# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI 智能体是人工智能领域的重要研究方向之一。近期,字节跳动的李航博士在我国计算机科学领域顶级期刊 Journal of Computer Science and Technology(JCST)上发表了一篇题为《General Framework of AI Agents》的观点论文(将收录于 JCST 创刊 40 周年专辑),提出了一个涵盖软件智能体和硬件智能体的通用框架。其中,软件智能体是指可运行于 PC 和手机等设备上的智能体,而硬件智能体则指物理世界中的机器人。
该框架的主要特点是:智能体以完成任务为目标,以文本或多模态数据作为输入和输出,依赖大语言模型(LLM)进行推理,通过强化学习进行构建,并能够使用各类工具与长期记忆系统。
李航博士认为,目前业界常见的智能体,以及字节跳动 Seed 团队最近研发的智能体,均可纳入这一通用框架。此外,文章还比较了智能体通用框架与人脑信息处理机制之间的关联,分析了智能体技术的主要特点,并探讨了该领域未来研究的重要方向。
该文章主要观点如下:
人工智能智能体(AI 智能体)通常拥有以下特点。
随着人工智能技术的发展,各种 AI 智能体的信息处理框架的基本形态已经逐渐形成。该文将已有系统的框架进行概括整理,提出一个新的通用框架(图 1)。
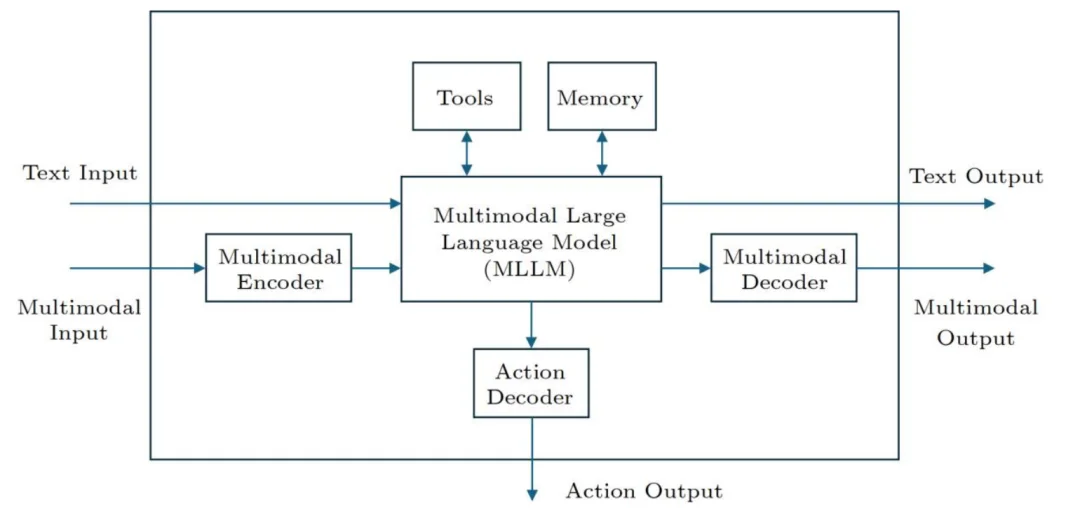
图 1. AI 智能体的通用框架
智能体由多模态大语言模型(MLLM, 其中 LLM 为核心部分)、工具、记忆(包括长期记忆和工作记忆)、多模态编码器、多模态解码器以及动作解码器组成。
智能体可以接收文本输入并生成文本输出,其中文本既可以是自然语言,也可以是形式化语言;LLM 根据文本输入生成文本输出,并且还可能生成表示推理过程的文本,即思维链(chain of thought)。在这一过程中,智能体可以调用不同的工具,并从记忆中读取或向记忆中写入信息和知识。
智能体还可以接收多模态输入并生成多模态输出,包括图像、音频和视频;通过多模态编码器,智能体生成多模态的中间表示,将其输入到 MLLM 中,再生成新的多模态中间表示,最终通过多模态解码器生成多模态输出;在此过程中也可以使用工具。
硬件智能体(即机器人)同样可以接收文本和多模态输入,并输出物理动作和多模态结果;物理动作可以表现为机器人运动和操作的轨迹,这些动作输出后由机器人的硬件和控制系统实际执行。
在硬件智能体中,一般需要两类模型:MLLM 本身;以及多模态 - 语言 - 动作模型(MLAM),即在 MLLM 基础上增强了动作解码器的模型。MLLM 主要用于高层任务规划、推理,以及与环境的交互,而 MLAM 则用于低层动作规划(即生成用于执行计划的运动和操作轨迹)。
MLLM 和多模态编码器主要通过预训练获得;MLLM、多模态编码器、多模态解码器以及动作解码器在后训练阶段进一步微调,一般通过模仿学习和强化学习进行。
