级模块的异构,但同时也引入了新的工程和训练挑战。
DLCM 的核心优势在于它能够根据信息密度动态地划分概念。
例如,对于信息冗余度高的代码或简单文本,可以激进地压缩;对于语义复杂的转折点,则保持较低压缩比。
为实现这一点,研究引入了全局解析器(Global Parser)和辅助损失函数。
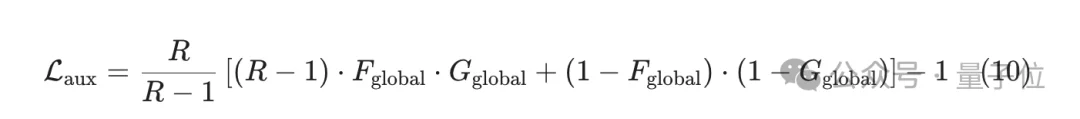
这个机制的关键在于:它不要求单个序列严格遵循目标压缩比 ,而是在整个Batch层面约束平均边界生成率。
这使得DLCM在共享全局压缩比例目标的前提下,实现了随领域变化、随内容波动的自适应分段,从而将计算资源精准地分配到语义最关键的区域。
在解码阶段,Token需要通过因果交叉注意力关注其所属的概念。
由于每个概念包含的Token数量是变化的,如果直接实现,会严重依赖效率低下的动态掩码和不规则的内存访问。
针对这一问题,研究引入概念复制(Concept Replication)策略。它将概念特征沿着序列维度复制扩展,使其长度与原始Token序列对齐。
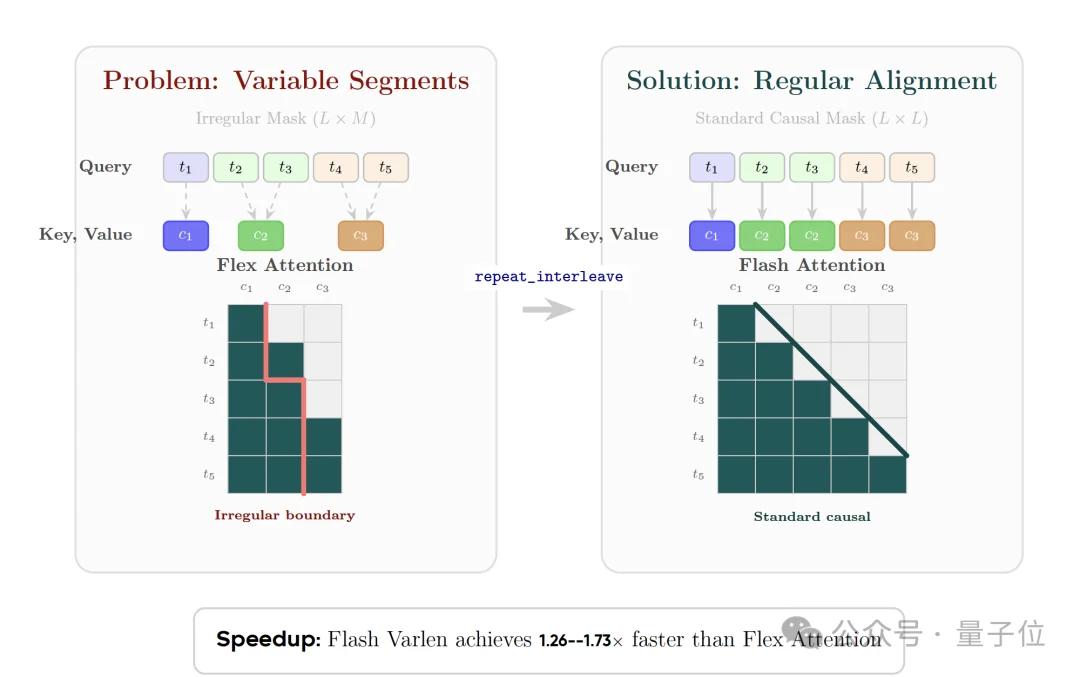
