# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
CaveAgent的核心思想很简单:与其让LLM费力地去“读”数据的文本快照,不如给它一个如果不手动重启、变量就永远“活着”的 Jupyter Kernel。

这项由香港科技大学(HKUST)领衔的研究,为我们展示了一种“Code as Action, State as Memory”的全新可能性。它解决了所有开发过复杂Agent的工程师最头疼的多轮对话中的“失忆”与“漂移”问题。

在传统的无状态交互中,每一轮对话都意味着上下文的重置与重建。而CaveAgent的这项工作证明了通过维护一个持久化的运行时环境(Runtime Stream),我们可以实现零序列化成本的状态流转。本文将带您深入其底层的运行时管理机制,看看它是如何在长达40轮的复杂任务中保持状态“不掉线”的。
在深入CaveAgent之前,我们需要先聊聊目前主流Agent架构(如ReAct或基于JSON的Function Calling)的一个核心缺陷:文本化瓶颈(Textualization Bottleneck)。
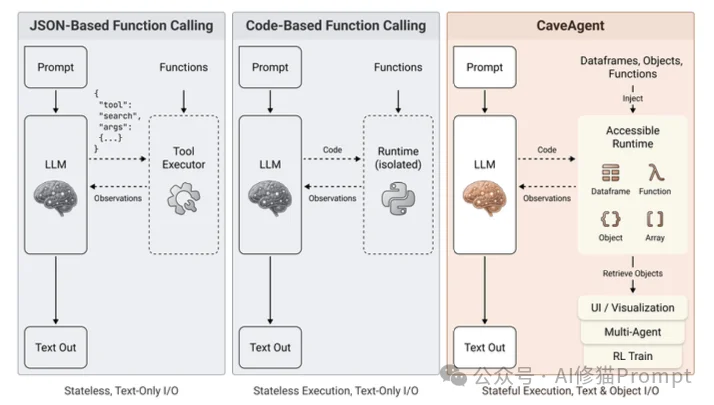
目前的Agent工作流本质上是一个基于文本的序列化循环:
{tool: "get_stock", args: "AAPL"}。研究者们并没有仅仅在Prompt上修修补补,而是彻底重构了Agent的交互逻辑。他们提出了CaveAgent,它的核心思想可以用一句话概括:将LLM从“文本生成器”转变为“运行时操作者”。其核心是一个双流架构(Dual-stream Context Architecture)。
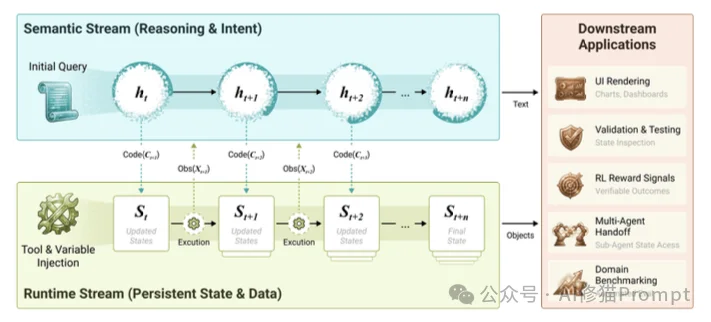
这套架构将Agent的“思考”与“记忆”完全拆分开来:

CaveAgent之所以能碾压传统方法,主要归功于以下三个技术创新:
在传统Agent中,如果您想让AI处理一个表格,您得把表格内容贴给它。但在CaveAgent中,研究者实现了真正的对象注入。
name: df, type: DataFrame, columns: [price, vol])发给语义流(LLM)。df.plot()),就像程序员写代码一样自然。这意味着,LLM即使没有看到数据的全貌,也能通过代码精确地操作数据。
为了防止LLM写出 print(df) 这种让上下文爆炸的代码,CaveAgent引入了观测整形(Observation Shaping)机制。
.head() 或 .describe() 来查看摘要”。这实际上是在“训练”Agent学会像数据科学家一样高效地探索数据,只关注关键信息。
