# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Agent很好,但要做好工具调用能才能跑得通。
但让Agent做好工具调用,却并不简单。
用MCP吧,模型很难像人一样精准判断出什么场合该用什么工具,要怎么用;而且用MCP时,模型要把所有工具定义加载到上下文窗口。仅仅一个GitHub(26k)的MCP,就能占模型四分之一的上下文。
为了解决这个问题,Anthropic 推出了 Skills,相比MCP,Skills的上下文更精简、标准化程度更高、可控性更强。
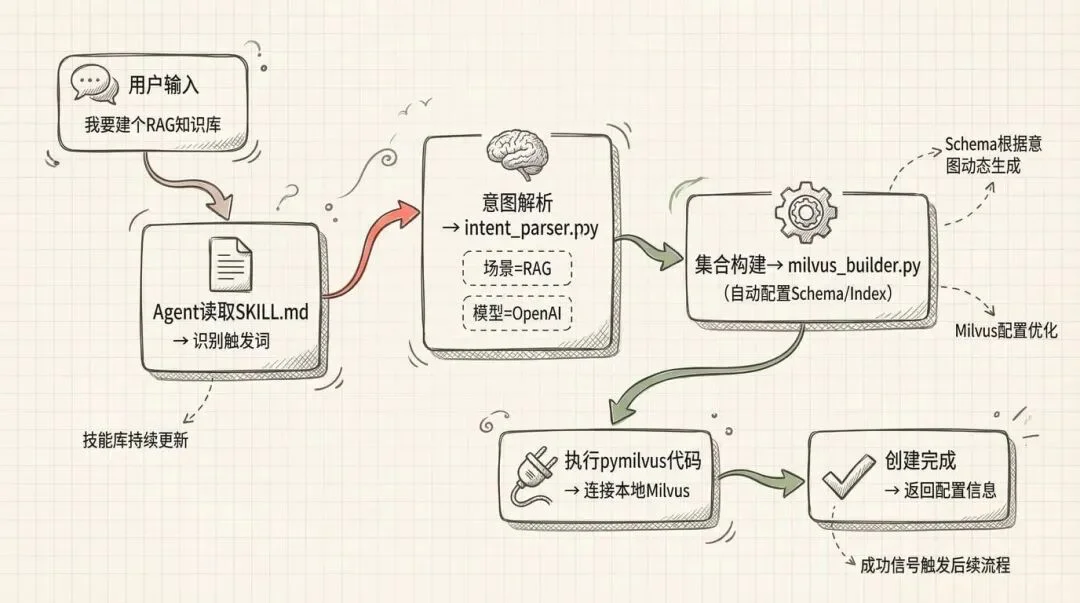
那么到底怎么用好skills?今天我们将示范如何在claude-code中,创建一个milvus skills,进行知识库搭建。
Skills其实是2025年12月,Anthropic给Claude Code开放的一个类似AI工具接口标准的东西。
目前,Claude Code,Codex、GitHub、VS Code、Cursor、Codebuddy各种主流AI编程工具都对这个标准做了兼容。
它可以相关工具的专业知识、做事方法、工具脚本、参考资料打包成一个文件夹,大模型阅读后,就知道完成某项任务需要哪些工具,如何去完成。
其标准目录结构如下:
skill-name/
├── SKILL.md # 必需:Skill 指令和元数据
├── scripts/ # 可选:辅助脚本
├── templates/ # 可选:文档模板
