# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
香港中文大学提出了一个全新的算法框架RankSEG,用于提升语义分割任务的性能。传统方法在预测阶段使用threshold或argmax生成掩码,但这种方法并非最优。RankSEG无需重新训练模型,仅需在推理阶段增加三行代码,即可显著提高Dice或IoU等分割指标。
在语义分割任务中,通常采用「在预测阶段,通过对概率图应用threshold 或argmax来生成mask」的传统范式。
然而,你是否思考过:这种做法真的能够最大化Dice或IoU等主流分割评估指标吗?
香港中文大学的最新研究证明了这一传统方法的次优性,并提出了一种创新性算法框架RankSEG,无需重新训练模型,仅需三行代码即可显著提升分割性能。
系列工作包括刚被NeurIPS 2025接收的高效分割算法,以及发表于JMLR的核心理论,还开源了配套的Python工具包,无需重训模型,仅通过增加三行代码,即可有效提升分割指标表现。

NeurIPS论文链接:https://openreview.net/forum?id=4tRMm1JJhw

JMLR论文链接:https://www.jmlr.org/papers/v24/22-0712.html
代码链接:https://github.com/rankseg/rankseg
如果业界从业者希望最大限度地「榨干」分割模型的性能,只需阅读第一节,即可解锁如何将RankSEG无缝集成到现有流程中。
研究人员提供了一个易用的RankSEG类,初始化时可指定需要优化的分割指标(如 Dice、IoU 等)。随后,只需调用predict方法并输入概率图,即可获得优化后的预测结果。
实际使用时,只需将原有的probs.argmax(dim=1)替换为rankseg.predict(probs),即可轻松集成,无需过多改动,简单高效。
from rankseg import RankSEG
# 1. Initialize RankSEG (optimizing for Dice)
rankseg = RankSEG(metric='dice')
# 2. Get your model's probability outputs (batch_size, num_classes, *image_shape)
probs = model(images).softmax(dim=1)
# 3. Get optimized predictions; replace `preds = probs.argmax(dim=1)`
preds = rankseg.predict(probs)

RankSEG与传统argmax方法的效果对比,使用同一个训练好的模型,唯一的区别仅在推理阶段的处理方式。图中用红框进行了重点标注:在第一个例子中,RankSEG 成功识别出桌子上的小瓶子;在第二个例子中,RankSEG成功分割出了被遮挡的人脸;第三个例子捕捉到更完整的肿瘤块。可以明显看出,RankSEG在小物体识别和处理被遮挡等复杂场景时,分割效果相较于传统 argmax 有显著提升。

Demo链接:https://huggingface.co/spaces/statmlben/rankseg
QuickStart:https://colab.research.google.com/drive/1c2znXP7_yt_9MrE75p-Ag82LHz-WfKq-?usp=sharing
文档链接:https://rankseg.readthedocs.io/en/latest/index.html
目前主流的分割流程,通常通过训练模型来估计每个像素的类别概率,随后采用threshold或argmax方法生成最终的预测掩码(Mask)。
这种逐像素分类(pixel-wise classification)的方法,优化目标是像素级的准确率;但分割任务真正关心的,是整体的重合度指标(如Dice或IoU),二者并不完全一致。
理论上,传统的threshold / argmax预测方式是次优的(suboptimal)。例如,在下面这个由两个像素组成的简化场景中,即便其中一个像素的预测概率低于0.5,为了获得最优的Dice分数,依然应该将其判定为前景。简单来说,逐像素最优解不一定能带来全局最优的分割效果。
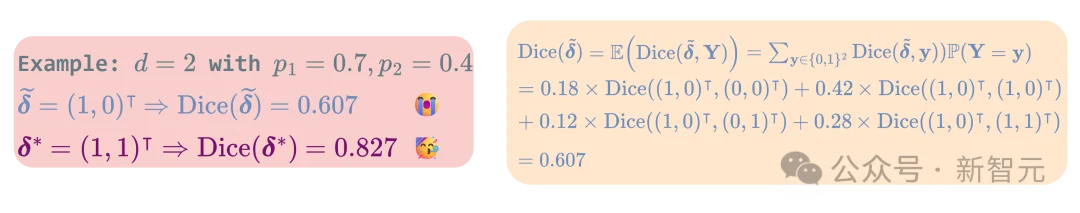

可以看到,这种预测方式对应的Dice分数并未达到最优;而为了获得最优的Dice,实际上应当将第二个概率低于0.5的像素也判为前景,这个例子直观地揭示了传统threshold/argmax方法在整体分割性能上的局限性。
那么,如何才能获得最优的分割预测呢?下面的定理给出了理论上的解答,并指出了实现该最优性的具体方法(这里以Dice指标为例,类似的思路同样适用于IoU优化)。

这个定理可以分为以下几个关键部分理解:
Dice期望的计算
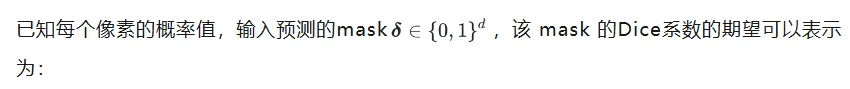
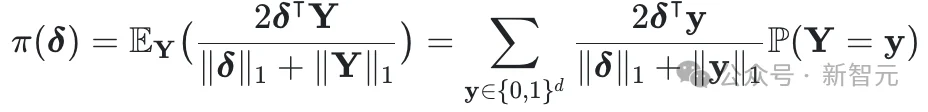
只要遍历所有可能的二值 mask,计算对应的Dice期望,并取最大的那一个就能获得最优解。然而,所有mask的组合数为2的d次方,计算量呈指数增长,直接穷举在实际应用中不可行。
排序性质
定理进一步指出,只需关注这样一类特殊的mask:
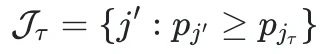

