# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Claude Code 团队分享的 10 条内部技巧,已经很多人分享过了,大部分我还是结合自己经验解读一下。
其中最重要的一句话是:“没有唯一正确的使用方式,每个人的设置都不一样。”
我按难度分了层,加上自己的理解和背景信息。
这是团队最推荐的技巧,但不一定是你要学的技巧。
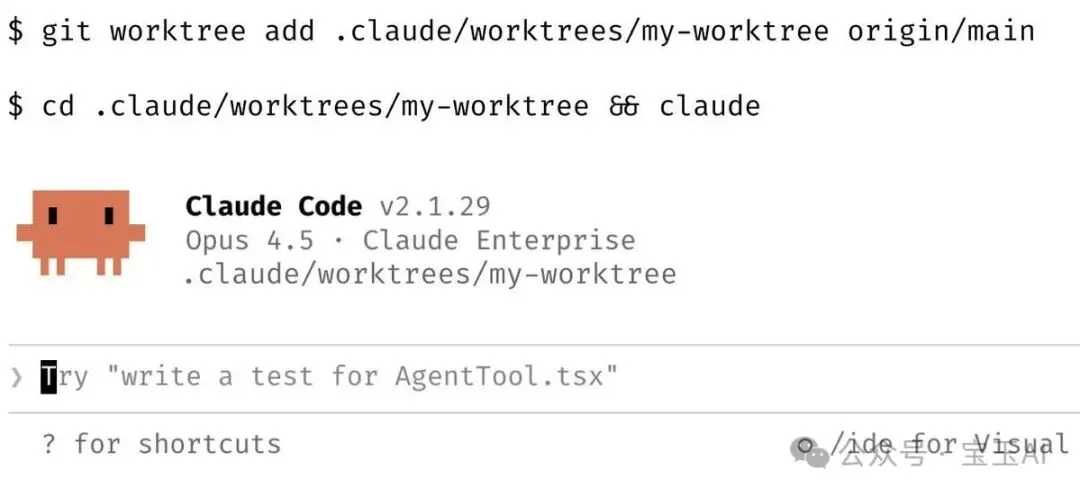
做法是用 git worktrees 同时检出 3-5 个工作目录,每个目录跑一个独立的 Claude Code 会话。比如目录 A 在重构模块,目录 B 在写测试,目录 C 在改文档。三件事并行推进。
Git worktree 是什么? 让你在同一个仓库里同时打开多个分支的工作目录,不用来回切换。命令大概是 git worktree add ../feature-a feature-a。
相关文档:https://code.claude.com/docs/en/common-workflows#run-parallel-claude-code-sessions-with-git-worktrees
团队里有人给 worktree 目录配上 shell 快捷键(za、zb、zc),一键跳转。还有人专门留一个“分析专用”的 worktree,只用来看日志、跑查询,不写代码。
Boris 本人用的是多个 git checkout 而不是 worktree,但团队大多数人更喜欢 worktree。Claude Desktop 应用为此专门加了原生支持。
为什么他们把这排第一? 因为它改变的是整个工作模式。从“一次做一件事”变成“同时推进多件事”。瓶颈从“等 AI 生成”变成了“我的注意力怎么分配”。
这个用法不一定适合所有人。
首先 git worktree 操作比较麻烦(可以让 Claude Code 帮你做)。我个人更喜欢 ClawdBot(一个开源的 Claude 客户端)作者 Peter 的方式,分几个目录,比 worktree 简单:
他就简单地 checkout 好几份仓库:clawbot-1、clawbot-2、clawbot-3、clawbot-4、clawbot-5。哪个空闲就用哪个,做完测试、推到主分支、同步。
