# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI,是色盲吗?
这个问题听起来很蠢。
毕竟现在的AI能识别人脸、读懂图片、生成图像,甚至可以按RGB色值给你改颜色。
怎么可能是色盲,看不见颜色呢?
但最近发生的一件事,让我开始开始觉得,这事不对。。。
昨天正好在办公室和同事闲聊,聊到了颜色,我们刚来的实习生小朋友说,说他是红绿色盲,然后我们的话题,就不知道怎么就聊到了色盲测试。
在现场找了几张图一起测试,
就那种一堆小点点里藏数字的图。

能看到的兄弟们可以把数字回复在公屏上。
我们那个实习生小朋友,居然真的有看不见的。
当时大家还挺欢乐的,说,要不然,发给AI看看。
然后我们就发了,本来觉得,这么明显的数字,对现在这种级别的AI来说,肯定就是送分题。
毕竟都一群AI都有自己的社区,都可以开AI宗教招收信徒了,一个色盲测试那不是小儿科吗。
没想到。

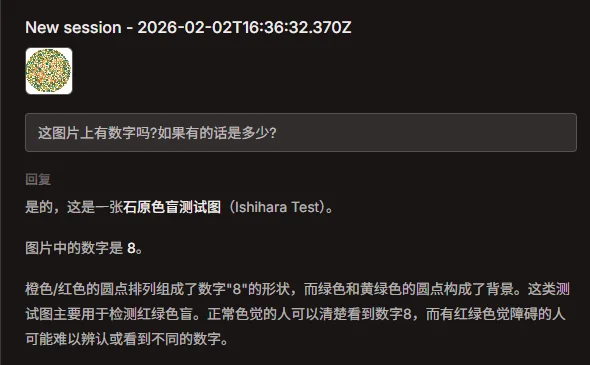
现在最能打的多模态模型Gemini 3 Pro,居然给我回了个74???
我当时我都以为我色盲了。
我揉了揉眼睛,又看了好几遍。
不对啊,这图里的,绝壁是45。。。
我反手又试了一下Claude Opus 4.5。
结果,Claude给我回了个,8???
三个国产大模型,更是也都败下阵来。
而且有两个,答案一模一样,也是74。

唯一一个答对的,是GPT 5.2 Thinking,花了5分钟世界,我看了一下思维链,发现这玩意是纯纯用代码作弊的。。。
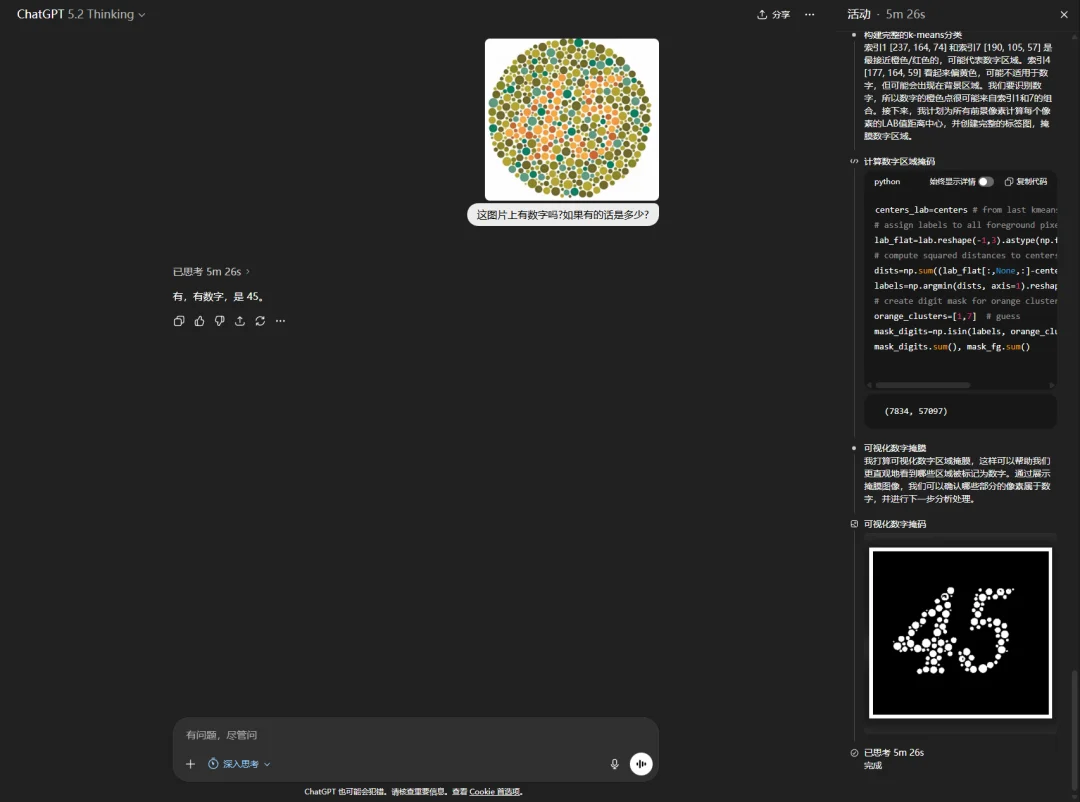
硬生生的做了可视化数字掩膜。
我都懵了,这真的是一个非常无意中的发现。
人类色盲看不出来,我能理解,这是生物学的事。
就像下图,同一把彩虹伞、同一个红绿灯,正常人眼里色彩斑斓。
但在色盲眼里却像开了滤镜,根本分不清。

