# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当视频生成开始尝试构建可交互的“世界模型”,真正的瓶颈正逐渐从画质指标转向如何在长时间、强交互下持续记住这个世界。
上海AI Lab联合多家机构开源的Yume1.5,针对这一核心难题提出了时空信道联合建模(TSCM),在长视频生成中实现了近似恒定计算成本的全局记忆访问。
借助这一设计,Yume将长时记忆、实时推理与“文本+键盘”的交互控制整合进同一系统,展示了世界模型工程化落地的可行路径。

在生成式人工智能从静态图像向动态视频迈进的浪潮中,构建能够理解物理规律、具备长期记忆并支持实时交互的“世界模型”(World Model)已成为通往通用人工智能(AGI)的关键路径。
上海AI Lab联合多所顶尖机构在7月份开源了Yume1.0,这是第一个完全开源的面向真实世界的世界模型(包括数据、测试集、训练/推理代码和权重),并且在近期推出了Yume1.5。
Yume项目是一个持续迭代的世界模型,引入了核心架构创新——时空信道联合建模(TSCM)。
该框架通过统一的上下文压缩与线性注意力机制解决长视频生成的记忆瓶颈;设计了基于TSCM与Self-Forcing结合的实时加速策略。

Yume的核心设计在于三个层面:

1. 数据:通过开源和引入Sekai数据集训练(覆盖全球750个城市、累计时长达5000小时的高质量第一人称(POV)视频数据)。
此外,Yume1.0引入了一种量化相机轨迹方法,能够将现实世界的运动转换为离散的键盘按键。
同时Yume1.5额外引入了高质量的T2V合成数据集,并且为了实现“事件生成”(如“突然出现幽灵”),团队构建了一个专门的事件数据集。
2. 架构:提出了TSCM等架构,将历史帧在时间、空间和通道三个维度进行压缩,将长上下文推理的复杂度降低。
3. 交互:构建了“文本+键盘”的双重控制体系。用户不仅可以通过WASD键控制漫游,还能通过自然语言实时编辑环境事件。
Yume1.5的技术核心在于解决长视频生成中的记忆与计算矛盾,提出了TSCM架构。
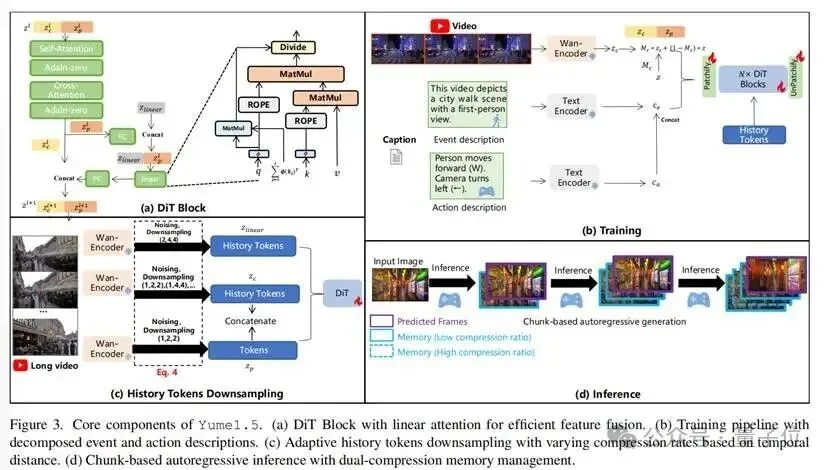