然后并行任务会让你频繁切换大脑线程,对于编程这种需要注意力的事情还是挺麻烦的。需要一段时间练习。
我估计他们团队有不少简单的 Bug 修复任务,这类任务描述清楚后,基本上复制粘贴过去等着就行。
如果是多个复杂任务并行我不太推荐,当然想试试还是没问题。
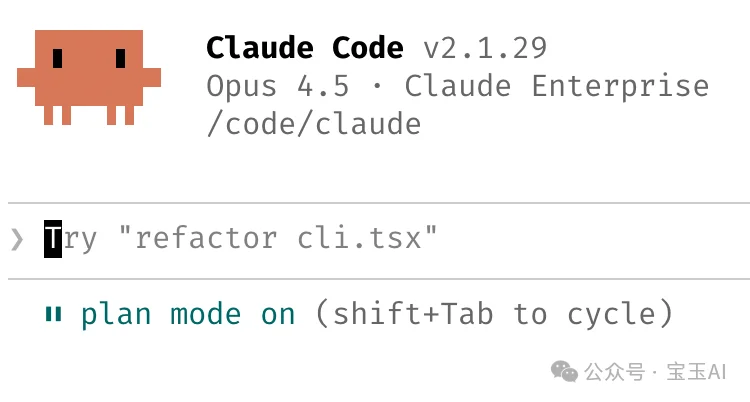
Plan Mode 的价值不只是“计划”本身,而是强迫你在动手前想清楚到底要什么,以及确保 Claude 懂你想要什么。
很多时候我们自己想做一件事时,一开始只有模糊的想法,不知道什么是最优解,这时候直接开始写代码不见得是好事,如果通过 plan 模式反复聊一下,可能就帮你梳理清楚了,有时候 Claude Code 还能有你意想不到的提议。
很多时候 Claude 写出来的东西不对,不是它不行,是它没理解清楚你真正想要的是什么就开始写代码了。通过 Plan Mode 反复聊天确认,可以确保它理解你的意图。
基本原则: 遇到复杂任务,先用 Plan Mode 和 Claude 讨论方案。反复迭代,直到你对计划满意,再切换到自动编辑模式让 Claude 执行。一个好的计划通常意味着 Claude 可以一次到位,不用来回改。
团队有人的做法更进一步:让一个 Claude 写计划,另开一个 Claude 以“高级工程师”的身份审核这个计划。让 AI 审 AI。
还有一条重要的补充:事情一旦跑偏,立刻回到 Plan Mode 重新规划。不要硬推,不要让 Claude 在错误的方向上越走越远。有人甚至会在验证步骤时也切换到 Plan Mode,不只是在“做”的阶段。
这可能是性价比最高的一个技巧。
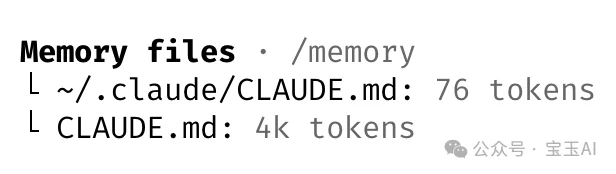
CLAUDE.md 是放在项目根目录的文件,Claude Code 每次启动都会读取它。你可以在里面写代码规范、设计原则、PR 模板、常见错误提醒——任何你希望 Claude 记住的东西。
关键在于怎么维护这个文件。团队的做法是:每次纠正 Claude 的错误后,让它自己更新 CLAUDE.md。
具体 prompt 可以是:“Update your CLAUDE.md so you don't make that mistake again.”