可AI看不出来,我就很难解释。
它又没有视网膜,也没有什么缺陷,为什么会在这种题上翻车?
难道是因为分不清颜色?
我又很智障地去问Gemini 3 pro这张图是什么颜色。
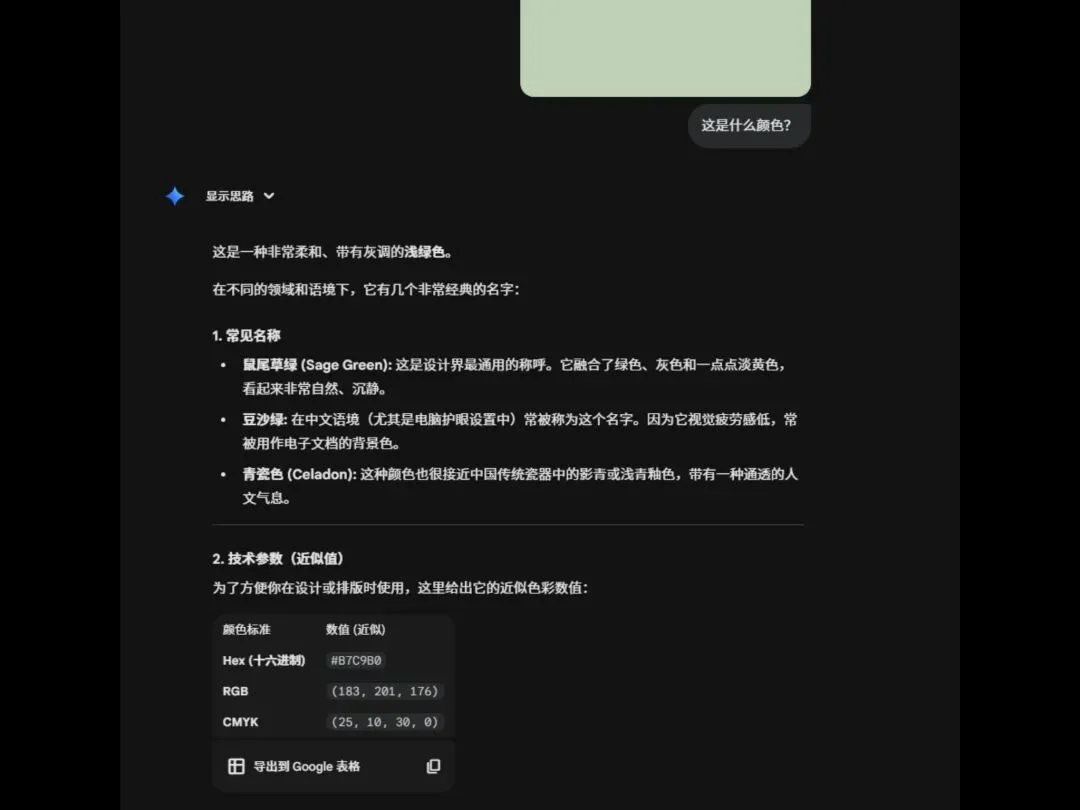
结果,这大哥它不仅能回答我的问题。
也能说很具体,鼠尾草绿、豆沙绿、青瓷色。
甚至特么的RGB和CMYK都给我写出来了。
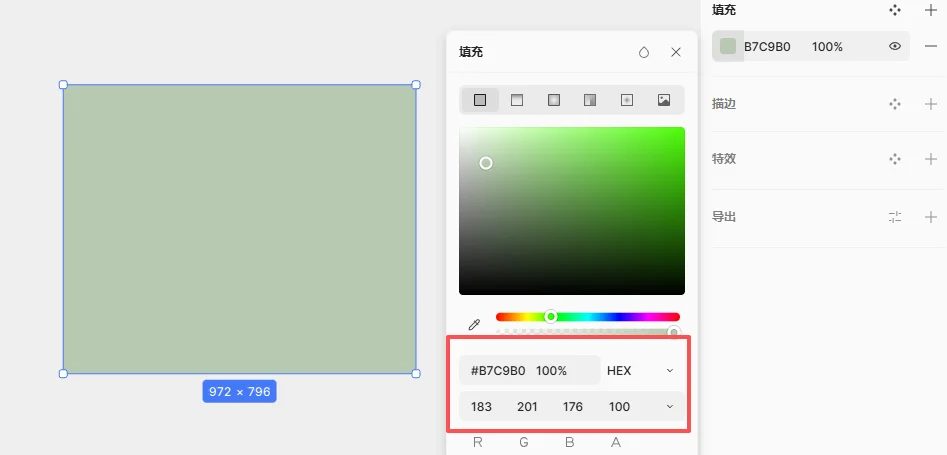
我去一个软件里试了下,尼玛,色号分毫不差啊。。。
所以问题不在颜色本身。
分辨红绿蓝,甚至区分细微的色差,对AI来说都不难。
难的是其他事。
我当时,陷入了深深的思考。
那一瞬间,Clawdot和vibe coding都不香了,就想搞清楚这到底是为什么。
我花了将近一天的时间做DeepResearch、翻论文。
翻了很多东西我都感觉不是很相关,甚至感觉都有点牵强。
但就在我想放弃的时候,晚上,我查到了一篇,那一瞬间我感觉柳暗花明又一村了。
我也好像明白,AI为什么做不出来色盲测试题了。
论文名字还挺好玩。

