# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
不是,谁也没跟我说今年的AI春节大战搞得这么猛猛猛啊!?!
年还没到呢,可灵就超绝不经意甩出一个「过大年计划」:推出可灵3.0多模态全家桶。
让每个人,都能上桌当——大导演。
我主打一个先尝为快!先看我导的这出《拳王》(赛博版)动作大戏,10秒钟狂切6个分镜头:

好莱坞大片也是手拿把掐,10秒钟切换7个镜头,从引擎轰鸣火花飞溅,再到男女主激烈争执,让我这个导演有点汗流浃背了...

灾难片自然我也不在怕的,浓雾封城、街道废弃、广告牌疯狂摇晃……咋样,是不是有点《后天》内味儿了:

不光我一个人玩嗨了,各位脑洞大开的网友们也纷纷share自己的大作了,下面这小哥直接搓出来了个超燃篮球赛大片,并直言够逼真!!!
还有网友感慨,以后拍电影怕是都不用找真人演员了,这不嘛,人家直接找AI演了波超抽象的家庭大戏,脑洞太大了…
反正这波实测下来我最直观感受就是:
智能分镜能力确实夯,模型确实更能理解镜头语言了,像文字和人物的一致性上表现也蛮超出预期。
具体哪些功能最好用、适合啥样的使用场景,我也帮友友们整理好了(省流版):
1)智能分镜|音画同步|主体一致性:特别适合做多镜头多对话的AIGC视频,在AI短剧、影视这类场景非常适用。
2)文字一致性:贼适合处理AI电商广告等场景的文字信息,文本形态基本能做到1:1还原!
具体实测效果咱往下看,顺带也欢迎大家来评评我这几部春节档大片,导的水平到底行不行?
咱们日常生成视频时,一直不停反复抽卡的主要原因之一便是——提示词太长、镜头太多,视频模型接不住。
尤其是经常做AI短剧、AIGC自媒体的朋友,对镜头切换的数量和质量要求都比较高,这类问题就更明显了……
好消息是,在全新的可灵视频3.0生成页面中,直接给模型安排上了个「分镜」小版块,长下面zhei样:
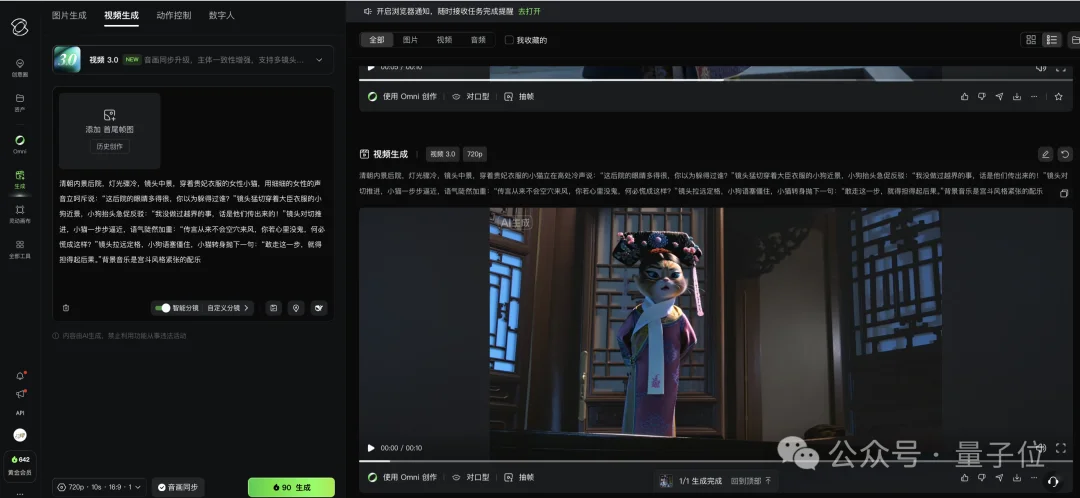
平台一共给咱提供了两种形式:智能分镜和自定义分镜。
我在智能分镜中,我们可以直接把一整段包含多镜头、多动作、多角色的提示词一股脑丢进去,AI会自动帮我们分成不同的镜头。
我最近正好在重温《甄嬛传》,但光看剧已经有点不过瘾了,索性直接让AI来一段后宫宫斗cut,于是我给它喂了一大段带双人对话、明确镜头切换的复杂提示词:

于是乎,一个阴雨夜贵妃猫娘娘和大臣小狗对峙的宫斗片段的画面就新鲜出炉了,别说还真有点紧张刺激那味儿了?