Boris 的原话是:“Claude is eerily good at writing rules for itself.”(Claude 非常擅长给自己写规则。)
团队里有个工程师的做法更系统:他为每个项目/任务维护一个 notes 目录,每次 PR 后更新。然后在 CLAUDE.md 里指向这些 notes,相当于给 Claude 建了一个持续更新的知识库。
这个思路跟我经常提到的 Skills 迭代思路类似。通常一开始规则不够完善,每次遇到问题,基于当前上下文让 Agent 自己去完善是效果最好的。一方面你不需要从头描述问题,另一方面 Agent 很善于归纳总结。
至于维护一个 notes 目录,是个蛮好的积累经验的实践。这事你不需要自己写,可以做一个 Skill,每次让 Claude Code 从当前会话中复盘,提炼成 Note。甚至可以连上 hook,每次会话结束自动执行。不过这条我个人不推荐,太多没意义的信息不见得是好事。
这个技巧的核心是把人脑里的经验变成系统知识。时间越长,CLAUDE.md 越完善,Claude 犯的错越少,你需要纠正的次数也越少。这是一种复利。
这里需要补充一个注意事项,CLAUDE MD 不建议放太多内容,只会适得其反,只放最重要的 AI 没训练过的内容,更多的内容作为文件链接按需读取。
很多人把设计模式、规范、最佳实践之类的都放进去,先不说这些 AI 都训练过,你最多说个名字就够了,就算是你需要的,也不是每次都要,不如放一个链接或者移到 Skills 按需加载。
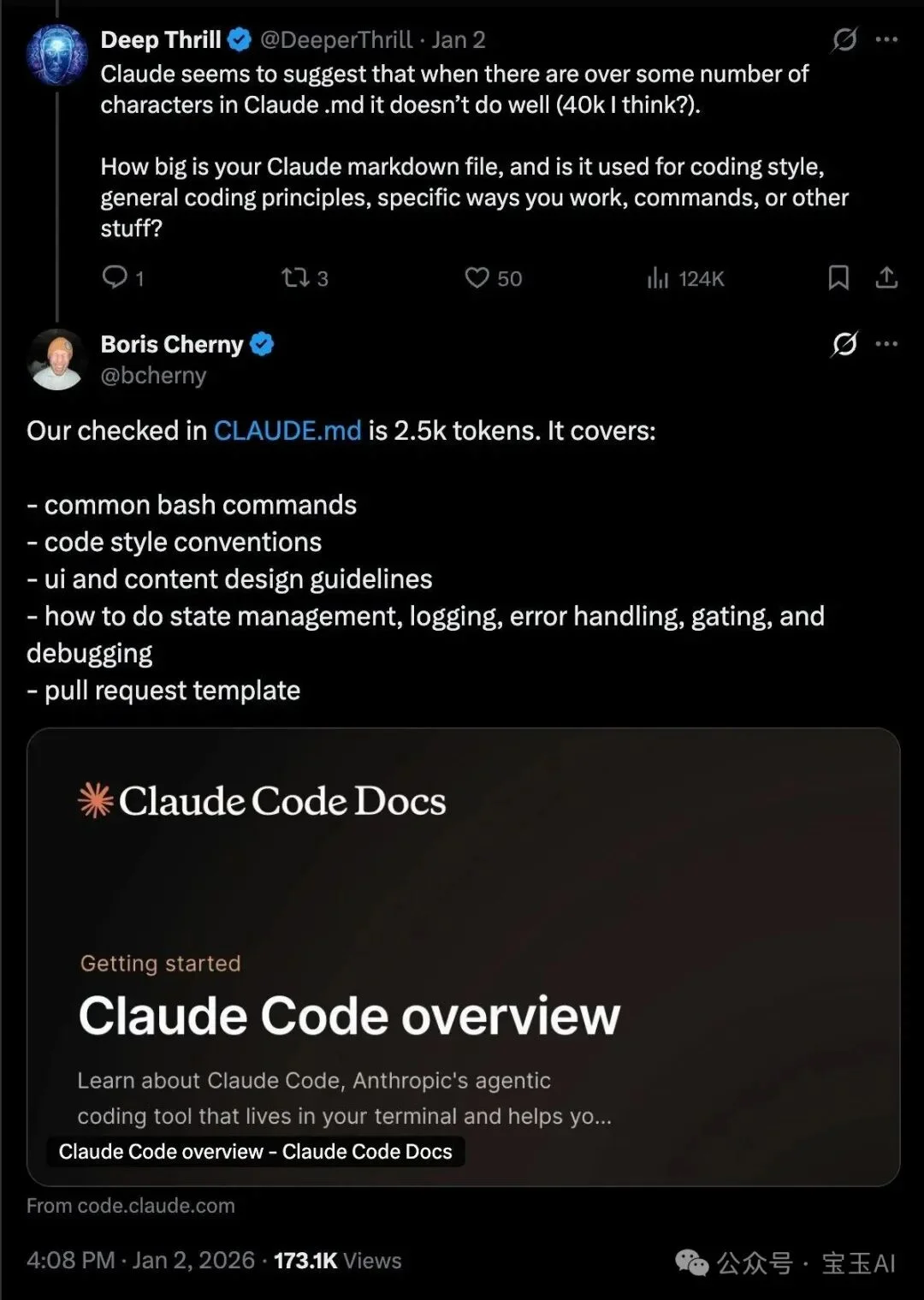
Claude Code 官方项目中 CLAUDE md 文件也就大约 2.5k tokens:
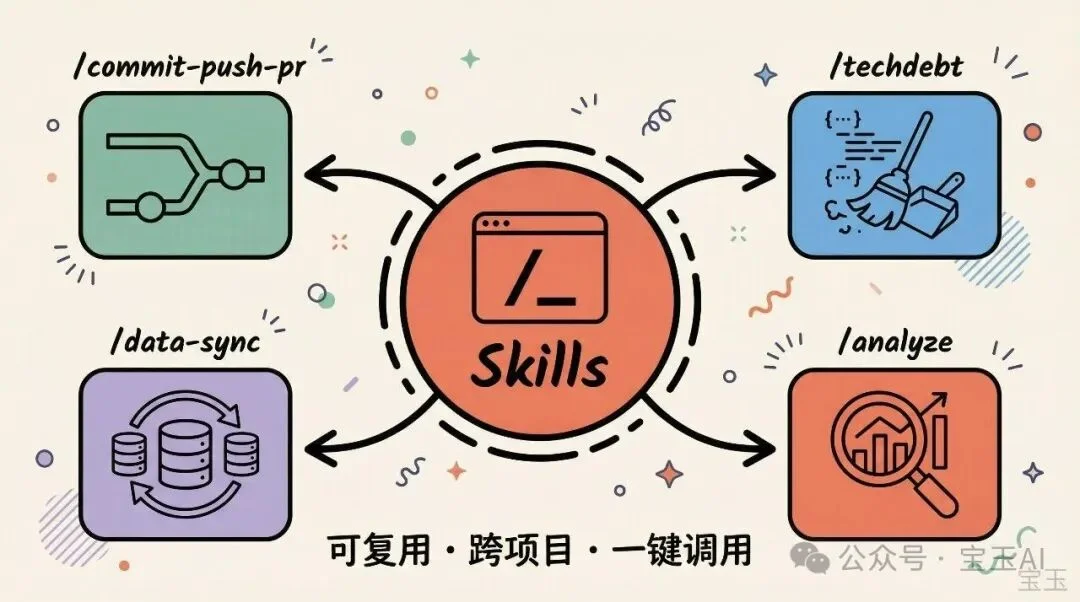
如果某件事你一天要做两次以上,就值得把它变成一个 skill 或者 slash command。
Skill 是一组可复用的指令,放在项目里,用斜杠命令调用。比如 /commit-push-pr 可以一键完成提交、推送、创建 PR 的整个流程。Boris 说他每天会用这个命令几十次。