└── resources/ # 可选:参考文件
Agent 的执行说明书,包含元数据(name/description/触发词)、执行流程、默认配置。你需要在这里写清楚:
预写好的脚本(Python/Shell/Node.js), Agent 直接调用,不用每次生成代码。如 create_collection.py、check_env.py。
可复用的模板文件,Agent 基于模板生成个性化内容。如报告模板、配置模板。
Agent 执行时参考的知识文档,如 API 文档、技术规范、最佳实践指南。
整体结构的运行,我们可以想象成在模拟给新同事交接工作:是工作手册,scripts/是常用工具,templates/是标准模板,resources/是参考文档,Agent 拿到材料就能开工。
创建一个 Milvus Skills,通过自然语言描述自动创建 RAG 系统或 Milvus Collection,无需理解 schema、index 等技术概念。
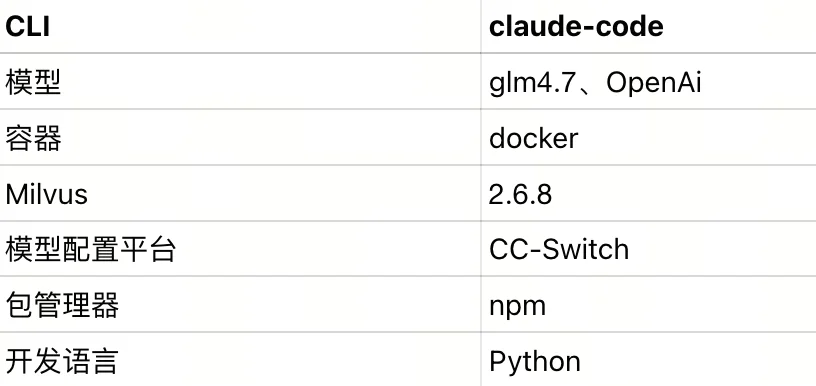
npm install -g @anthropic-ai/claude-code
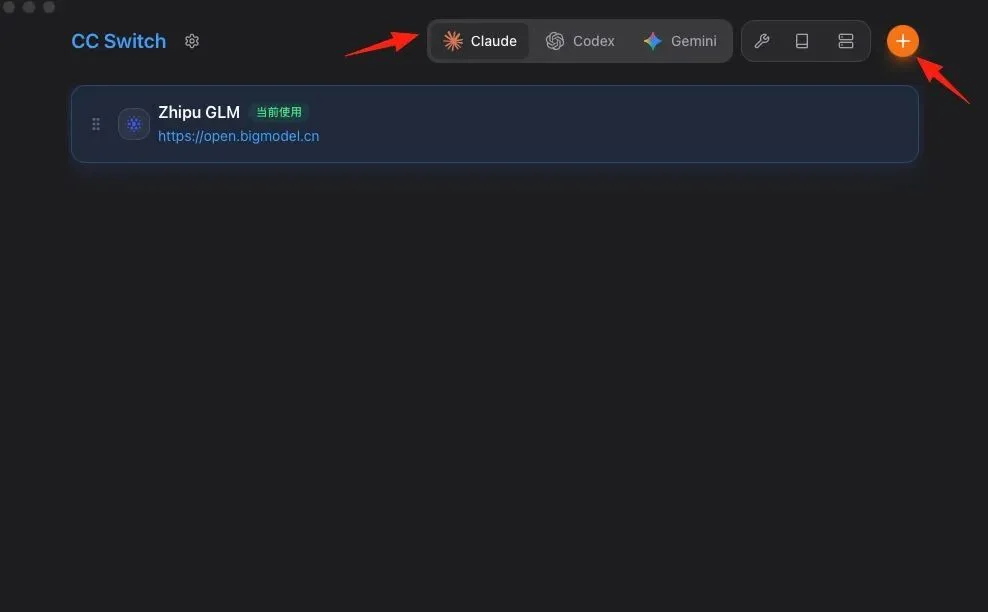
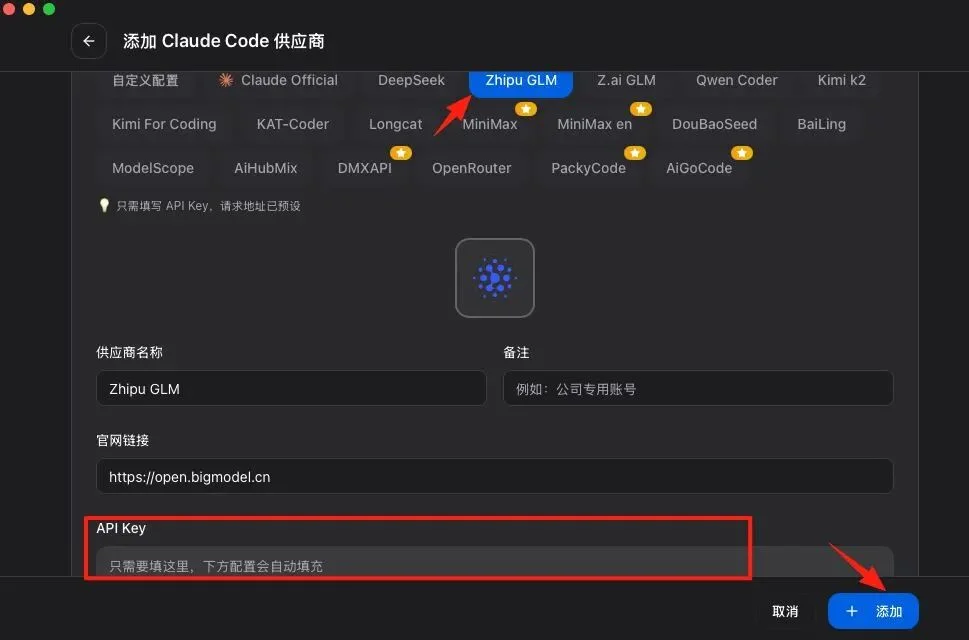
说明:CC-Switch 是一个模型切换工具,让你在本地跑 AI 模型时能方便切换不同的 API。
