# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
以DeepSeek R1为代表的一系列基于强化学习(RLVR)微调的工作,显著提升了大语言模型的推理能力。但在这股浪潮背后,强化微调的代价却高得惊人。
高昂成本很大一部分来自训练过程中的“低效”。如果一直学习不合适的“考题”,既学不到东西,又造成了巨大浪费。想象一下,要培养一位“数学尖子生”,你让他做成千上万道题。若题目太简单,比如“1+1”,毫无意义;若题目太难,他根本不会,同样徒劳。
真正高效的训练,来自那些“跳一跳,刚好够得着”的题目。
此前,学术界和工业界主要有两种策略来给大模型“挑题”:
“题海战术”(Uniform Sampling):从题库中随机抽取题目给大模型。这会导致大量的算力被浪费在那些无法提供有效学习信号的题目上:如GRPO面对回答全对全错问题,梯度会坍缩为0,失去更新效果,白白浪费资源。
“先测后学”(Dynamic Sampling,DS):一些在线采样方法(如DAPO中的DS)被提了出以加速训练。其让大模型“自测”一个更大的候选题目集,并据此筛选出难度适中的题目进行训练。然而“自测”本身就需要大量的LLM推理,成本依然高昂。就像为节省尖子生的时间,却让他花更多时间去做额外的摸底测试。
有没有一种方法,既能精准地挑出难度最合适的题目,又不需要昂贵的大模型“自测”?
面对这一挑战,清华大学季向阳教授THU-IDM团队主导,与慕尼黑大学CompVis团队合作提出了一个全新的框架:基于模型预测的提示选择(Model Predictive Prompt Selection,MoPPS)。

该工作已被KDD 2026接收,受到包括阿里千问、腾讯混元、蚂蚁等业界的关注,以及UIUC张潼老师、UCL汪军老师、UvA Max Welling教授等知名学界团队的引用。