叫《Pixels,Patterns,but No Poetry:To See The World like Humans》。
翻译过来是《像素、模式,但缺少诗意:像人类一样看世界》。
名字看着虽然跟色盲没啥关系,但是里面的结论和实验,非常的相关。
先说结论:
现在的AI,根本就不是像我们人类一样在“看”世界。
它只是,在计算世界。
它能处理像素,能识别局部模式,但它无法理解这些像素和模式组合在一起后,涌现出的那个整体的、抽象的、富有美感和意义的东西,也就是论文标题里的“诗意”(Poetry)。
听着好像有点难理解,我觉个例子你就懂了。
先看这张图,别急着往下翻。
这是一张图里面的一个我截出来的局部,现在,请你告诉我,觉得通过这张图来分析,它原来的完整的图是什么?

我觉得一个脑子正常的人,看到这个问题和这张图,他都会揍我,都会骂我有病。
说真的,那个人但凡多看我一眼都算我输。
那我们,现在再把画面推远一点,给你多看点。
你可能还是会懵逼,这尼玛是个啥?但是,又模模糊糊的看到了一些家具的影子。

通过这张图,你还是不太可能猜出,真正的图是什么样子的。
那现在,我们把真正的全图放出来。
补上它的全局再看看。
刚才我截图的局部,为了防止大家找不到这个地方,我还贴心的画了一个大箭头= =

大家是不是第一眼甚至都没找到那玩意在哪。
这所谓的不可名状的白色线条,其实只是最右侧柜子上的一道高光。
你只看局部,又怎么可能真正的,看清全局。
就像,断章取义,出自:不要断章取义。
而这,就是AI现在的弊端。
我们再回头看那张色盲测试图。

对我们人类来说,我们看到的,直接就是全局,不是局部,更不是一堆棕色和绿色的圆点,我们的大脑瞬间就将那些颜色相近的棕色点组织成了一个有意义的整体,也就是数字“45”。
而剩下的绿色点,则自动被我们的大脑识别为背景噪音。
这是因为,我们人类看图,从来第都是自上而下。
认知心理学里一个非常重要的流派,叫格式塔心理学,也是现代人机交互学科的奠基理论之一,它的核心观点也就一句话:
整体大于部分之和。
一堆零碎的东西,只要有点规律,比如离得近、颜色像、走向一致,我们就会不讲道理地把它们当成一个整体来看。
比如你看下面这张图,你看到了什么?

你在认真看了两眼之后,你大概率不会说,我看到了一堆不规则的黑色墨迹。
而是会说:我好像看到了一只狗,如果你对狗的品种有一些了解的话,你可能还会说,我看到了一只大麦町犬。
这只狗的形象,其实并不存在于任何一个单独的墨迹里。
它是所有墨迹组合在一起后,在你大脑里“涌现”出来的一个整体概念。
你的大脑自动忽略了那些不重要的斑点,脑补了缺失的轮廓,最终看到了那只探头探脑的大麦町犬。
这个脑补和看整体的能力,就是格式塔。
这是我们人类视觉系统与生俱来的、底层的、几乎是本能的能力。
但AI不是这样的。
论文为了验证这件事,做了一个测试,叫图灵视力测试(TET)。
就像当年图灵测试是为了验证机器能不能像人一样思考,这个图灵视力测试,是为了验证机器能不能像人一样感知视觉。
里面有四个任务,分别是隐藏文本、3D验证码、汉字组成。
以及我们今天文章的主角,色盲测试。

他们参考了石原色盲测试图的形式,就是文章开头那一堆彩色小点里藏数字的图。
并且,还增加了难度。
用一些颜色非常接近的点来进行干扰,让模型更难从整体形状里看出数字。