地址:https://github.com/farion1231/cc-switch
# 下载docker-compose.yml
wget https://github.com/milvus-io/milvus/releases/download/v2.6.8/milvus-standalone-docker-compose.yml -O docker-compose.yml
# 启动Milvus(检查端口映射:19530:19530)
docker-compose up -d
# 验证服务启动
docker ps | grep milvus
# 应该看到3个容器:milvus-standalone, milvus-etcd, milvus-minio

# 在~/.bashrc或~/.zshrc中添加
OPENAI_API_KEY=your_openai_api_key_here
cd ~/.claude/skills/
mkdir -p milvus-skills/example milvus-skills/scripts
说明:是 Agent 的执行说明书
name: milvus-collection-builder
description: 用自然语言创建Milvus集合,支持RAG和文本搜索场景
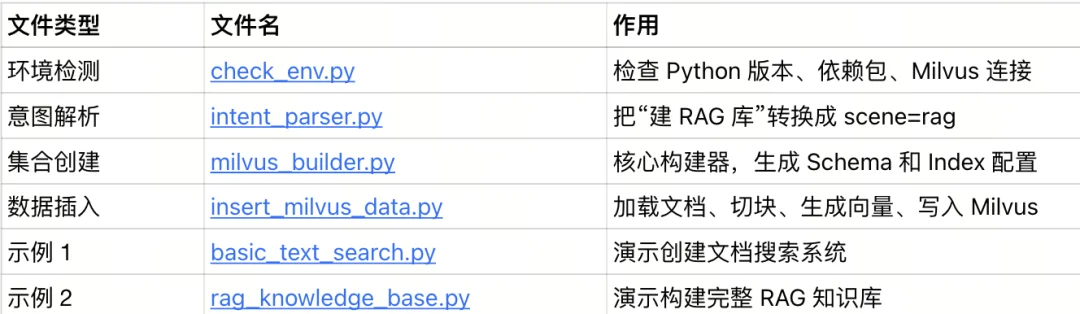
这些脚本展示了如何把 Milvus 技能变成真正能用的文档搜索和智能问答系统。
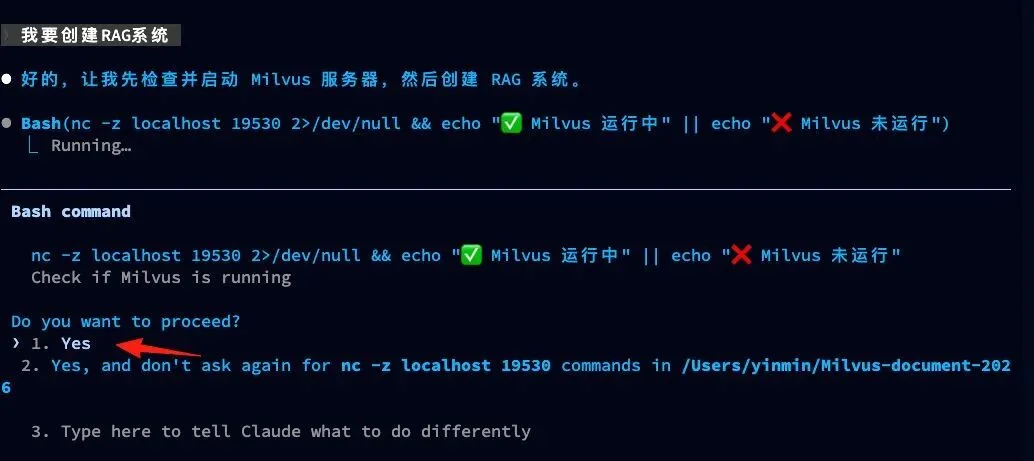