我给出的提示词中涉及了一个场景,四个镜头,两段角色对话和一个背景音乐。
先说优点,我只能说这智能分镜确实挺智能,涉及到的镜头、台词全部1:1地还原了,respect啊!
在音频处理上,小猫和小狗的语气、情绪和台词匹配度很高,发音里的轻重缓急也处理得不错,角色的表情和眼神跟对白对得也很准。
唯一的大bug:背景音乐没给我生成要,是能再来一段BGM就更对味儿了……
咱再玩点有意思的,来点跨界融合看看效果,我给出的提示词如下:

大明星猫猫一个眼神给出去,直接现场教学啥叫“身体成了一个X型”,别说这小身材搭配这小眼神整的还挺曼妙:

角色情绪和眼神动作都完全拿捏到位,而且猫猫的特写镜头给的特别好,看来这AI是懂点镜头语言的。
唯一的小bug出现在了台词上。
原本提示词里明确是小狗说“老师”,但模型在生成时把这句台词顺带分给了小猫,导致角色说话的对应关系被打乱,整体台词逻辑出现了点偏差~
(我猜可能跟我提示词的动词太多有关系……)
总的来说,智能分镜本身是靠谱的,多镜头结构基本不会出大问题,只是在台词和音频分配上偶尔会冒出一些小bug~
咱平日里只要生成涉及「主体角色」的AI视频,有个几乎90%都会遇到的问题——
角色明明只是换了个动作,结果上一秒和下一秒长得就已经不是同一个人了……
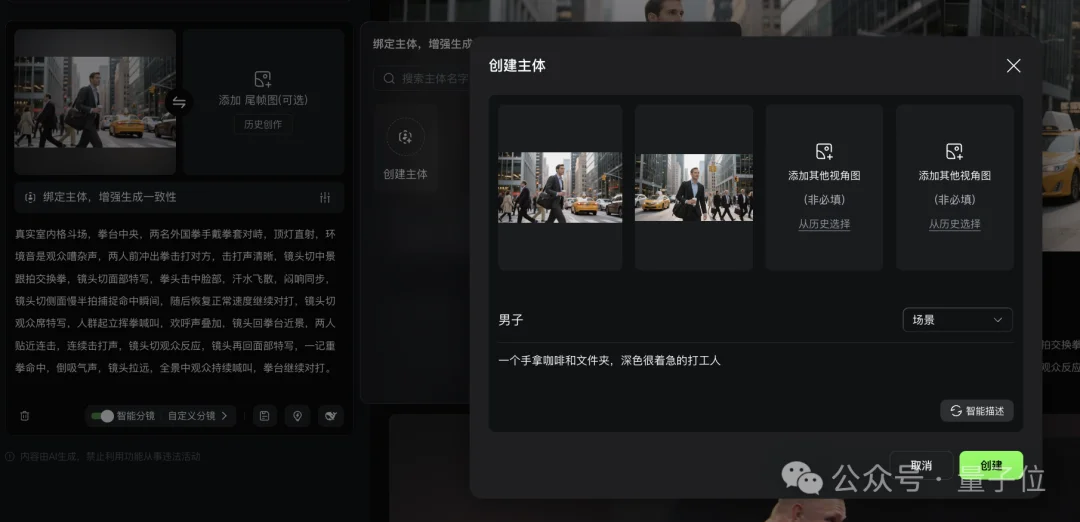
也不知道可灵这回受了啥启发,在视频3.0中直接搞了个多图或视频的主体参考功能。
我们可以直接绑定人物角色形象,并上传不同视角的参考图,这样一来模型在主体识别上就更稳稳稳了。
当然,稳不稳还得——实测说了算!
为了更好考察模型的主体遵循能力,这次我喂给AI的是一段包含人物多视角、多动作的提示词,并上传了两个不同视角的人物形象照:
一个火急火燎、赶着打卡的上班牛马,在马路上横冲直撞的名场面视频,这不就到手了嘛(doge):

为了让友友们更清楚地做对比,我把我输入和输出的角色形象截取对比了一下,大家觉得主体一致性表现如何???