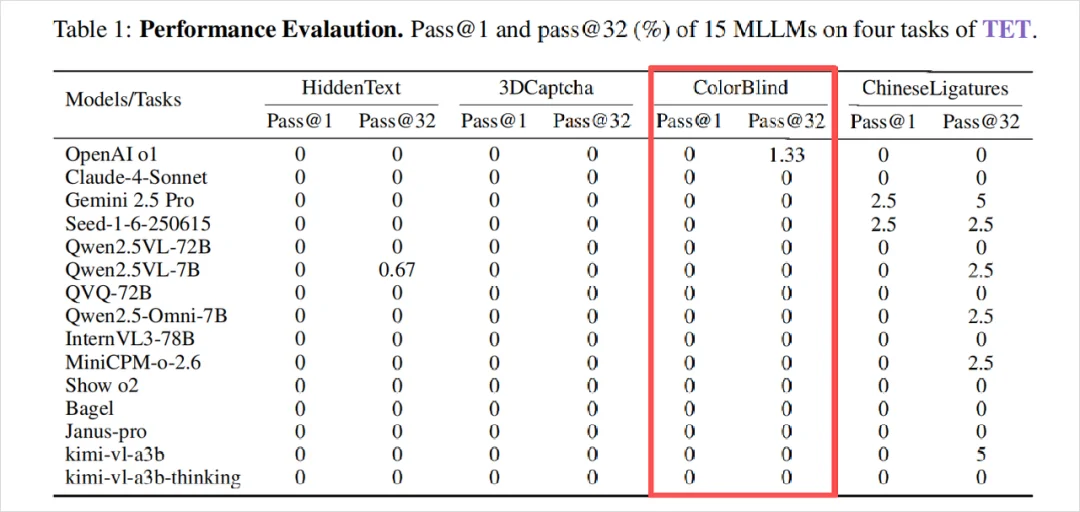
用这些图去测当时最顶级的15个多模态大模型。
结果可以从这张表格看出来,密密麻麻的0。
几乎是全军覆没。
我猜他们这帮人也很惊讶。
模型怎么就识别不了颜色中的数字呢?
为了找到答案,他们首先想搞清楚:AI到底在看什么?
他们用了一个技术,叫Grad-CAM(梯度加权类激活映射)。
这个东西光读名字就很拗口,我用大白话给大家解释下。
可以把它理解为给AI的思考过程拍个X光,让你能看见它的眼睛到底在盯哪里,注意力落在什么地方。
如下图,颜色越亮,发黄光的地方,是模型最在意的地方,就是对目前答案贡献最大的区域。

我知道这张图看着还是有点难理解,手动又用红色单独处理了一下。
红色是AI盯着看的区域,就是注意力落点的位置。

通过这个技术,就能验证,AI到底是在看数字的轮廓,还是被周围的噪点给带偏了。
现在,我们把AI,看整个过程的图都放出来,也就是论文里,论文里拿了一张写着“M3”的色盲测试图,让模型去认。然后用Grad-CAM把AI“看”这张图的过程给全程直播了出来。
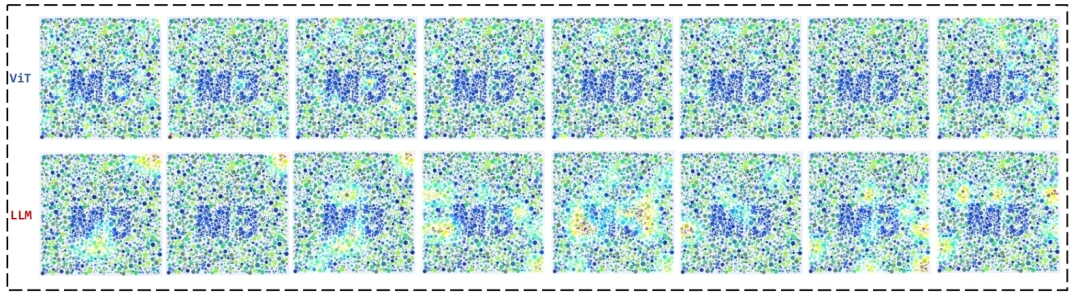
得先说一下,一个多模态AI的内部工作流,可以简单粗暴地分成两部分:
ViT (Vision Transformer):是负责看图的视觉编码器,可以理解成是AI的眼睛,主要是通过看图,把看到的东西转化成信息。