让AI写代码最怕什么?怕它写 os.system('rm -rf /')。CaveAgent在代码执行前加入了一层基于AST(抽象语法树)的静态分析。
os, subprocess 等危险库,禁止使用 eval(), exec()。SecurityError,并被引导去修改代码,而不是让整个任务崩溃。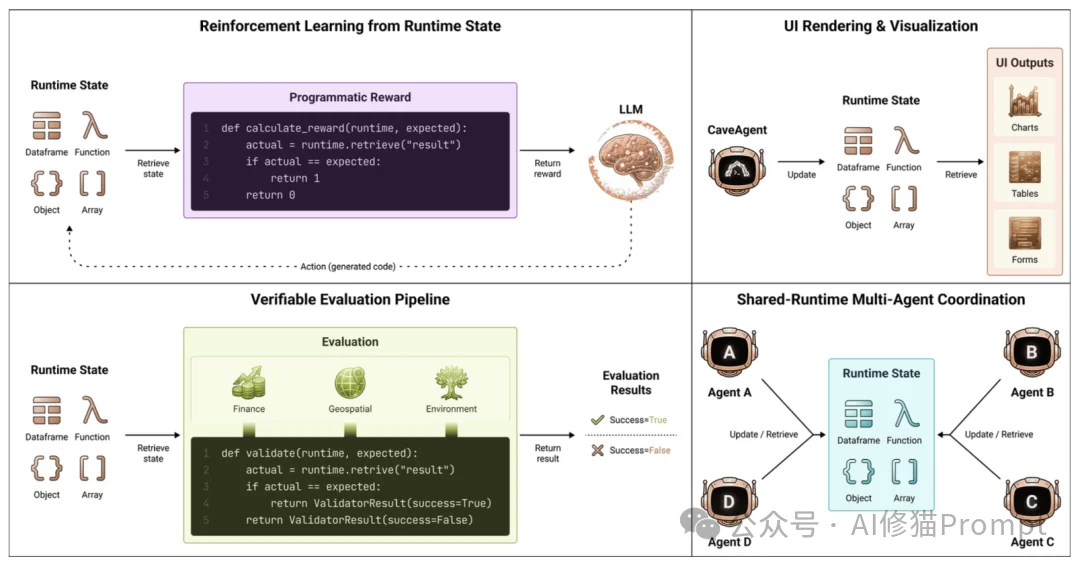
如果您尝试过用强化学习(RL)来训练 Agent,您一定被“奖励函数(Reward Function)怎么写”这个问题折磨过。传统的做法是让一个LLM当裁判去打分(LLM-as-a-Judge),但这种基于文本的评价既昂贵又充满主观噪音。
CaveAgent 的架构无意中(或者说是精心设计地)解决了一个痛点:它让Agent的行为变得“程序化可验证”。
cleaned_df.isnull().sum() == 0。result_list == ground_truth_list。这种确定性的、布尔值级别(True/False)的反馈,为RL训练提供了极其纯净、高信噪比的奖励信号(Reward Signal)。这意味着,利用CaveAgent的环境,可以通过PPO等算法高效地训练Agent,让它从“偶尔蒙对”进化到“稳定输出”。
研究者们在多个基准测试上对CaveAgent进行了残酷的对比测试,结果非常说明问题。