emm…我是觉得镜头1和3和我给的原参考形象是近乎1:1还原的,但是镜头2就明显出现了问题。
人物的肤色明显变深了,发型也从原本的斜偏,直接变成了寸头……
我怀疑这里头的原因可能是因为我喂给AI的本身没有严格意义上的正面形象,所以AI自己脑补了一下?
整体来说可以给个80分内样。
这次,可灵视频3.0打的第三个招牌就是——字形保留高保真。(翻译:俺们AI生出来的字儿不变形
好大的口气,大家都要知道,相比角色一致性,文字一致性其实更难。
那我就不客气了,这次我给出AI的需求指令中,明确提到了光影变化、镜头切换以及旁白配合的多镜头场景,这就要求AI在不断运动和切换的过程中,依然能保持较高的文字一致性:

大家伙快来看看,AI给我搓出来了个近乎达到「商用水平」的香水广告宣传片demo:

即便镜头处在持续旋转运动中,香水瓶身的logo文字依旧保持清晰、不变形。
这其实也说明了模型在文字结构理解、空间变换下的稳定渲染以及跨镜头一致性保持上的能力已经相当扎实了。
最后,咱再来试一个可灵3.0视频模型中我自认为非常有意思的一个能力——说方言。
按照官方的说法,模型支持中、英、日、韩、西多语种生成,四川话、粤语等地道方言与各地口音。
要是这样的话,我有个大胆的想法,咱让奥特曼和马斯克跑天津来吃煎饼果子,顺便来一段地地道道的“贯口”:

俩人大裤衩子大背心一穿,吃大饼吃的那叫一个香啊,你别说,还挺入乡随俗???

画面这块基本没啥可挑的,直接给满分,人物主体一致性也确实还原得很到位,马斯克和奥特曼本人看了估计都得一愣!!!
但问题也很明显,咱这一题考的其实是方言能力,事实上,两位一个天津话没说对,一个北京话也没对上,反倒普通话说得相当标准……
我一度怀疑是不是AI对北京话、天津话不太熟,于是我索性再加一道题,让AI再生成了一个兵马俑说四川方言的视频:

这回对味儿了,虽然兵马俑长相有点惊悚,但是这四川话说的倒是蛮厉害的。
(有没有四川的朋友点评一下,这口音说的正宗不??)
除了O3视频模型,可灵这次还顺手上新了另一位全能视频选手——O3 OMNI,那这OMNI具体能干点啥呢:
咱先来看对复杂文本指令的遵循能力如何~
这次我喂给AI一段同时考察主体一致性、连续加减速的运动理解,以及多区域切换时的镜头跟随与时序控制的提示词:

10秒内,万圣节的小兔子完成了跳跃动作,并依次穿过落叶地面、南瓜灯和墓碑三个区域,自动补全了参考图中未给出的萌萌视频,不戳不戳!!

接下来玩玩分镜头叙事功能。
在全新的「O3 OMNI」模型里,我们可以直接自定义分镜,这次我上传了两张参考图(香蕉猫+优雅企鹅),然后把分镜脚本也一并塞了进去:

然后我就会得到一个香蕉猫和优雅企鹅在纽约街头盘算着吃豆腐脑的「抽象抓马」大戏:

暴露出来的问题也不少:第一帧背景白底直接出错,后半段香蕉猫的嘴形没对上,角色和背景的融合度也偏低,整体看下来,这是这轮里生成效果最差的一个……
(我是觉得不如智能分镜的效果好)
而且说实话,对我来说这种需要自定义镜头的方式也略微麻烦。
既要上传参考图,又要自己拆分镜头、逐一标注每个镜头的主体,如果折腾这么一圈,最后生成效果还不理想,u1s1,多少会有点难受……
感觉「自定义分镜」功能还是更适合对提示词和分镜脚本比较熟的朋友去用。
如果需求没那么高、又像我一样对提示词不算精通的话,还是更推荐大家直接用「智能分镜」。
突然想起来,我上一次用可灵还是在测试O1模型,这次实测下来,能明显感觉到3.0相比O1好用、也好玩了不少。
bug确实也有,但大部分也是现在多模态模型的通病,模型对于咱日常工作娱乐来说足够用了。
可灵的黑金会员可以先在Web端体验一波,非黑金用户也不用急,感觉全面开放应该很快就会来~
(期待一下叭)
文章来自于微信公众号 “量子位”,作者: “梦瑶”



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