团队分享了几个在用的 skill:
还有人搭建了一个 slash command,可以把过去 7 天的 Slack 消息、Google Drive 文档、Asana 任务、GitHub 活动同步到一个上下文里,相当于一键获取“这周发生了什么”的全景视图。
更高级的用法:有人用 skill 构建了“数据分析工程师”类型的 agent,可以自动写 dbt 模型、审核代码、在开发环境测试变更。
Skill 的好处是可以提交到 git,跨项目复用。你在一个项目里积累的自动化,可以带到下一个项目。
Skill 文档:https://code.claude.com/docs/en/skills#extend-claude-with-skills
团队的经验是:大多数 bug,Claude 自己就能修好。
一个常见场景:启用 Slack MCP,把 Slack 上的 bug 反馈帖子直接粘贴给 Claude,然后只说一个词:“fix”。不需要解释上下文,不需要手动定位问题。Claude 会自己去看代码、理解问题、修复。
另一个场景:CI 测试挂了。直接告诉 Claude:“Go fix the failing CI tests.”不要微管理它怎么做,让它自己去看日志、找原因、改代码。
更复杂的场景:分布式系统出问题,把 docker logs 指给 Claude,让它帮你排查。Boris 说 Claude 在这方面“surprisingly capable”(能力出乎意料地强)。
Boris 没说的是,描述 Bug 的时候要清楚:
换个角度说,假设是个程序员,看了你的 Bug 描述也能知道是怎么回事。有了这些基本信息,AI 才能有足够的上下文去定位和验证问题。
这个技巧的核心是给 Claude 足够的上下文和权限,然后信任它。不需要一步步指挥,让它自己闭环。
所以你看,这才是他们能多任务的重要原因——好多 Bug 都是 Claude Code 自己能修的。
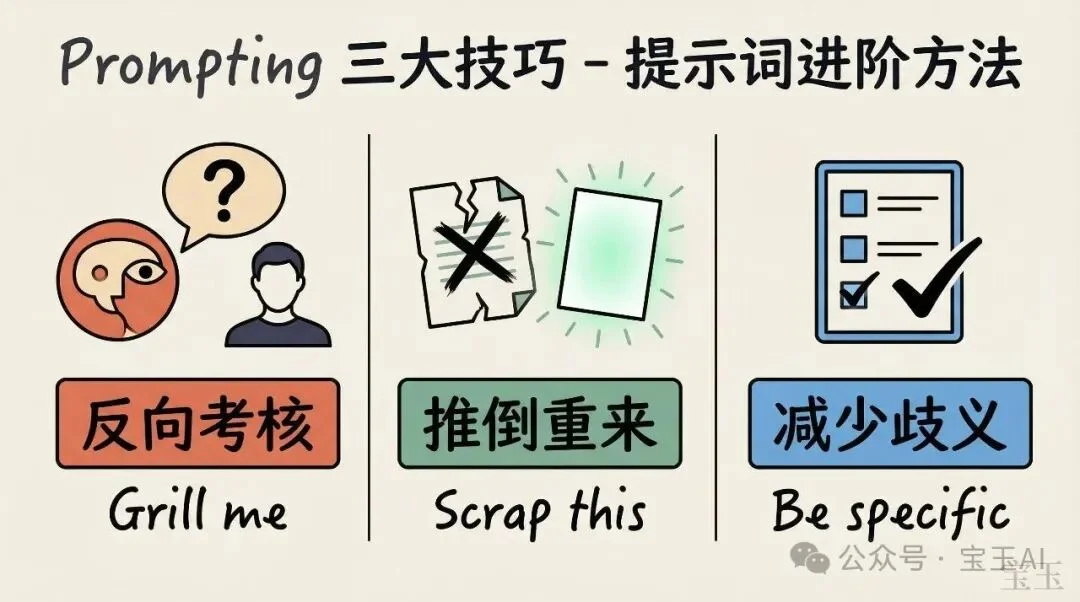
这一部分有几个具体的招数。