由此,研究将复杂的可变长交叉注意力问题转换为长度对齐、局部恒定的注意力问题,并使其能够利用高度优化的Flash Attention Varlen内核,获得了1.26倍到1.73倍的显著加速。
由于DLCM 的Token级组件和概念级骨干网络的宽度不一致,通过上投影连接,无法共享单一有效学习率。
为解决这一问题,研究采用解耦的最大更新参数化,为Token模块和概念模块分配了独立的宽度缩放因子,并发现各组件的有效学习率应与其宽度的倒数成比例缩放。
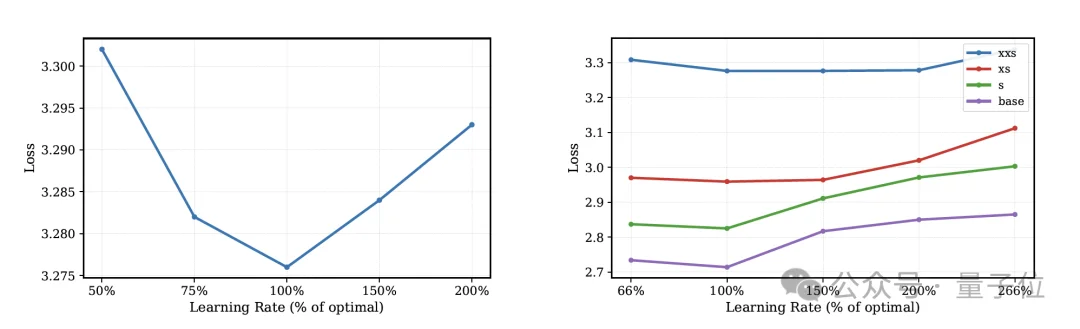
由此,研究成功地稳定了这种不等宽架构的训练,并实现了零样本超参数迁移,即小型代理模型上找到的最佳学习率可以直接用于训练更大的DLCM模型。
除上述优化外,研究还进一步基于scaling law探究了token级处理与概念级推理之间的最优分配。
研究发现,在固定压缩比下,架构效率在中等概念主干占比处达到峰值,而非随概念容量单调提升。
更重要的是,这一最优配置在规模增大时优势愈发明显:随着基线模型变大,在性能对齐的前提下,DLCM可实现越来越显著的FLOPs节省。
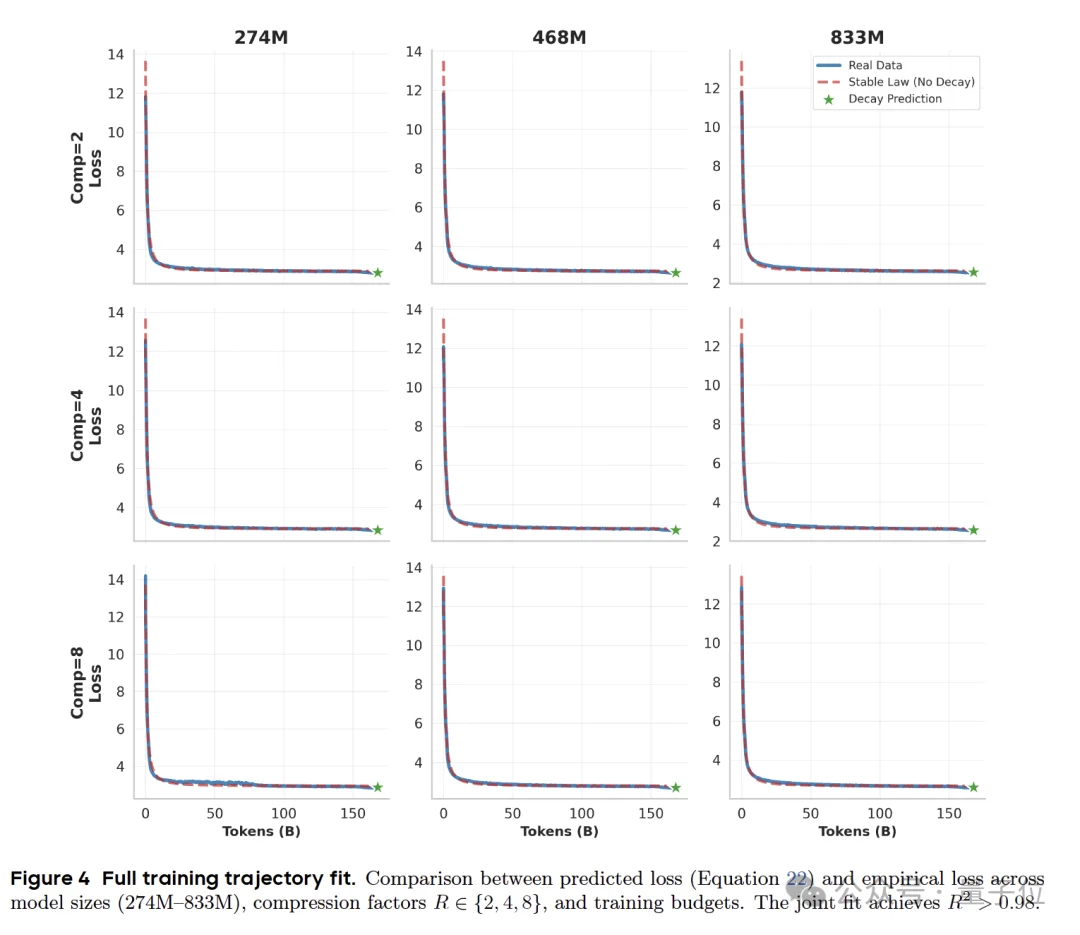