我要创建RAG系统

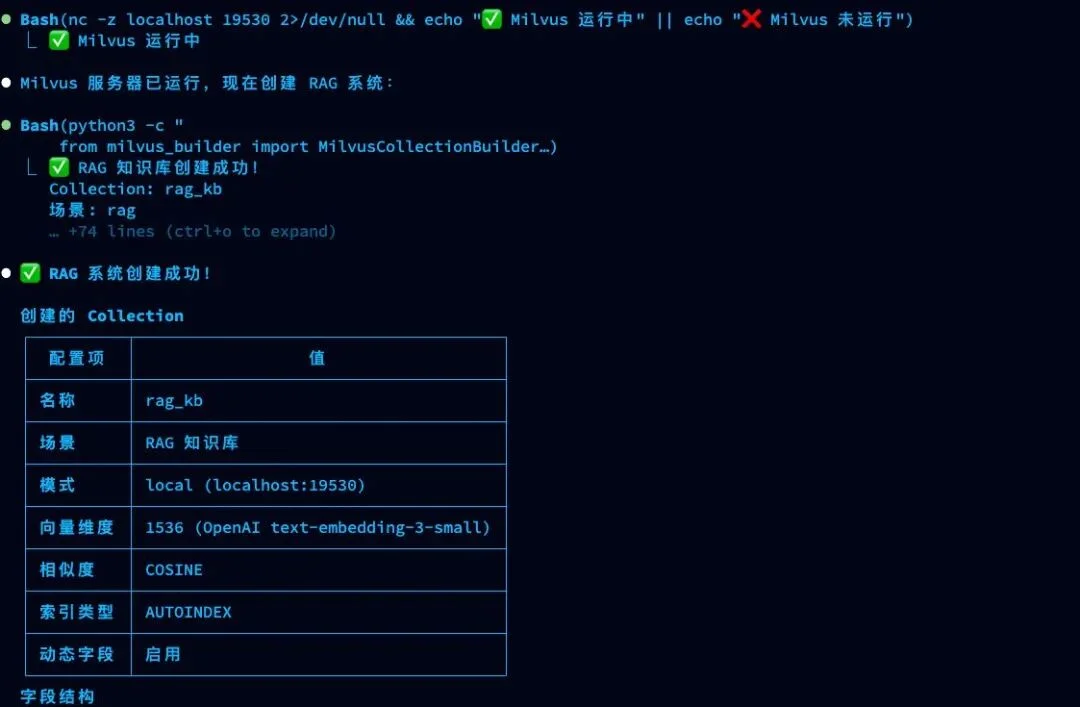

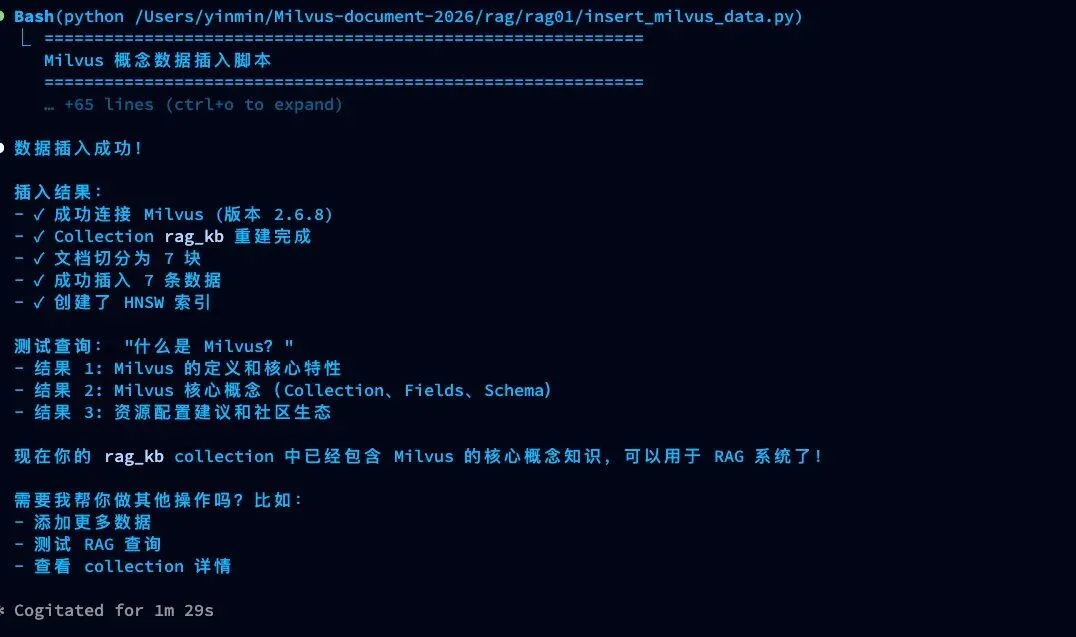

这个 Milvus-Skill 是个起点,展示了用 Skills 简化 RAG 构建的思路。
实际 RAG 系统还有更多场景可以封装:文档预处理、分块策略优化、混合检索配置、重排序调优、结果评估等,每个环节都能做成独立 Skill 串联使用。
但 Skills 的价值在于降低入门门槛:新手可以 10 分钟跑起来原型,不用被配置参数劝退;老手可以把团队的最佳实践封装成 Skills,避免重复造轮子。
如果你有常用的技术栈配置流程、重复性开发任务,都可以试着做成 Skills。不是万能,但确实能省不少时间。
如果你有常用的技术栈配置流程、重复性开发任务,都可以试着做成 Skills。不是万能,但确实能省不少时间。
完整代码:https://github.com/yinmin2020/open-milvus-skills
推荐 skills 市场:https://skillsmp.com/
一个彩蛋:milvus、zilliz cloud官方版skills即将发布,对它有什么期待,希望它能够解决你的什么问题,欢迎评论区留言

Zilliz黄金写手:尹珉
文章来自于“Zilliz”,作者 “尹珉”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