Prompt 示例:“Grill me on these changes and don't make a PR until I pass your test.”(针对这些改动考我,直到我通过测试才能提 PR。)
或者:“Prove to me this works.”(向我证明这个能 work。)让 Claude 对比 main 分支和你的 feature 分支的行为差异。
这相当于把 Claude 从“执行者”变成了“审核者”。让它反过来 review 你。
当 Claude 给出的方案不够好,不要在上面打补丁。直接说:“Knowing everything you know now, scrap this and implement the elegant solution.”(基于你现在知道的所有信息,扔掉这个方案,实现一个更优雅的版本。)
我通常会用 git 把代码回滚到修改前,然后新开会话、调整提示词重来。在当前会话继续的话,之前的错误信息可能会干扰 Claude 的判断。
交代任务时,spec 写得越详细越好。你越具体,Claude 的输出越准确。这听起来像废话,但很多人(包括我)还是习惯性地写模糊的需求,然后抱怨 AI 不懂。
其实人都懒,能一句话说清楚肯定懒得说第二句。用 Plan 模式相对好一点,你能知道它听懂了没有。
团队里很多人用 Ghostty 终端,理由是它有同步渲染、24 位真彩色、完善的 unicode 支持。这些对于同时开多个 Claude 会话很重要。
另一个实用技巧:用 /statusline 自定义状态栏,始终显示当前的 context 用量和 git 分支。这样你一眼就能知道每个会话的状态。
还有人用 tmux 管理多个会话,给每个 tab 上色、命名,一个 tab 对应一个 task 或 worktree。
Optimize your terminal setup 文档:https://code.claude.com/docs/en/terminal-config
最后一个容易被忽视的建议:用语音输入。
Boris 说你的说话速度是打字速度的三倍。更重要的是,用语音的时候你会不自觉地说得更详细,prompt 质量反而更高。
macOS 上按两下 fn 键就能启动语音输入。试试看?