该文提出的框架具有两层结构:底层由 MLLM、编码器、解码器、工具和记忆等组件构成;顶层则是整体的信息处理机制。此外,这些组件同时处理符号表征和神经表征。
业界知名的智能体或智能体框架,如 AutoGPT、LangChain、ReAct、Reflexion、LATS、ToolFormer、Voyager、OS-Copilot、Gemini Robotics 1.5,以及字节跳动 Seed 近期研发的智能体 AGILE、Delta Prover、Robix+GR-3 和 M3 Agent,其信息处理框架均可视为图 1 所示通用框架的特例。
这些智能体在输入和输出形式上各不相同,并且可能使用工具、记忆,或两者兼而有之,但它们的核心架构与工作流程是一致的。未来,随着智能体朝着更高通用性方向发展,其底层框架也将逐渐趋于通用化。
人的思维,即大脑的信息处理,大多是在下意识中进行的,有诸多个相对独立的子系统并行处理信息。脑科学中的全局工作空间(global workspace)假说认为,意识是实现全脑信息同步的机制,其信息处理表现出串行特征。下意识 - 意识的这种并行 - 串行协同机制,使大脑在保持高效处理的同时,也能有效地应对复杂的环境。
具身认知论(embodied cognition)认为,在人的思维过程中,意识中的处理产生的是表象(image),心智计算论(computational theory of mind)认为意识中的处理产生的是心智语言(mental language, mentalese)。目前没有定论,该文借鉴两者的观点,假设思维中既能产生心智语言,也能产生表象。图 2 描绘了大脑的信息处理机制。
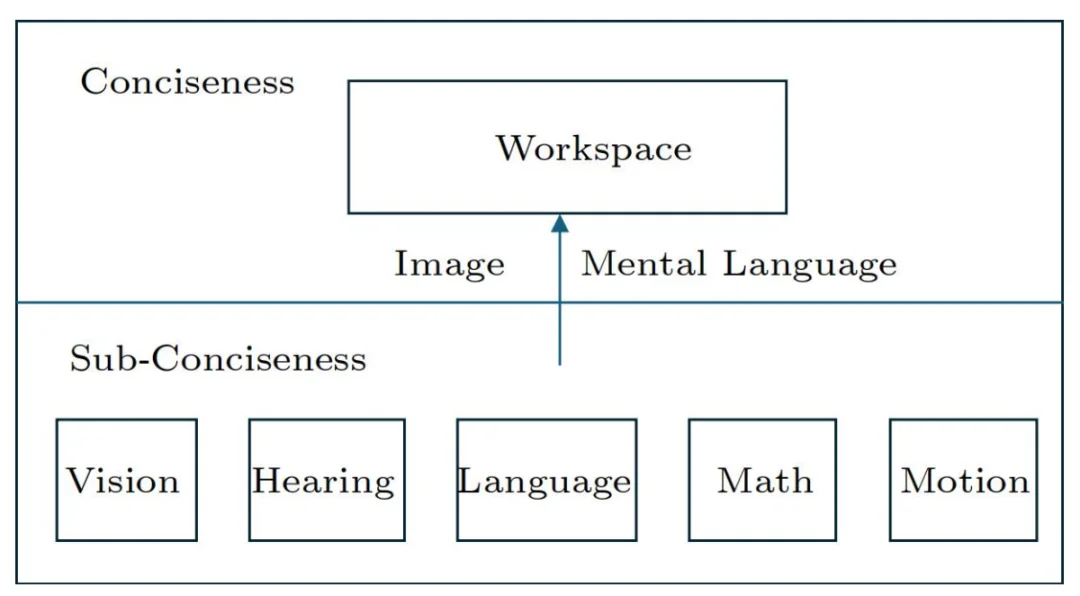
图 2 人脑大脑的信息处理机制
可以看出,智能体的框架与人脑大脑的信息处理机制在功能层面上有对应关系,都具有两层的信息处理结构(当然两者在算法和实现层面上完全不同)。上层是串行处理,下层是并行处理。两层之间的信息交流通过神经表征和符号表征进行。
图 1 所示的智能体可以对视觉和听觉信息进行处理,生成语言,开展推理,规划动作,并且在其中进行有机的协调;这方面与人有相似之处。当然也有一些不同点,例如,计算机可以以文本的形式,对语言进行输入和输出,而人则通过视觉、听觉、触觉等多模态形式对语言进行输入和输出。
在人脑与通用智能体框架之间,在功能层面存在若干相似之处。首先,两者均呈现双层结构:底层由多个处理模块构成,上层则负责协调与同步。其次,两者在处理信息时,均通过这些模块以符号表征与神经表征两种形式进行。或者说,人脑与 AI 智能体均采用了神经符号处理。
软件智能体和硬件智能体
软件智能体与硬件智能体(机器人)本质上具有相似性,但也存在差异。这主要是因为它们运行的环境不同:软件智能体活动于数字世界,而硬件智能体则作用于物理世界。尽管两者所处的环境有所区别,但它们在信息处理框架上是一致的。二者主要的区别在于其输入与输出的形式不同。