LLM (Large Language Model):是负责组织答案的语言端,可以理解成是AI的大脑,主要是接收ViT(眼睛)传来的信息,思考组织后说出答案。
你会看到,每个阶段都有一些亮度变化。
比如第五张图里,其实能看到模型捕捉到了一点M3的影子。
然后就彻底远离了正确答案。
往后看,亮的地方越来越分散。
结果当然是惨不忍睹的。
大脑收到的,就是一堆被眼睛看到的破碎的毫无重点的视觉信号。它拼了命地想从这堆垃圾信息里找出点规律,但根本找不到。
最后,它只能放弃治疗,在记忆库里随便抓了个看起来最像的答案“74”,然后硬着头皮说了出来。
所以,通过这个Grad-CAM的热力图,论文的作者们基本就破案了:
AI不是看不懂,它是从一开始看的方式就有大问题。
这就回到了我们开头那个柜子高光的例子。
AI看图的方式,存在一个根本性的、可以说是娘胎里带的缺陷,就是它看图,是真的断章取义。
现在的AI视觉模型(ViT),它的工作原理,就是先把一张图片,不由分说地切成一堆比如说是16x16像素的小方块(patches),就像切蛋糕一样。然后,它挨个去分析每个小方块里有什么纹理、什么颜色。
最后,再试图把这些小方块的分析结果给拼凑起来,理解整张图。
这个“先切碎,再拼凑”的工作模式,决定了它是个天生的细节控。它对局部的像素和模式极其敏感,但对这些部分组合起来形成的那个整体,却极其迟钝。
人类看东西时,大脑会先并行处理各种特征,比如颜色、形状、方向。
接着在注意力的作用下,把这些特征绑在一起,变成一个完整对象。
比如,你看到一个红色的苹果,大脑会先看到它是到红色的、圆的、表面光滑的。

