# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

“信息图”是这款模型的发力重点。
字节的图像生成模型刚发不到半天,阿里的新模型也来了!
智东西2月10日报道,今天,阿里巴巴发布了新一代图像生成基础模型Qwen-Image 2.0,这一模型支持长达一千个token的超长指令、2k分辨率,并采用了更轻量的模型架构,模型尺寸远小于Qwen-Image 2.0的20B,带来更快的推理速度。
智东西第一时间对阿里Qwen-Image 2.0、字节Seedream 5.0 Preview以及谷歌Nano Banana Pro三款模型进行了横向体验比较,发现Qwen-Image 2.0在长指令遵循、长文本渲染方面确实具有优势,但在图像生成的真实感上仍稍逊于Nano Banana Pro。
Qwen-Image 2.0的升级重点是文字渲染。在下方关于AB测试的官方案例中,文字的字体、排版、格式等都是由一则888个token(包含近千个中英文字词)的超长提示词精确定义的,而Qwen-Image 2.0可以做到不错的还原。

Qwen-Image 2.0还能用毛笔字渲染《兰亭集序》的全文,并且确保文字和画面的相对协调,文字没有遮挡画面的山水景色和人物。细看文字部分,虽然仍然可以找到一些渲染失败的文字,但是占比已经很低了。

Qwen-Image 2.0还支持一次性渲染属数十个子图,并保持其中主体的一致性。比如,下图就是Qwen-Image 2.0一次性生成的漫画,一共有24个画面,其中的人物、画风都较为连贯。
针对AI生图常见的“油腻感”问题,Qwen-Image 2.0也做了优化。与前一代模型相比,Qwen-Image 2.0的色彩不会过于饱和,观感更像实拍,AI味淡了一些。