软件智能体通常以文本及多模态(视觉与听觉)数据作为输入,输出则多为符号形式,如文本、代码或其他结构化表达。相比之下,机器人这样的硬件智能体需要处理更多样的多模态输入。例如,它们可以整合触觉数据。更重要的是,硬件智能体的输出不限于文本和多模态,还包括物理动作。
具身认知理论认为,人类智能是通过身体与环境的互动发展而来的,这一原理也可以拓展至机器智能。硬件智能体可以借助更丰富的输入与动作空间,从而发展出更通用、更具适应性的智能。
智能体中的大语言模型
大语言模型 LLM 承担着智能体「思考」的功能,是智能体的核心。智能体的智能水平主要依赖于 LLM 的能力。
经过强化学习微调的 LLM 本身就是一种强大的智能体,通过生成语言,完成与人交互的任务。其中交互可以是单轮的,也可以是多轮的;交互的过程中可能使用思维链进行推理;生成的语言可以是自然语言,也可以是形式语言,例如代码。LLM 的语言生成基于上下文,在多轮交互时就是目前为止的交互记录,存储在 LLM 的上下文窗口或短期记忆中。
但是 LLM 也有不足:只有短期记忆,无法无限制地存储和使用信息和知识。 LLM 也不具备搜索、算术计算、代码执行等能力。再有,LLM 也不能直接处理多模态数据。
智能体在 LLM 的基础上,增加长期记忆、各种工具、多模态处理模块,组成两层结构,并通过强化学习再训练,使它变得更加强大。
推理
推理是一个具有多重含义的概念,存在若干种类型。深度学习中的推理通常指用训练好的模型对未知数据的预测,当模型是生成模型时是指对新数据的生成。数学领域的逻辑推理(包括命题逻辑、一阶谓词逻辑)是整个数学的基础。机器学习领域的贝叶斯推断和因果推断各自拥有严格和完备的数学体系。类推推理(analogical reasoning)是指针对两个相似的事物,将其中一个事物的属性、类别、功能推广到另一个事物上的推理。一般认为机器学习中神经网络的分类、语言模型的生成等实现的是类推推理。
人的推理采用哪种类型?目前科学并没有定论。可以看出是多面的。我们在做数学定理证明的时候,推导过程中使用的是逻辑推理。福尔摩斯通过收集的证据判断犯人是谁的可能性最大,这个过程可以用贝叶斯推断来刻画。但人在日常思考过程中更多使用的是类推推理,在人的理解、决策、学习中起着重要作用。例如,「时间」是一个抽象的概念,我们通常用从左到右的一条带箭头直线,一个实在的概念,来理解它;实际是一个比喻。
LLM 的推理要分三个不同层次来理解。
神经符号处理
神经符号处理是指符号处理与神经处理(深度学习)的结合。智能体应具备神经符号处理能力,这也是智能体与多模态大语言模型(MLLM/LLM)之间的主要区别。
尽管 LLM 在一定程度上能进行符号处理,但在需要严谨性的任务中,它们并不完全可靠。相比之下,使用工具的初衷正是为了进行符号处理。例如,逻辑推理和数学计算本质属于符号处理,应当通过相应的工具来实现,而非仅仅依赖于 LLM。这是因为 LLM 从机制上无法实现严谨的逻辑推理和数学计算。
