# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
企业级场景中,无论是做RAG还是agent,我们都会面临一个问题:出于数据隐私以及合规要求,数据必须保留在本地。但传统的本地存储方案往往存在数据隔离性差、崩溃易丢数据、配置管理混乱、操作不可撤销等问题。
Claude Code 通过一套精心设计的存储体系,系统性地解决了这些痛点。
以下为核心思路的太长不看版:
多项目隔离问题:路径编码的项目目录 + Session文件独立存储 → 不同项目数据物理隔离,无交叉干扰;
数据丢失问题:JSONL流式追加写入 + 每条消息实时持久化 → 崩溃时仅可能丢失最后一行未写入数据,损失最小化;
对话追溯问题:uuid+parentUuid消息链 + 完整消息类型(thinking/tool_use/summary) → 可回溯每一轮交互的上下文、工具调用逻辑;
操作不可撤销问题:file-history-snapshot前置备份 + 哈希存储原始内容 + 快捷键撤销 → 支持一键回滚代码修改,无风险;
配置灵活度问题:三级配置体系(全局→本地→项目) + 权限优先级(deny>ask>allow) → 兼顾统一管理与局部定制,同时保障安全;
功能扩展问题:plugins + skills三级架构 → 支持插件、Skill的灵活扩展,适配不同开发场景。
下文是Claude Code 存储架构的核心逻辑、实现方案的详细拆解。
对于本地化运行的 AI 编程工具而言,数据存储需要兼顾多维度需求:
多项目隔离:开发者通常同时维护多个项目,会话数据若混存会导致溯源困难、管理混乱;
数据安全性:AI 对话过程中的实时交互数据(如代码修改、工具调用记录)若未实时持久化,程序崩溃易造成数据丢失;
可追溯性:复杂的编程对话包含多轮交互和工具调用,需要完整的上下文链路支撑回溯和问题定位;
操作可恢复性:AI 自动修改代码后,若效果不符合预期,需支持快速撤销回滚;
配置灵活性:不同机器、不同项目可能有差异化的权限、插件配置,需兼顾全局统一和局部定制。
针对这些痛点,Claude Code 确立了四大核心设计原则,作为整个存储架构的底层指导。
Claude Code的存储架构围绕以下四大原则展开
1. 按项目隔离:解决多项目数据混存问题
将Session(会话)数据严格按项目路径组织,每个项目的会话数据独立存储,避免不同项目的交互记录相互干扰,同时方便按项目维度管理、清理数据。
2. 实时持久化:解决崩溃丢数据问题
采用JSONL(JSON Lines)格式存储核心会话数据,支持流式追加写入,每条消息生成后立即落地,即使程序崩溃也仅能最大程度保障数据完整性。
3. 可追溯:解决上下文链路断裂问题
通过消息链结构(uuid + parentUuid)串联所有交互记录,支持完整的对话回溯和问题定位。
4. 可恢复:解决操作不可撤销问题
基于file-history-snapshot(文件历史快照)机制,在修改文件前自动备份原始内容,降低误操作风险。
Claude Code的所有本地数据集中存储在用户主目录下,核心分为以下两部分

(1)~/.claude.json 完整示例如下
{
"projects": {
"/Users/xxx/my-project": {
"mcpServers": {
"jarvis-tasks": {
"type": "stdio",
"command": "python",
"args": ["/path/to/run_mcp.py"]
}
}
}
},
"recentPrompts": [
"Fix the bug in auth module",
"Add unit tests"
]
}
(2)claude完整目录结构如下:
~/.claude/
├── settings.json # 全局设置(权限、插件、清理周期)
├── settings.local.json # 本地设置(机器特定,不提交Git)
├── history.jsonl # 命令历史记录
│
├── projects/ # 📁 Session 数据(按项目组织,核心目录)
│ └── -Users-xxx-project/ # 路径编码后的项目目录
│ ├── {session-id}.jsonl # 主会话数据(JSONL格式)
│ └── agent-{agentId}.jsonl # 子代理会话数据
│
├── session-env/ # Session 环境变量
│ └── {session-id}/ # 按Session ID隔离
│
├── skills/ # 📁 用户级 Skills(全局可用)
│ └── mac-mail/
│ └── SKILL.md
│
├── plugins/ # 📁 插件管理
│ ├── config.json # 插件全局配置
│ ├── installed_plugins.json # 已安装插件列表
│ ├── known_marketplaces.json # 市场源配置
│ ├── cache/ # 插件缓存
│ └── marketplaces/
│ └── anthropic-agent-skills/
│ ├── .claude-plugin/
│ │ └── marketplace.json
│ └── skills/
│ ├── pdf/
│ ├── docx/
│ └── frontend-design/
│
├── todos/ # 任务列表存储
│ └── {session-id}-*.json # 关联Session的任务文件
│
├── file-history/ # 文件编辑历史(按内容hash存储)