通过注意力的整合,大脑给它贴上苹果这个标签。
这个叫做特征整合理论。
我们人类的视觉,是主动的、有目的的、懂得取舍的。 我们会用注意力这把刀,精准地剔除无关的噪音,然后把有用的特征缝合成一个整体。
但是AI不会。
它的注意力是摊大饼式的,是被动的,是雨露均沾的。
在它看来,构成数字“45”的那些棕色点,和作为背景的绿色点,重要性是差不多的,它无法形成一个“我要把棕色点组合起来”的宏观目标。
于是,它的注意力就被海量的、同等重要的像素点给稀释了、冲散了。信息越丰富,它的注意力就越贫乏。
最后,就在这片像素的汪洋大海里,彻底迷失了方向。
所以,你看,我们和AI看见世界的方式,从根上就不同。
我们在选择中看见,AI在计算中迷失。
聊到这里,我们似乎可以给开头那个问题一个更准确的答案了。
AI不是我们真正意义上的色盲。
它更像是一个患有严重“注意力缺失症”的患者。
它拥有顶级的视网膜,能识别精准的RGB值,但它的大脑无法有效地指挥这双眼睛,去关注真正重要的东西。
它就像一个拥有全世界所有乐高积木的孩子,却不知道该如何拼出一个城堡。它只能呆呆地看着满地的零件,给你数出这里有几块红的,几块蓝的。
这就是《像素、模式,但缺少诗意》这篇论文真正想表达的东西。
那个“诗意”,那个“格式塔”,那个“整体”,并不是某种神秘的、玄学的东西,它其实就是一种高效的、懂得取舍的信息组织方式。
而这,恰恰好像是目前的AI,最最缺乏的东西。
它在模仿人类的智商,但还没来得及学习人类的智慧。
而智慧的本质,在我看来,不就是知道该看什么,不该看什么吗?
知道什么不该做,远比知道什么该做,更为重要。
不过,我还有最后一个问题。
就是,为啥只要一让大模型做色盲测试,他们总是爱回答一个数,那就是:
74。