这是一个进阶技巧,用好了很强大。
最简单的用法: 在任何请求后面加上“use subagents”。Claude 会自动把任务拆分给多个 Subagents 并行处理,相当于让它“开更多的线程”来解决问题。
另一个用法是用 Subagents 保持主会话的上下文干净。把一些独立的子任务分派出去,主会话只负责整体协调。这样主会话的 context window 不会被塞满中间过程。
Subagents 可以让任务并行,大大节约时间。比如我之前给文章生成插图的时候,就会让它跑 4 个 Subagents,把提示词文件路径传给每个 Subagent。不过实际用下来稳定性还不够,经常会有 Subagent 挂掉的情况,期待后续版本改进。
更高级的玩法:用 hook 把权限请求路由给 Opus 4.5(Anthropic 最强的模型),让它判断哪些操作是安全的可以自动批准,哪些需要人工确认。相当于给 Claude 加了一个“安全审核员”。
参考文档:https://code.claude.com/docs/en/hooks#permissionrequest

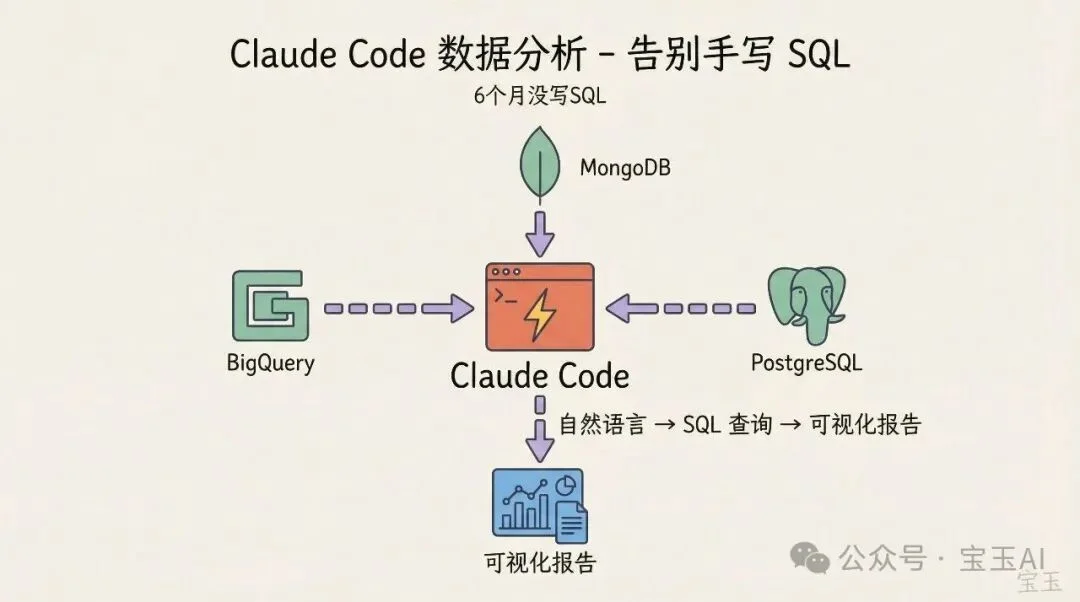
这个用法可能出乎很多人意料。
Anthropic 团队把 BigQuery 的使用封装成了一个 skill,所有人都可以在 Claude Code 里直接用 bq 命令行查询数据。Boris 说他已经六个月没写过一行 SQL 了。
这不限于 BigQuery。任何有 CLI、MCP 或 API 的数据库都可以这样用。PostgreSQL、MySQL、MongoDB,都可以让 Claude 帮你写查询、跑分析、生成报告。