此外,长期记忆中的世界知识本质上是多模态的。这类知识中的一部分可以更自然、更合理地以符号形式呈现。科学证据表明,人类知识的获取和记忆是以实体和概念为中心的,这些实体和概念在脑海中形成了一个庞大的语义网络。同样,智能体的记忆中也可以维护这样一种语义网络,该网络可以通过符号处理从 LLM 的输出中构建。
智能体对环境的理解(例如对语言和视觉输入的理解)不应局限于表象形式,而必须深入到语义层面,即实现锚定(grounding)。对环境的准确理解能使智能体更有效地完成任务。锚定的本质在于将输入信息与已有知识建立关联。以「神经 - 符号」混合形式存储在长期记忆中的知识,能够有效地促进这一锚定过程。
智能体和机器人的发展仍处于早期阶段,仍然有许多科学和技术问题有待探索和攻克。除了基本的模型架构、训练方法以外,以下几个重要的研究课题也需要广泛的探索和深入的研究。
扩大数据规模
缺乏训练数据应该是目前智能体开发中遇到的最大瓶颈。如何在智能体的通用或垂直领域中收集足够大规模的数据,用于模型训练,是亟待解决,也是大家正在努力解决的问题。例如,机器人的开发需要有足够量的机器人硬件系统帮助进行数据采集。
一个解决方案是在实际场景当中,先有一个还不错的智能体进行运行,进行数据采集,在这个过程中,得到大量的真实数据,构建数据模型训练的闭环。另一个解决方案是通过自动的手段,包括生成式 AI 技术,自动合成数据用于模型训练。这些方法都需要今后充分的尝试和探索。
自主和持续学习
目前智能体一般是事先训练好,然后在具体场景中使用。许多学者指出,未来的智能体应该能够在使用过程中,也就是与环境的互动过程中,进行自主学习(autonomous learning)和持续学习(continual learning)。
即使是现在的智能体框架,也能更主动地学习。例如,智能体在使用过程中进行在线强化学习。通过轨迹采样,得到环境的奖励,进行利用和探索的平衡,学习到更好的策略。目前在线强化学习由于安全等原因并没有实际使用起来。
主动和持续学习意味着智能体在与环境的互动中,不断构建或更新对环境的感知和认知,持续掌握或提高完成任务的规划和控制能力,提升自身的智能水平。
安全性和可控性
智能体的安全性和可控性永远是最重要的问题之一。高自主性的智能体可能带来的风险更大,如何将可能的风险控制在最小范围是持续需要解决的问题。
如果是使用强化学习训练智能体,这就关系到如何定义强化学习的奖励函数。如果奖励函数表示完成任务的好坏,同时与人类价值观对齐;这时风险虽然存在,但相对可控。
如果奖励函数超出完成任务的范围,那就有可能给人类带来极大的风险。我们需要设置研究和开发的红线。例如,假设以智能体在环境中是否能生存作为奖励函数,那么训练出来的智能体,就有可能变得自私,容易会去作恶。智能体在与环境交互中进行学习,环境中总是存在使智能体「学坏」的信息和知识,这一点人也是一样的,其实并不可怕。关键是智能体是否能排除干扰,学习到「好的」技能和行为。这里,奖励函数起着决定性的作用。
文章来自于“机器之心”,作者 “机器之心”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