MoPPS解决的核心问题是:
能否不需要昂贵的大模型评估,就动态预测题目难度,并据此精准挑选训练数据,从而更高效地提升模型推理能力?

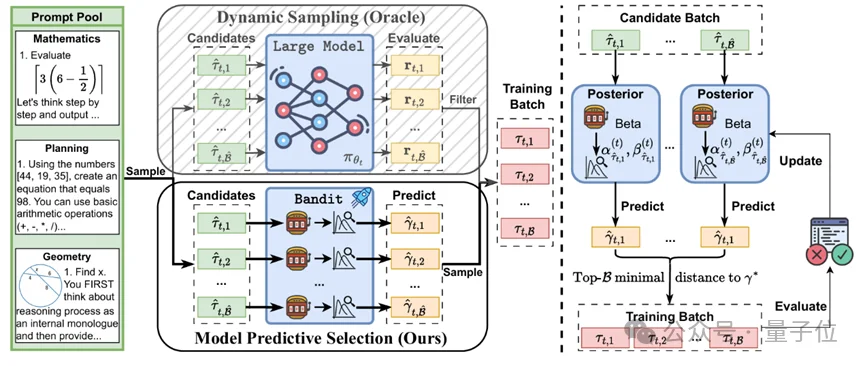
MoPPS的想法和实现非常简单:
MoPPS将每一道题(prompt,τ)看作一个老虎机臂。
MoPPS为每个题目配备一个Beta分布,用来估计其成功率:
α′ = α + 成功次数, β′ = β + 失败次数
α′ = λ·α + (1 − λ)·α⁰ + 成功次数, β′ = λ·β + (1 − λ)·β⁰ + 失败次数
MoPPS不依赖真实LLM自测,而是直接从Beta分布中采样预测难度:
这种设计有三个突出优势:
极低开销:预测基于Beta分布采样,不需要额外LLM推理。
动态适应:在线更新,难度估计越来越准。
探索与利用平衡:Thompson Sampling引入随机性,既能挑选已知最优题目,也会探索潜在有价值的新题。
MoPPS提出了一种预测-采样-优化的新范式:
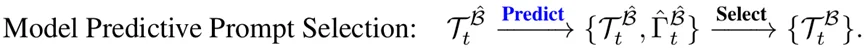
MoPPS在数学、逻辑、视觉几何三大推理任务上展现出显著优势:
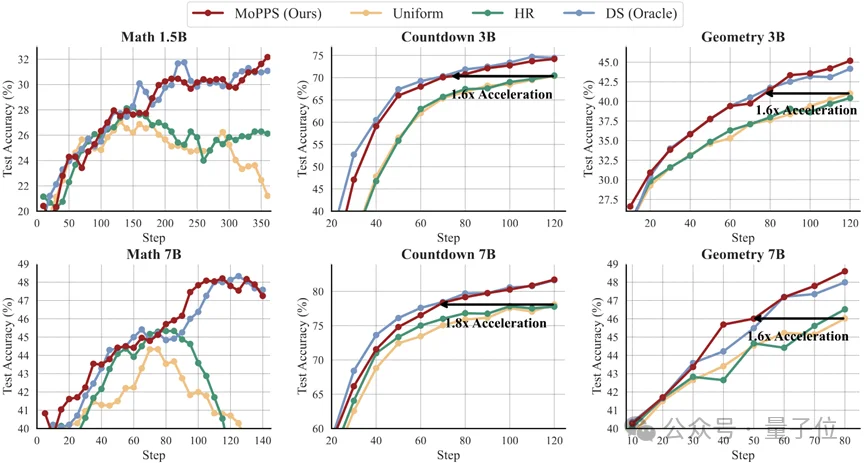
与需要大量额外推理的“先测后学”方法(如DS)相比,MoPPS达到相同性能所需的Rollouts减少了高达78.46%!
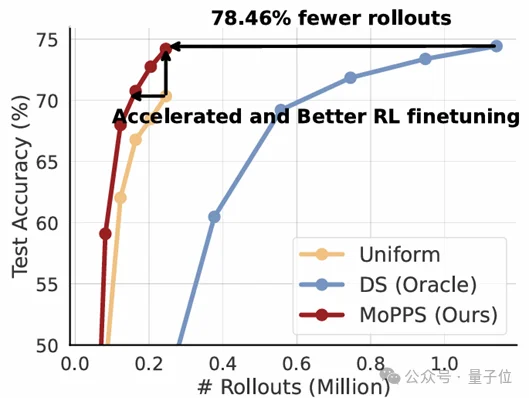
相较于传统的“题海战术”(Uniform采样),MoPPS总能为模型挑出最关键的题目,训练过程被大大加速。实现了高达1.6倍至1.8倍的训练加速,且训练效果更好。
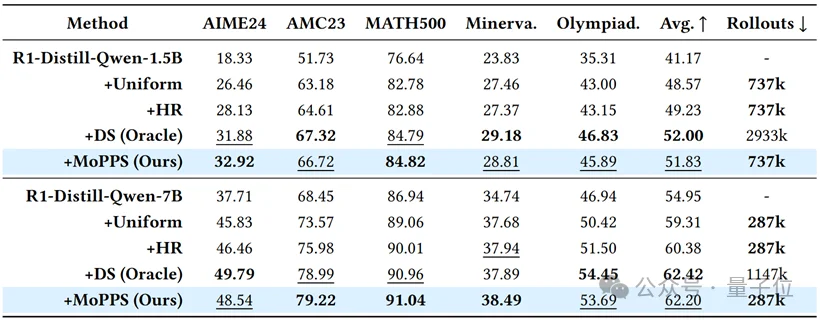