▲从左到右:原图、Qwen-Image-2512、Qwen-Image 2.0
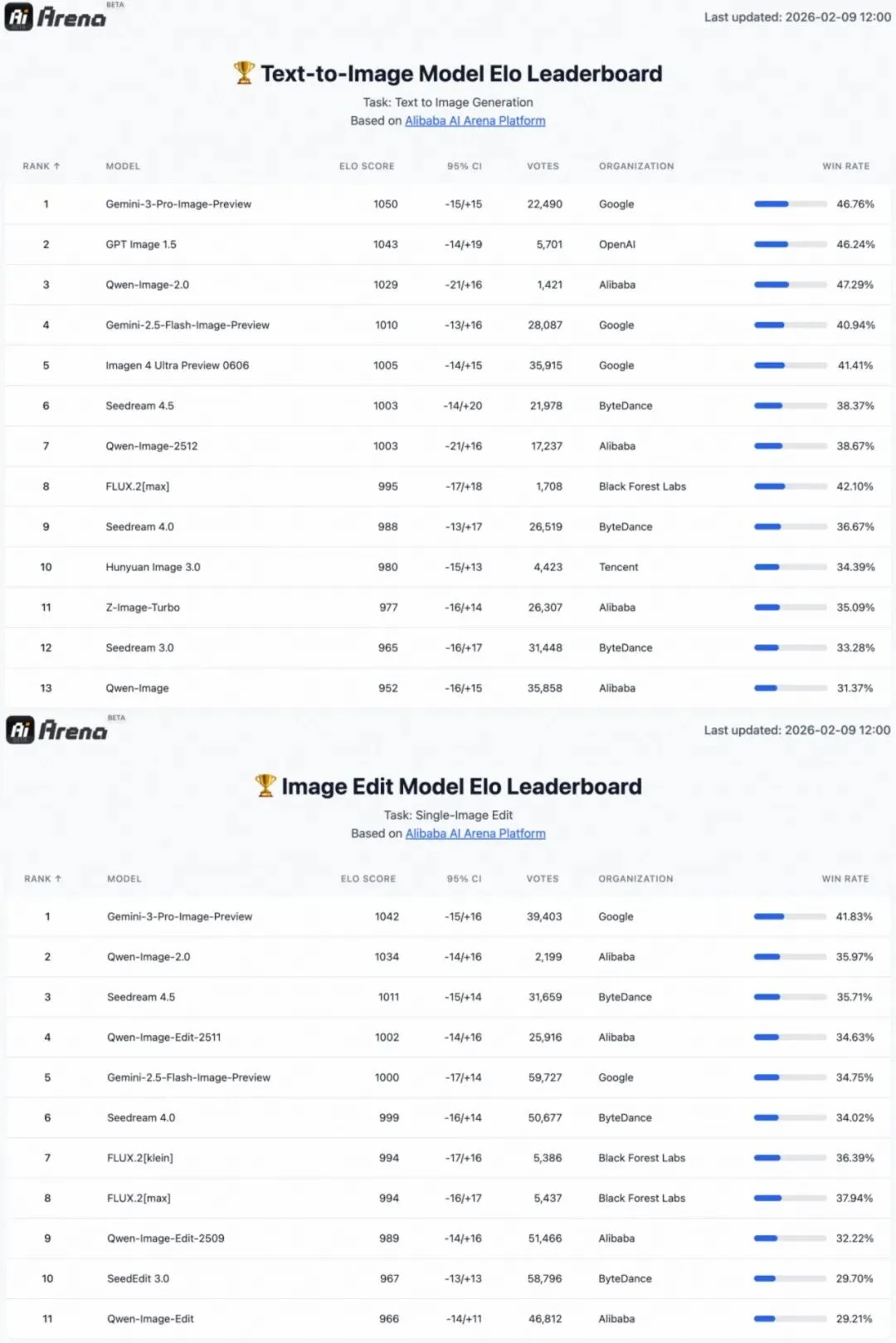
阿里在AI盲测平台AI Arena上对Qwen-Image 2.0进行了测试,数据显示,Qwen-Image 2.0在文生图和图生图基准中分别排名第三和第二,不过距离谷歌的Nano Banana Pro(图中为Gemini-3-Pro-Image-Preview)还有一定差距。此外,这一模型暂时还没有和刚发布的Seedream 5.0 Preview进行对比。
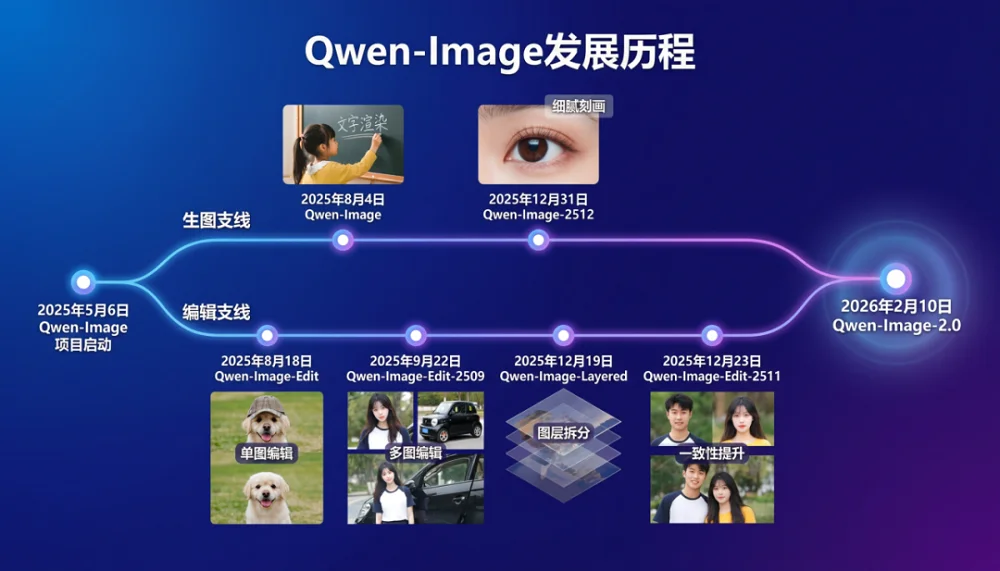
千问视觉生成负责人吴晨飞在采访中谈道,Qwen-Image项目2025年5月份项目才立项,去年8月份发布首款模型,此后主要围绕生图和编辑两个支线迭代模型,而Qwen-Image 2.0则把生图和编辑两个能力整合到了一个模型中。
目前,Qwen-Image 2.0已在阿里云百炼上已开通API邀测,用户也可通过Qwen Chat(chat.qwen.ai)免费体验新模型。千问App产品经理刘巍透露,这一模型后续将在千问App里上线。
会后,我们还与吴晨飞和千问大模型高级解决方案架构师熊瀚天进行了沟通。
当我们问及Qwen-Image系列模型的未来规划时,吴晨飞称,如果用一个词作为Qwen-Image 2.0升级的核心,那就是“信息图”,而在未来一年,Qwen-Image团队会继续研究如PPT、多图海报、漫画等复杂“父图”的生成,进一步减少幻觉和错误。
此外,该团队还计划在此前发布的分层模型基础上,进一步强化模型的分层编辑能力,目标是让生成模型真正成为生产力工具。通过AI分图层,设计师可以灵活结合AI生成(如千问编辑特定层)与传统手段,或融合不同模型的专长,实现“分而治之”的复杂编辑流程。
阿里、字节、谷歌三款模型对决
Qwen-Image 2.0文字渲染能力突出
在超长提示词任务上,我们对Qwen-Image 2.0的官方超长提示词进行了微调,调整了部分元素的位置,看看Qwen-Image 2.0能否交付同样质量的生成结果。
提示词内容:

Qwen-Image 2.0的生成结果如下。可以看到模型还原了我们对图片布局、字体颜色的要求,内容也得到准确呈现,基本没有遗漏。
而Nano Banana Pro的生成结果明显有更多的图像和图标,设计风格和我们要求的一样,大部分文字也都成功渲染。美中不足的是,可以看到部分文字出现了模糊的问题,已经难以辨别。
Seedream 5.0 Preview的生成结果较我们的提示词出现了一些偏差,并没有准确还原文字内容,这在PPT等场景可能是较为严重的问题。但是抛开这一问题之外,完成度还是不错的。

而在多子图生成任务上,我们让上述三款模型生成一副具有20个分镜的漫画,提示词依旧较长。
在经过三次尝试后,Qwen-Image 2.0未能完全按照我们的要求生成这张图像。我们也对提示词本身进行了优化,标注了更为清晰的序号,但是没能让模型生成更准确的结果。
此外,画面中也有一些不符合常理的现象,比如外卖员的手机竟然安在电动车车头上,手机屏幕面向外侧,。

▲Qwen-Image 2.0的三个生成结果
在这一任务中,Nano Banana Pro(左)和Seedream 5.0 Preview(右)拿到提示词后都陷入了长时间的推理过程,最终未能成功生成。
文字渲染之外,我们也考察了这两款模型在图像生成方面的表现。发布会中提到,超现实场景其实对图像生成模型来说是一大挑战,如何在满足提示词要求的情况下保证真实感,很考验模型的功力。
我们向模型发送了如下提示词:
无边无际的海面上漂浮着一座倒置的城市,城市建筑如水晶般透明,内部流动着星空与光点。天空呈现撕裂般的云层结构,巨大的月亮贴近海平面,月光化为实体的光带缠绕在城市周围。一名渺小的人站在水面之上,脚下泛起涟漪,现实与梦境在此交汇,画面安静而震撼
Qwen-Image 2.0生成的画面其实与提示词有一些差距,图中的城市与其说是倒置,不如说是镜像。同时,左右两侧云层的形状是完全对称的,在美感上较有视觉冲击力,在真实性上稍显欠缺。