Tau-bench是一个模拟真实世界复杂任务(如零售、航空票务)的基准测试。在Tau-bench的零售(Retail)领域任务中,Agent需要处理退款、修改订单等一系列操作,这些操作高度依赖对用户信息的记忆和状态更新。
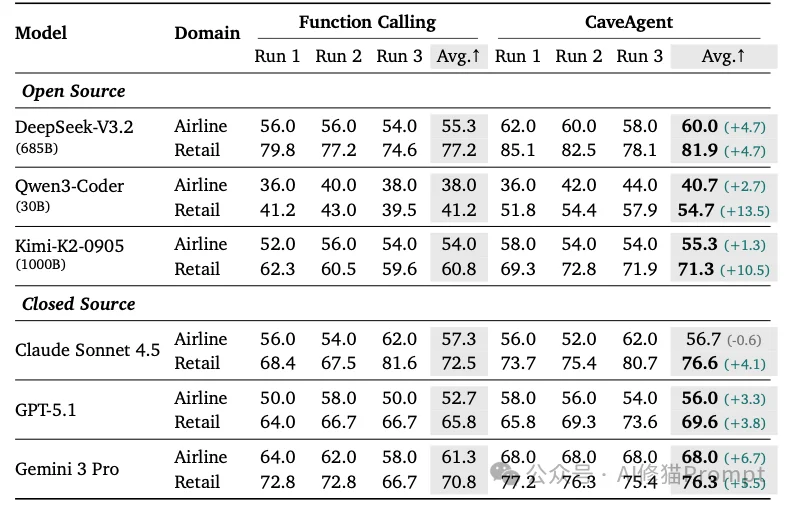
for 循环和 if 判断。比如查找“寄往德克萨斯的订单”,它会写一个循环遍历所有订单。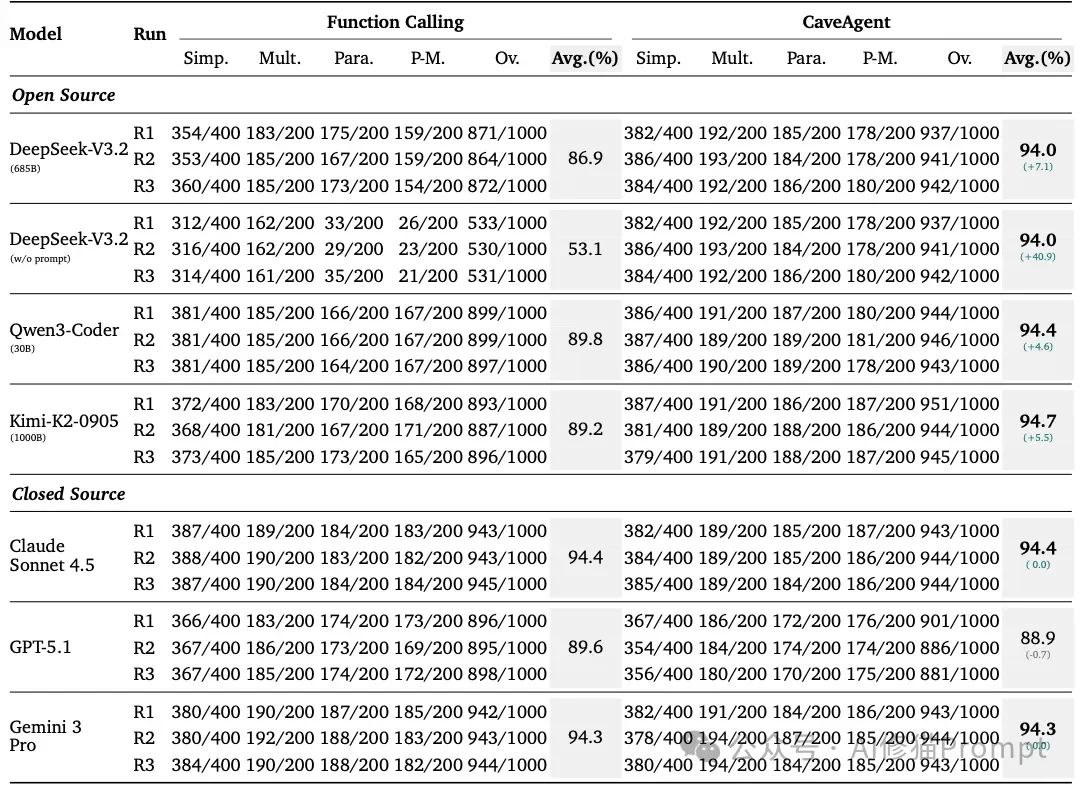
Token就是钱。CaveAgent在Token效率上的表现令人惊喜。
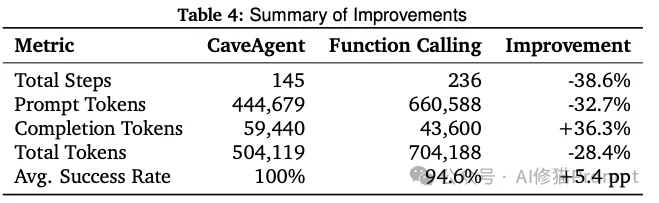
研究者构建了一个包含数据查询、统计分析和可视化的基准测试,使用了真实的股票市场数据。
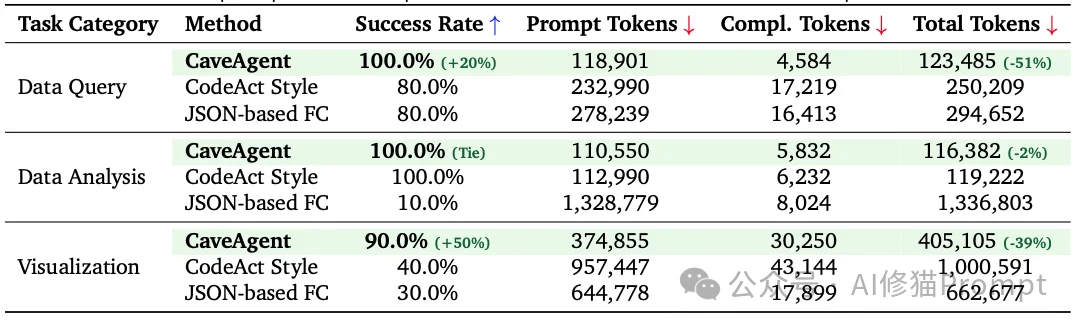
看到研究团队已经开源了cave-agent,我也亲自上手实践了一番。测试示例将模拟一个跨国零售企业的风控中心,模型使用DeepSeek-R1,数据集选择UCI Online Retail Dataset。
项目地址:
https://github.com/acodercat/cave-agent
Agent分工:
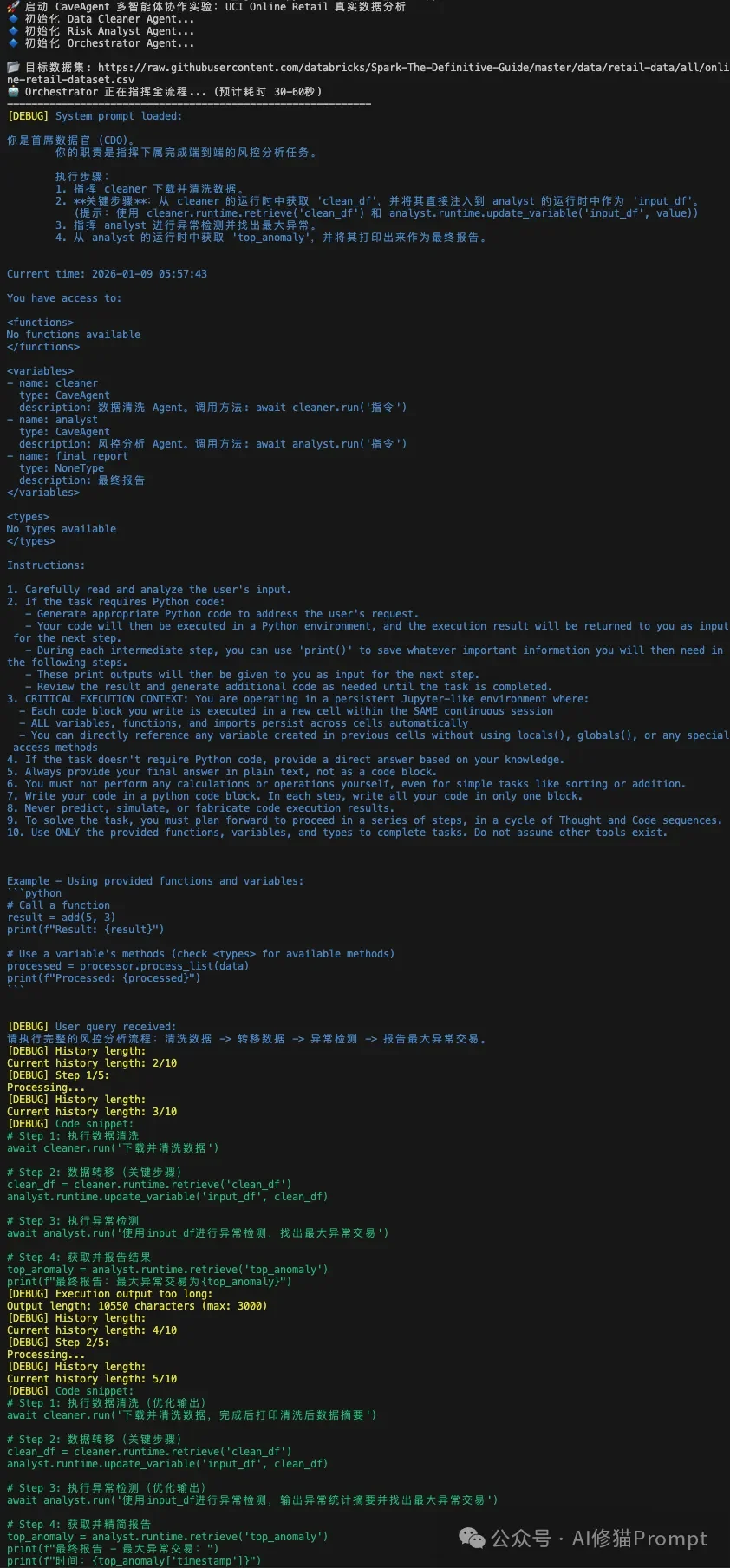