│ └── {content-hash}/ # 哈希命名的文件备份目录
│
├── shell-snapshots/ # Shell 状态快照
├── plans/ # Plan Mode 计划存储
├── local/ # 本地工具/node_modules
│ └── claude # Claude CLI 可执行文件
│ └── node_modules/ # 本地依赖
│
├── statsig/ # 特性开关缓存
├── telemetry/ # 遥测数据
└── debug/ # 调试日志
为兼顾全局统一配置和局部定制需求,Claude Code设计了三级配置体系,优先级从高到低依次为:项目级配置 > 本地配置 > 全局配置。
┌─────────────────────────────────────────┐
│ 项目级配置 │ 优先级最高
│ 项目/.claude/settings.json │ 项目专属,覆盖其他配置
├─────────────────────────────────────────┤
│ 本地配置 │ 机器特定,不提交版本控制
│ ~/.claude/settings.local.json │ 覆盖全局配置
├─────────────────────────────────────────┤
│ 全局配置 │ 优先级最低
│ ~/.claude/settings.json │ 基础默认配置
└─────────────────────────────────────────┘
各配置文件完整示例如下:
{
"$schema": "https://json.schemastore.org/claude-code-settings.json",
"permissions": {
"allow": ["Read(**)", "Bash(npm:*)"],
"deny": ["Bash(rm -rf:*)"],
"ask": ["Edit", "Write"]
},
"enabledPlugins": {
"document-skills@anthropic-agent-skills": true
},
"cleanupPeriodDays": 30
}
{
"permissions": {
"allow": ["Bash(git:*)", "Bash(docker:*)"]
},
"env": {
"ANTHROPIC_API_KEY": "sk-ant-xxx"
}
}
{
"permissions": {
"allow": ["Bash(pytest:*)"]
}
}
整体的配置合并与权限规则如下:
合并规则:最终配置 = 全局配置 + 本地配置覆盖 + 项目配置覆盖(后加载的配置覆盖先加载的同字段);
权限优先级:deny > ask > allow > 默认行为(严格遵循,保障操作安全)。
Session是Claude Code最核心的数据,存储了所有对话历史和上下文,其设计直接决定了数据可靠性和可追溯性。
(1)存储思路:按项目路径编码隔离
存储路径:~/.claude/projects/ + 路径编码后的项目目录;
路径编码规则:将 /、空格、~ 替换为 -;
示例
/Users/bill/My Project → -Users-bill-My-Project
(2)存储格式:JSONL的优势与示例
Session数据采用JSONL(JSON Lines)格式,而非普通JSON,核心原因如下:

JSONL格式完整示例
{"type":"user","message":{"role":"user","content":"Hello"},"timestamp":"2026-01-05T10:00:00Z"}
{"type":"assistant","message":{"role":"assistant","content":[{"type":"text","text":"Hi!"}]}}
{"type":"user","message":{"role":"user","content":"Help me fix this bug"}}
使用JSONL,让每个消息独立一行的核心价值在于:
(3)Session JSONL数据结构(完整消息类型与示例)
Session文件包含多种消息类型,每种类型承担特定职责:

用户消息完整示例如下
{
"type": "user",
"uuid": "7d90e1c9-e727-4291-8eb9-0e7b844c4348",
"parentUuid": null,
"sessionId": "e5d52290-e2c1-41d6-8e97-371401502fdf",
"timestamp": "2026-01-05T10:00:00.000Z",
"message": {
"role": "user",
"content": "分析一下这个项目的架构"
},
"cwd": "/Users/xxx/project",
"gitBranch": "main",
"version": "2.0.76"
}
助手消息完整示例(含工具调用与token使用)如下
{
"type": "assistant",
"uuid": "e684816e-f476-424d-92e3-1fe404f13212",
"parentUuid": "7d90e1c9-e727-4291-8eb9-0e7b844c4348",
"message": {
"role": "assistant",
"model": "claude-opus-4-5-20251101",
"content": [
{
"type": "thinking",
"thinking": "用户想了解项目架构,我需要先查看目录结构..."