Nano Banana Pro的生成结果则更符合我们的提示词,还原了城市的“倒置”、云层的“撕裂感”等关键描述。

Seedream5.0 Preview提供了四个版本,可以看到它并没有遵循我们提示词中“像水晶般透明”的要求,不过其余内容基本得到了还原。其画风更为科幻感一些。

生成、编辑融合效果1+1>2
新模型尺寸远小于1.0版本
发布会结束后,千问视觉生成负责人吴晨飞、千问大模型高级解决方案架构师熊瀚天与智东西等媒体进行了沟通。
当谈及1.0版本与2.0版本相比,最大的提升在哪些领域,吴晨飞称Qwen-Image 2.0主要实现了“多”和“真”两个特性的融合。
“多”指的是其更强的文字渲染能力。Qwen-Image 2.0能在一个画面中稳定生成大量、复杂的文字(如完整的PPT、信息图),错误率极低,基本达到“可用”状态,而之前的模型生成结果依然是不可用的。
“真”指图像的真实感。1.0主要聚焦文字准确性,2.0在保证文字精准的同时,提升了图像(如材质、光影)的真实感。尤其当文字与图像结合时,生成结果更具真实感和代入感,减少了以往AI生图在文字区域的模糊和虚假感。
谈及融合图像生成与编辑的选择时,吴晨飞透露,经过探索,他们发现二合一模型能实现能力相互促进,达到1+1>2的效果,而非功能妥协。
文生图中训练出的能力(如文字生成、图像质感)可以迁移到编辑任务上。例如,上传照片“题诗”的功能,就是文生图能力在编辑任务上的体现。
编辑任务训练能迫使基础模型更好地理解语义变化和遵循指令,从而反哺文生图,使其对提示词更敏感、遵循更精确。这也是实现“理解-生成”一体化统一范式的重要一步。
此外,Qwen-Image 2.0的模型尺寸比1.0(约200亿参数)显著减小,但能力更强,且生成速度更快。

▲千问视觉生成负责人吴晨飞
当被问及如何解决文字生成崩溃的难点时,吴晨飞回应道,目前大部分生图模型都需要用到VAE(变分自编码器)负责图像压缩,小文字信息密集,压缩难度大,因此容易出现文字崩坏。其团队提升了VAE的重构能力,为清晰小字生成奠定基础。
Qwen-Image 2.0对密集、细小文字的建模和生成能力也得到了增强。两者结合,使得小文字也能清晰渲染、准确显示。
熊瀚天则分享了与模型落地场景相关的话题。他认为,模型能力的提升(尤其是可控性、稳定性)使其能真正渗透到各行各业。
在电商领域,图像生成模型可用于海量商品的主图、详情图、广告素材图生成。例如,服装行业的模特换装、商品属性修改、多图融合,以及利用“信息图”能力生成商品详情长图。
在医疗等专业领域,图像生成模型可以将复杂的流程(如就诊流程、诊断报告)通过信息图、流程图等形式可视化,便于理解。
他认为,中国AIGC市场在应用落地和产业迭代速度上具有优势。国内有强大的应用土壤和快速落地的能力。当技术追平后,丰富的应用场景能催生出新的产业链(如短剧),并快速反哺模型迭代。
Qwen-Image系列将与WPS等国民级应用进行合作,获取真实用户反馈和需求,并融入下一代模型开发,形成从应用到技术的闭环迭代。
结语:从玩具到生产力
图像生成模型探索真实场景落地
从近期的发布情况来看,图像生成领域的多家头部厂商已达成共识。如今,图像生成模型不仅仅追求生成逼真的画面,更要满足现实场景中对提示词精准遵循、文字准确渲染等关键因素的需求,这些才是真正决定模型生产力的核心要素。
随着模型的不断优化与迭代,图像生成或许有潜力成为企业和个人在信息处理、创作表达及决策支持等方面的强大助手。
文章来自于微信公众号 “智东西”,作者 “智东西”



【开源免费】ai-comic-factory是一个利用AI生成漫画的创作工具。该项目通过大语言模型和扩散模型的组合使用,可以让没有任何绘画基础的用户完成属于自己的漫画创作。
项目地址:https://github.com/jbilcke-hf/ai-comic-factory?tab=readme-ov-file
在线使用:https://aicomicfactory.app/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