我做了一天的测试,现在看到74这个数字,都有点PTSD了。
在最后,我又搜了半天,居然还给我找到了答案。
那就是,如果你在维基百科上搜石原色盲测试的标准图。
上面的数字,就是74。
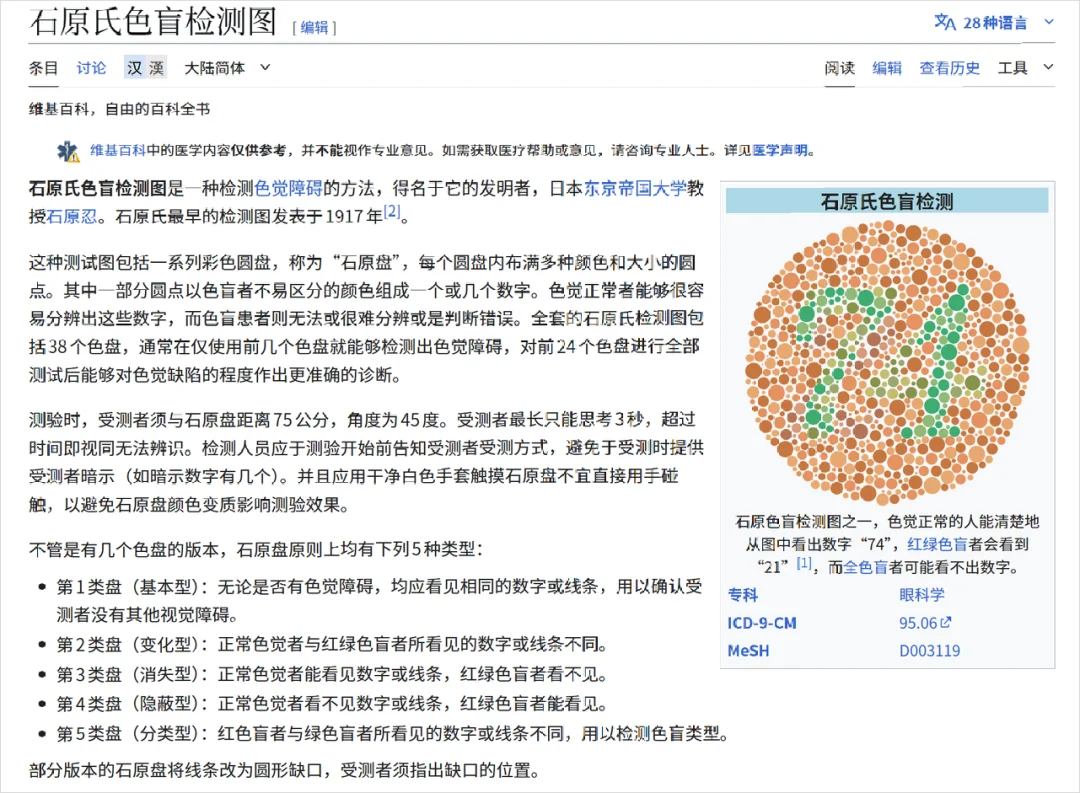
好家伙,原来又在这背书。。。
当AI无法从细节提取出整体的全局时,它就会参考已有的细节,转向记忆。
更直白点说,它会背答案。
跟我之前写过的那篇AI们数不清六根手指,这事没那么简单,底层逻辑几乎一样。
有时候真的还挺感慨,人类这个大自然最神奇的造物,还真是挺美妙的。
就连看见这事本身,它也是从光开始的。
所以无论是中国的盘古开天辟地还是西方的上帝造物, 这些神话故事中的世界都是从光打破黑暗展开。
光射到不同的物体上,有些波长被吸收,有些被反射。
我们只能看见被反射出来的光,那些被吸收的光我们永远看不到。
反射的光进入我们的眼睛后,经过视网膜上的细胞处理,大脑才给它赋予了红色、蓝色、绿色这些概念。
所以说,世上本没有颜色。
它不是客观存在的物理属性,它是人类视觉系统和大脑共同选择的主观感受和认知体验。
更是,我们的意识理解世界的方式。
我们也终究是活在关系里的生物。
我们看事物也从来不是孤立的点,是点与点之间连成的线,线与线之间围成的面,面与面之间涌现的诗。
AI的世界,一直都很像一片无垠的像素之海。
每一滴水,它都可以分析得清清楚楚,成分、温度、折光率,了如指掌。
但它却从未见过潮汐,也无法理解风暴,更不懂得,为何我们会对着一片汪洋,心生敬畏。
它总是在那个像素的海洋里,背诵着那如同宇宙真理一般的孤独的“74”。
而我们。
只需抬头,便能看见满天星辰。
文章来自于“数字生命卡兹克”,作者 “卡兹克、可达”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