对于非工程师来说这可能更有价值。团队里的数据科学家们现在也在用 Claude Code 写查询、做可视化。工具的边界正在模糊。
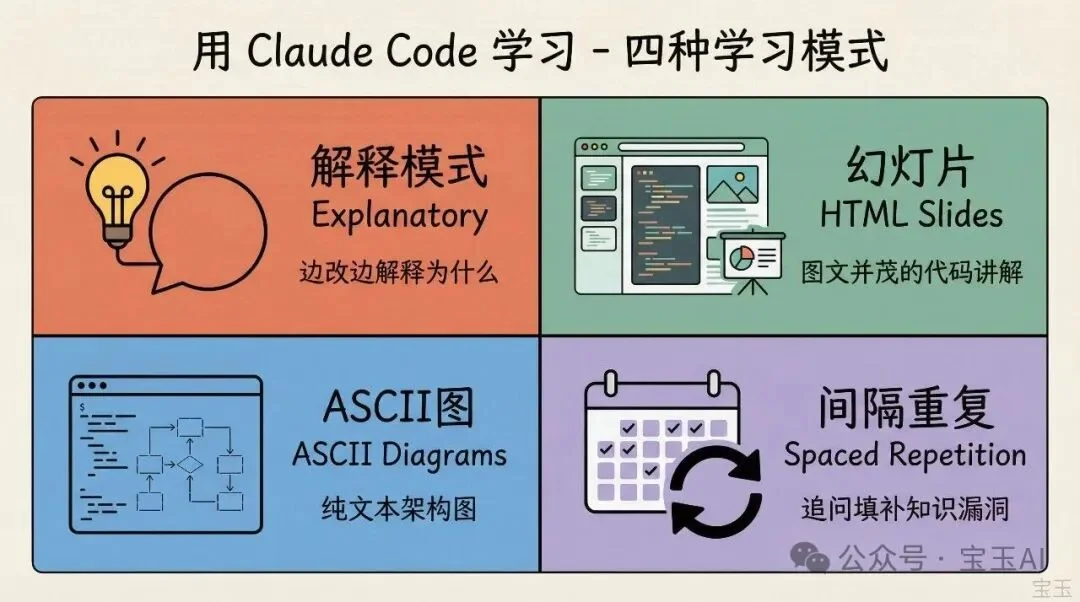
最后这个技巧是关于怎么用 Claude Code 来学习新东西。
首先,在 /config 里开启“Explanatory”或“Learning”输出风格。这样 Claude 在改代码的时候会解释“为什么”这么改,而不只是改完拉倒。
第二个用法:让 Claude 生成 HTML 幻灯片来解释不熟悉的代码。Boris 说效果出奇的好。你可以直接在浏览器里看一个图文并茂的代码讲解。
第三个用法:让 Claude 画 ASCII 图来解释协议、架构、数据流。纯文本的图表意外地有助于理解复杂系统。
最后一个高级玩法:有人搭建了一个“间隔重复学习”(spaced repetition,一种基于遗忘曲线的学习方法)skill。你先向 Claude 解释你对某个概念的理解,Claude 会追问来填补你的知识漏洞,然后把结果存下来。下次复习时再调出来。
Boris 在推文开头强调“没有唯一正确的使用方式”,这是最重要的一条。他的团队内部使用方式都各不相同。这些技巧是起点,不是终点。找到适合你自己的方式,比照搬别人的设置更重要。
文章来自于“宝玉AI”,作者 “宝玉”。



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