标准的Self-Attention机制计算复杂度过高。
(1) 存储所有历史Token的KV Cache会瞬间耗尽GPU显存。(2) 每一帧的生成时间会随着历史长度线性增加,无法满足实时交互需求。
TSCM通过将历史信息分流处理,巧妙地规避了上述瓶颈。它包含两个并行的压缩流:时空压缩和通道压缩。
时空压缩:
这一流主要负责保留视觉细节,通过对历史帧进行不同程度的时空下采样来减少Token数量。
这个方法参考了FramePack的设计:近期的记忆清晰,远期的记忆模糊。首先对历史帧数按照每32帧进行随机的时序采样,以压缩时序信息,然后执行空间压缩。
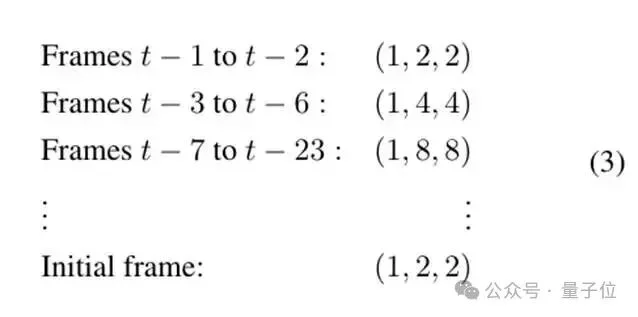
这种自适应策略,使得模型在关注当前帧生成时,能够以极低的代价访问到很久以前的上下文信息。
通道压缩:虽然时空压缩减少了Token数量,但在处理超长序列时仍显吃力。为此,Yume1.5引入了通道压缩,配合线性注意力机制。
特征融合:
DiT模块内部设计了的融合层,将时空压缩提取的特征与通道压缩提取的特征进行拼接和融合。
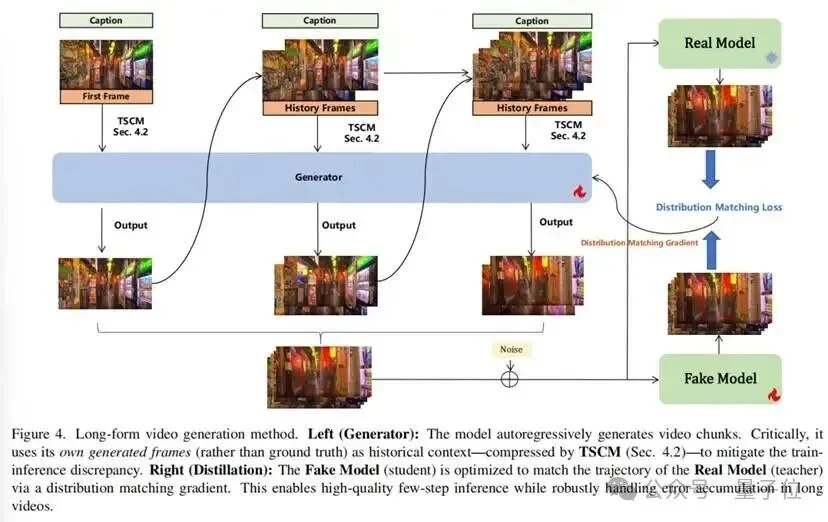
Yume1.0和Yume1.5在推理加速方面进行了优化。Yume1.0引入了OSV(一种对抗蒸馏方法)以加速扩散模型的采样。
Yume1.5引入了类似于Self-Forcing的训练策略。在微调阶段,不再给模型输入真实的上一帧,而是让模型先生成上一帧,再将其作为条件输入来预测当前帧。
与Self-Forcing不同的是,Yume1.5引入了TSCM替换了滑动窗口的kv cache以获得全局的上下文输入,这种方式训练非常高效,训练长度为64帧即可外推到近半分钟的视频。
为了提高推理效率,Yume1.5并未将所有文本信息送入编码器。它创造性地将提示词解耦为事件描述和动作描述。
动作描述:如“向前走”、“向左转”。这类描述词汇量有限且固定。系统预先计算并缓存了这些动作的T5Embedding,无需重复进行繁重的文本编码计算。为了让用户的键盘操作能够精确控制视角,Yume1.5定义了一套详细的动作词汇表。