在实验阶段,研究采用了与LLaMA论文中报告的相同的全局批次大小、学习率和序列长度,让每个模型都在1T Token上进行训练。
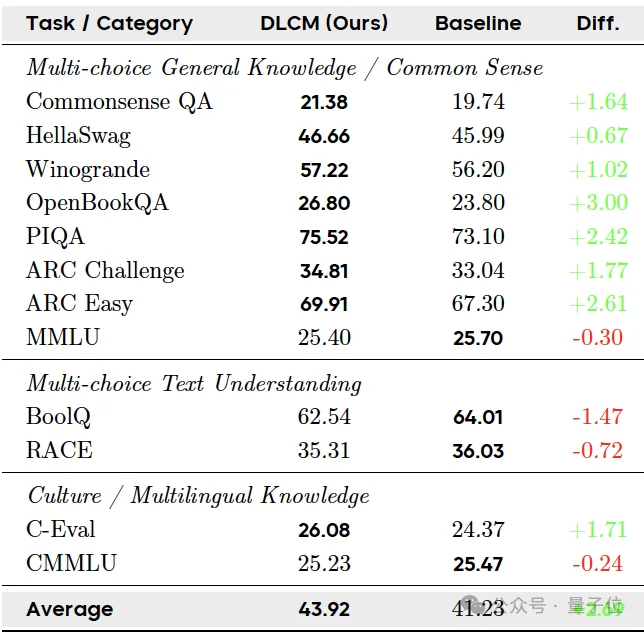
其中,DLCM实现了43.92%的平均准确率,超过了基线模型41.23%的分数,提升了2.69%。
这篇论文的一作来自英国曼彻斯特大学的在读博士生Qu Xingwei,师从Chenghua Lin教授。

他的研究方向聚焦于大语言模型(LLMs),主要包括预训练、微调、专家混合(Mixture of Experts)以及System-2大语言模型。
在教育背景方面,他本科毕业于北京航空航天大学,导师为段海滨教授;硕士就读于获慕尼黑工业大学,导师为Daniel Cremers教授。
在读博前,他曾在字节跳动和小鹏汽车担任研究工程师。
参考链接
[1]https://x.com/GeZhang86038849
[2]https://arxiv.org/abs/2512.24617
文章来自于微信公众号 “量子位”,作者 “量子位”


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