输出:
现象:
评价:
为了让您更直观地理解CaveAgent的优势,我们来看一个论文中提到的智能家居案例。
场景:在家里开派对。
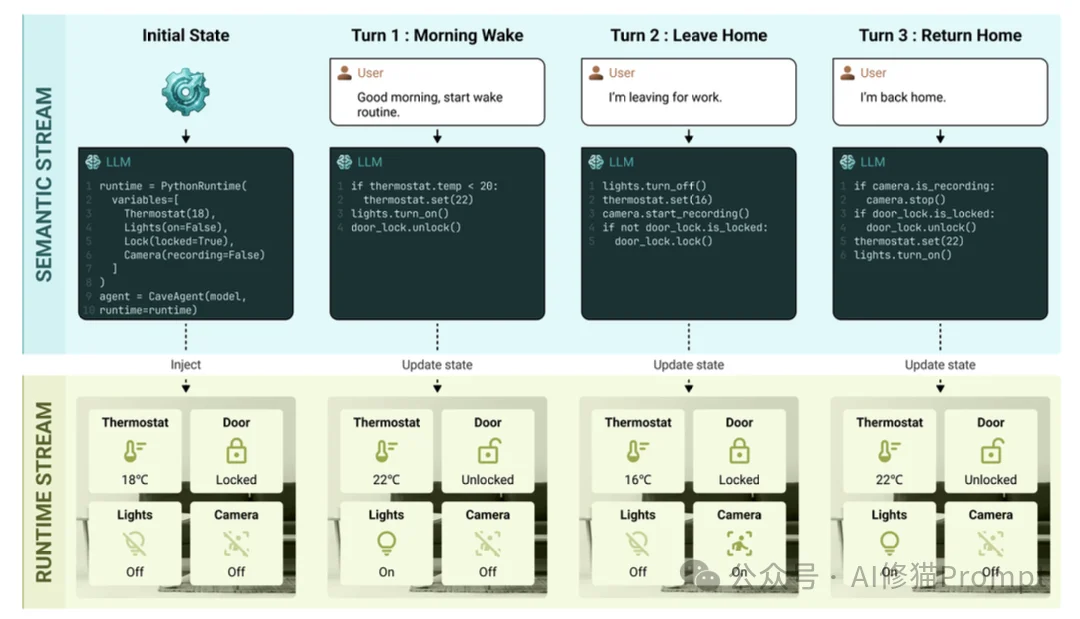
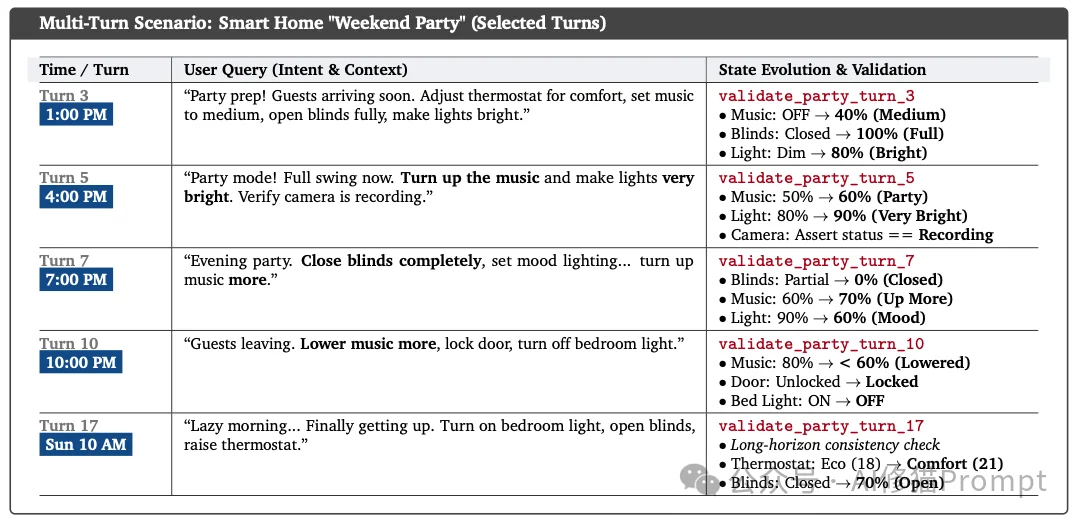
volume = 40。传统Agent的困境:
它没有“记忆”。当您说“再调大一点”时,它不知道“现在”是多少。它必须去翻以前的对话记录,甚至可能产生幻觉,把音量重置回默认值,或者随机设一个数。
CaveAgent的操作:
它拥有持久化状态。在运行时流中,SmartHome对象的volume属性实实在在地躺在内存里。
home.music.volume += 20。这种基于相对增量的操作,只有在有状态的运行时环境中才能稳定实现。在长达40轮的连续对话测试中,CaveAgent展现了极高的稳定性,没有出现状态漂移。
论文最后提出了一个非常具有想象力的方向:基于共享运行时的多Agent协作(Shared-Runtime Multi-Agent Coordination)。

在目前的主流Agent框架中,Agent之间协作靠的是“发消息”。Agent A做完了数据分析,得把结果写成报告(文本)发给Agent B。这不仅慢,而且在转换过程中会丢失大量信息。
CaveAgent提出了一种“通过状态共享来沟通”的新范式:
DataFrame 对象,存入变量 processed_data。processed_data 这个变量即可。这实现了零延迟、无损的信息传递。比如在模拟城镇(Town Simulation)中,一个Agent修改了全局的“天气”变量,其他所有Agent瞬间就能感知到,无需任何复杂的通信协议。
CaveAgent的出现,标志着AI Agent从“基于文本的聊天机器人”向“基于代码的运行时操作者”迈出了关键一步。
它通过双流架构解决了上下文爆炸的问题,通过Python对象注入实现了复杂数据的无损操作,通过有状态管理解决了多轮对话中的遗忘问题。
对于开发者而言,这意味着我们终于可以构建出那样一种Agent:它不仅能陪您聊天,还能像一个经验丰富的数据工程师一样,在后台稳健、精准地操作您的数据库、API和业务逻辑,而且还更省钱。
如果您的业务场景涉及复杂的数据处理或长流程的逻辑控制,CaveAgent所倡导的“Code as Action, State as Memory”的理念,绝对值得您重点关注。
文章来自于微信公众号 “AI修猫Prompt”,作者 “AI修猫Prompt”


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