自适应阈值的最优预测规则
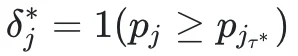

符号记号及期望公式的化简:为简化后续推导,我们将上述Dice期望重写如下:
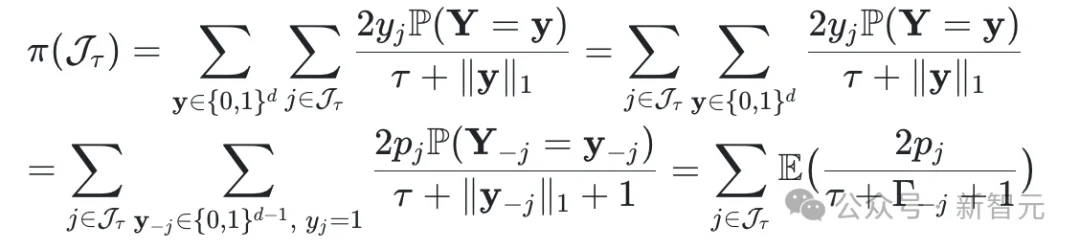

RankSEG定理直接以寻找Dice最优预测为目标,巧妙地利用排序性质,带来了简洁且高效的分割预测方法。不过,在定理的实际应用过程中,仍存在两个主要挑战:
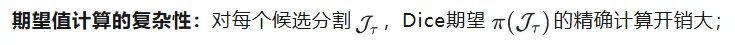
多类别分割的最优刻画困难:在多类别(multi-class)语义分割场景下,由于每个像素只能归属于一个类别(即「无重叠」约束),最优预测的刻画以及直接优化全局指标都变得更加复杂和棘手。
针对以上难点,研究人员引入近似化的技巧,旨在进一步简化计算,同时提出更为实用(practical)的算法方案,以促进RankSEG在各类实际分割任务中的高效应用。
RankSEG的计算复杂度较高,限制了其在高维图片中的实际应用,最新的算法(NeurIPS 2025)引入倒数矩近似和多类别分割。
倒数矩近似



多类别分割
RankSEG的框架可以自然地扩展到multi-label场景(即单个像素允许属于多个类别)。然而,在多类别单标签(multi-class)分割任务中,每个像素只能分配一个类别的「非重叠」约束,使得直接扩展RankSEG会涉及到复杂的匹配(assignment)问题,计算复杂度显著提升。
为此,研究人员提出如下近似算法,兼顾了效率与精度:
1. 独立二值分割:对每个类别独立应用RankSEG-RMA算法,分别获得各自的binary mask。
2. 去除重叠:对于预测结果中重叠的区域,仅保留masks之间无重叠部分,舍弃多类别同时预测的像素。这一步可能导致部分像素没有被分配给任何类别。

这种方法虽然在最后一步引入了 argmax 机制,但与传统方法相比,具备以下两个显著优势:
选择性使用argmax:只有在重叠区域才采用argmax,而大部分像素预测仍然由RankSEG原始算法直接决定,充分发挥了RankSEG的优势。

但实验结果显示,在兼顾计算效率的同时,该方法能够带来不错的分割性能提升,体现出了合理的实用价值。
研究人员在多个主流分割数据集(如PASCAL VOC, Cityscapes, LiTS, KiTS等)和多种深度学习模型上进行了广泛实验,验证了RankSEG系列方法的优越性。
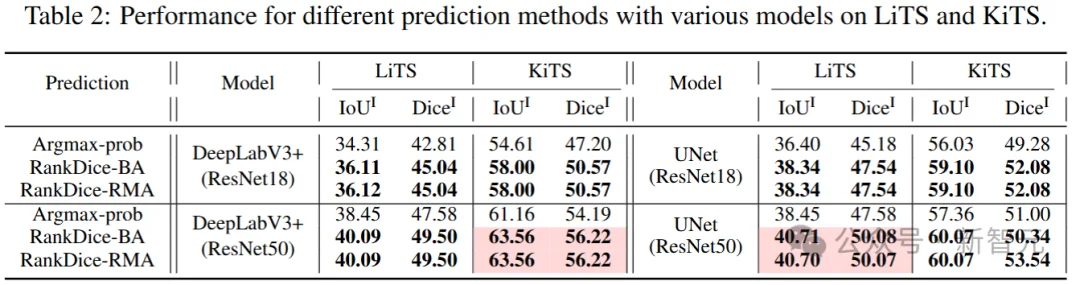
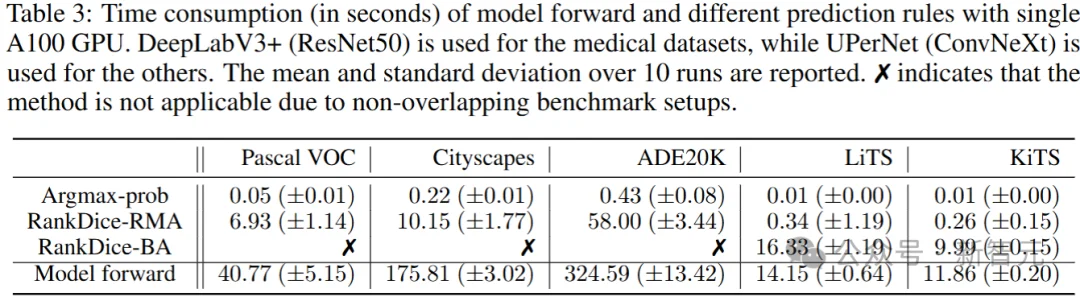
从表中结果可以观察到:
参考资料:
https://openreview.net/forum?id=4tRMm1JJhw
文章来自于“新智元”,作者 “LRST”。