},
{
"type": "text",
"text": "让我先看一下项目结构。"
},
{
"type": "tool_use",
"id": "toolu_01ABC",
"name": "Bash",
"input": {"command": "ls -la"}
}
],
"usage": {
"input_tokens": 1500,
"output_tokens": 200,
"cache_read_input_tokens": 50000
}
}
}
消息通过 uuid(自身唯一标识)和 parentUuid(父消息标识)形成完整链式结构,支持全链路回溯:
file-history-snapshot (messageId: A)
↓
user (uuid: A, parentUuid: null) ← 用户提问(链路起点)
↓
assistant (uuid: B, parentUuid: A) ← AI思考 + 文本回复
↓
assistant (uuid: C, parentUuid: B) ← AI工具调用(如Bash命令)
↓
user (uuid: D, parentUuid: C) ← 工具执行结果(如Bash输出)
↓
assistant (uuid: E, parentUuid: D) ← AI基于工具结果继续回复
↓
summary (leafUuid: E) ← 会话摘要(关联链路终点)
这是Claude Code保障代码修改可恢复的关键设计,核心逻辑是修改前备份原始内容,撤销时恢复,所有细节如下:
(1)核心定义:什么是Checkpoint,作用如何?
每当用户发送新消息时,Claude Code会自动创建 file-history-snapshot,专门记录「即将被修改的文件的原始内容」,作为撤销操作的数据源:
用户提问 → 创建snapshot(备份原始内容) → Claude修改文件 → 用户不满意 → Esc+Esc撤销
↑ ↓
存储原始内容 ←─────────────────────────────── 从snapshot恢复原始内容
(2)完整数据结构示例
{
"type": "file-history-snapshot",
"messageId": "7d90e1c9-e727-4291-8eb9-0e7b844c4348",
"snapshot": {
"messageId": "7d90e1c9-e727-4291-8eb9-0e7b844c4348",
"trackedFileBackups": {
"/path/to/file1.py": "
原始文件内容\ndef hello():\n print('old')",
"/path/to/file2.js": "// 原始内容..."
},
"timestamp": "2026-01-05T10:00:00.000Z"
},
"isSnapshotUpdate": false
}
(3)关键步骤:备份修改前的内容
trackedFileBackups 存储的是文件修改前的原始内容,而非修改后的内容。这是撤销功能的核心建设思路:
┌──────────────────┐
│ 修改前 app.py │
│ print("old") │───────→ 备份到 snapshot 的 trackedFileBackups
└──────────────────┘
↓
┌──────────────────┐
│ Claude 修改后 │
│ print("new") │───────→ 写入磁盘(覆盖原文件)
└──────────────────┘
↓
┌──────────────────┐
│ 用户执行撤销 │
│ 按下 Esc + Esc │───────→ 从 snapshot 恢复 "old" 内容到磁盘
└──────────────────┘
(4)完整工作流程
(5)存储位置与保留策略
(6)相关命令
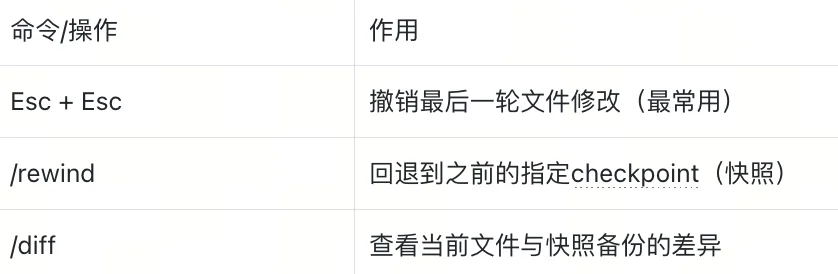
~/.claude/plugins/
├── config.json
插件全局配置(如启用/禁用规则)
├── installed_plugins.json
已安装插件列表(含版本、状态)
├── known_marketplaces.json
插件市场源配置(如Anthropic官方市场)
├── cache/
插件下载缓存(避免重复下载)
└── marketplaces/
市场源存储目录
└── anthropic-agent-skills/
官方插件市场
├── .claude-plugin/
│ └── marketplace.json
市场元信息
└── skills/
市场提供的Skills
├── pdf/
PDF处理相关Skill
├── docx/
Word文档处理相关Skill
└── frontend-design/
前端设计相关Skill
Skills 按使用范围做分层存储,适配不同场景的功能定制,层级关系如下:


陈彪
Zilliz Senior Staff Software Engineer
文章来自于“Zilliz”,作者 “陈彪”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