事件描述:描述生成信息。这类描述仅在初始化或用户输入新指令时通过T5编码器处理一次。
这种解耦与缓存策略,显著降低了T5文本编码器在实时推理中的计算占比。
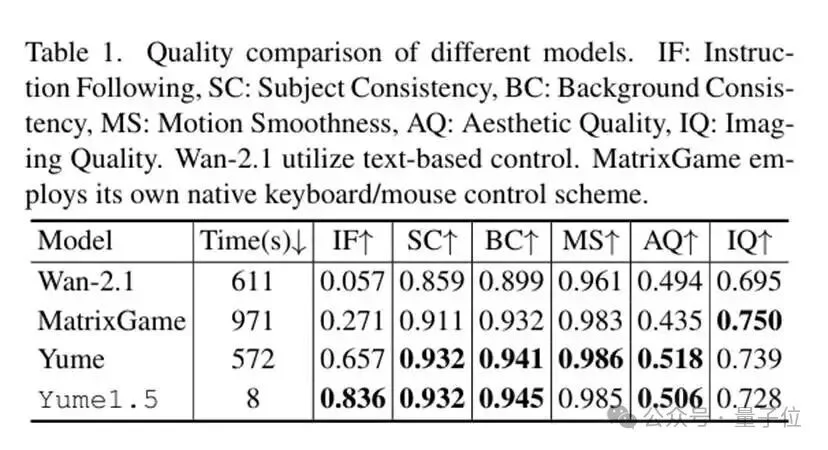
1. 指令跟随:Yume1.5的IF得分高达0.836。这直接证明了控制方法的有效性。
2. 生成速度:从Yume1.0的572秒缩短至8秒。
消融研究:
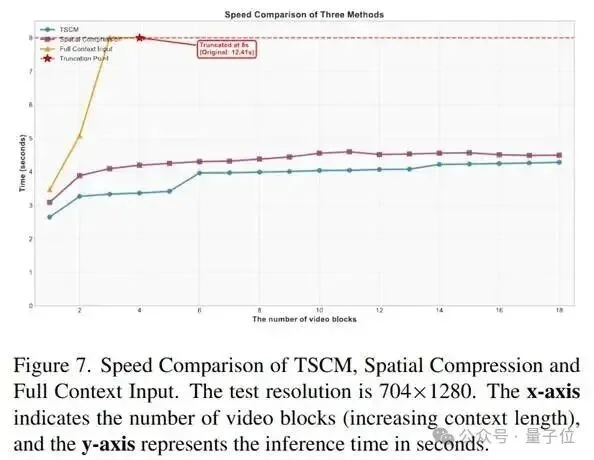
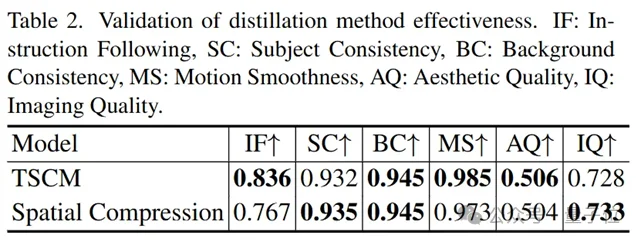
Yume的模型权重、推理代码、训练代码以及Sekai数据集全部开源。
为了方便使用和测试Yume-5B,Github主页提供了Windows下的一键启动方案来运行Web Demo。
只需运行run_oneclick_debug.bat,然后在浏览器中打开显示的URL即可。该程序已在RTX4090Laptop GPU(16GB)上测试通过。
物理逻辑缺失:模型缺乏物理引擎支撑,偶发因果谬误(如倒行)及长周期细节漂移,TSCM仅起到缓解作用。
模型规模权衡:当前使用5B模型妥协实时性。为突破瓶颈(如迈向30B+规模),未来将采用MoE架构以兼顾高性能与低延迟。
Yume和数据集的开源,期望能加速世界模型的研究。随着技术的迭代,我们有理由相信,在不远的将来,区分“真实”与“生成”的界限将变得愈发模糊。
论文链接:https://arxiv.org/pdf/2512.22096
开源代码:https://github.com/stdstu12/YUME
主页链接:https://stdstu12.github.io/YUME-Project
数据链接:https://github.com/Lixsp11/sekai-codebase
文章来自于微信公众号 “量子位”,作者 “量子位”


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