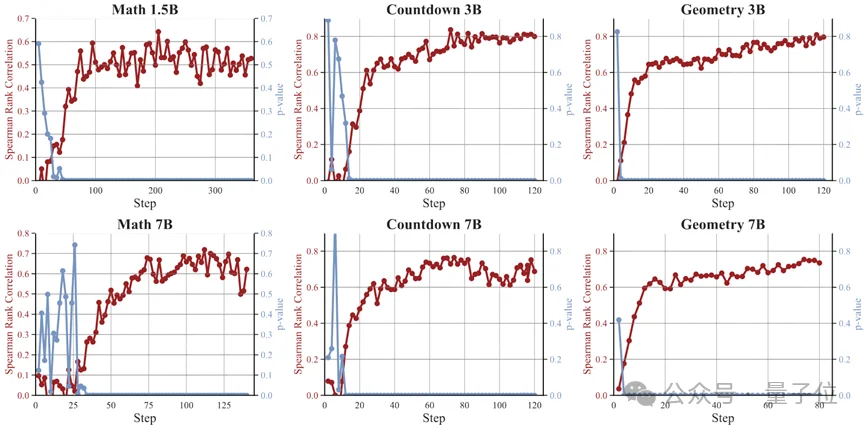
实验证明,MoPPS预测的题目难度与真实的题目难度之间,具有极高的相关性(Spearman Rank Correlation),证明了其预测的有效性和可靠性。
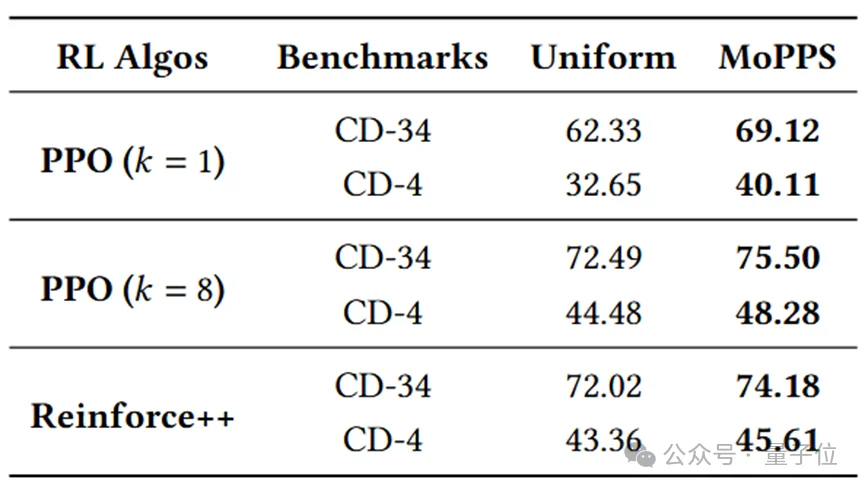
MoPPS作为“数据筛选器”可以即插即用,适配PPO、GRPO、Reinforce++等多种RL算法。
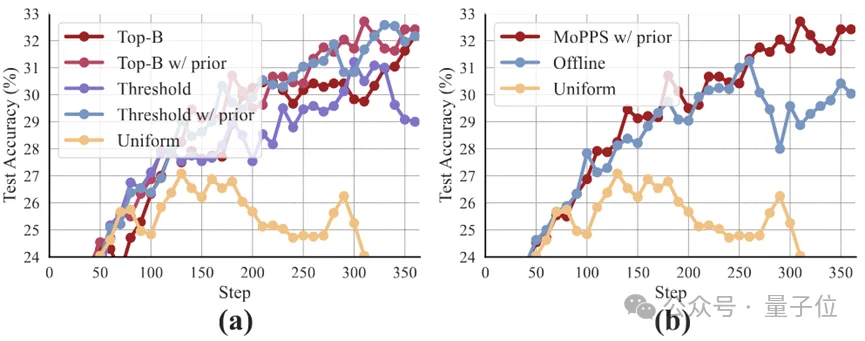
2. 支持不同采样策略并可引入先验信息:
MoPPS默认采用Top-B采样策略,但同样可以扩展为阈值采样(筛选难度落在某个区间的题目)。此外,还能结合先验知识,进一步加速前期训练。
这项由清华大学THU-IDM团队和慕尼黑大学CompVis团队合作的研究,为大模型强化微调领域,提供了一个“降本增效”的利器。
MoPPS框架的核心贡献在于提出了一种全新的“先预测,再优化”(predict-then-optimize)范式。未来,MoPPS有希望应用于更大规模的大模型强化学习后训练。
论文标题:
Can Prompt Difficulty be Online Predicted for Accelerating RL Finetuning of Reasoning Models?
论文链接:
https://arxiv.org/abs/2507.04632
代码链接:
https://github.com/thu-rllab/MoPPS
团队主页:
https://www.thuidm.com
文章来自于微信公众号 “量子位”,作者: “量子位”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
