
Qwen-Image-3.0效果炸裂?我反手扔了这9道题
Qwen-Image-3.0效果炸裂?我反手扔了这9道题千问说它可以帮我拼九宫格了,还是不同主题的那种。
来自主题: AI产品测评
6251 点击 2026-07-24 11:05
 搜索
搜索
千问说它可以帮我拼九宫格了,还是不同主题的那种。

今天,阿里通义团队发布了他们第三代图像生成模型:Qwen-Image-3.0 。官方博客用了一个字来概括这一代的核心进步,「实」。不是好看,不是炫技,是「实」。内容丰实、细节真实、知识厚实。

MrFlow(Multi-Resolution Flow Matching)就用这样的三阶段,在Qwen-Image等模型上把端到端生成时间从49.32s压到4.77s,实际加速10.35x。文章发布当日即登上Hugging Face Daily Papers;发布三天内,GitHub已收获200+stars;目前也已登上Hugging Face Trending Papers。

近年来,文生图模型的能力快速提升。从 Stable Diffusion 到 FLUX、Qwen-Image,扩散模型已经能够生成高质量图像,也能处理越来越复杂的文本提示。

VeRL-Omni 是一个面向多模态生成模型的通用 RL 后训练框架,由 VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。覆盖扩散 transformer(Qwen-Image)、混合 AR-DiT(Qwen-Omni)、统一理解 + 生成(BAGEL、HunyuanImage-3.0)等架构。
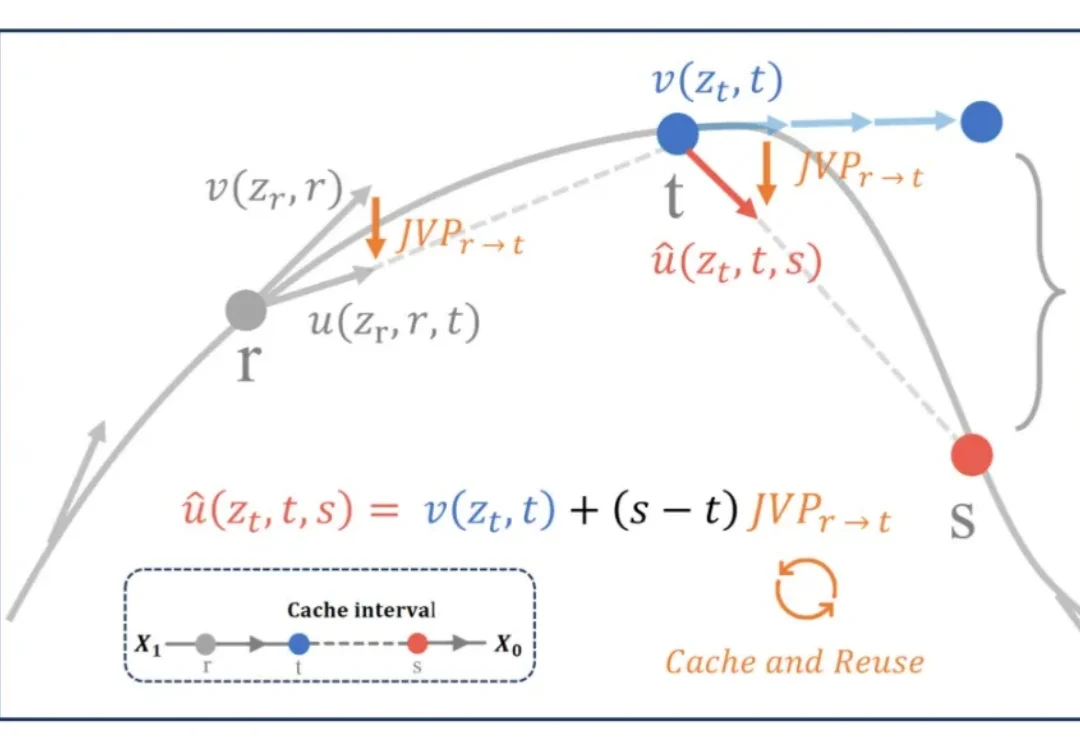
FLUX 、Qwen-Image 等多模态生成模型的推理速度一直是工业级多模态模型落地的痛点。传统的特征缓存(Feature Caching)方案在追求高倍率加速时,常因瞬时速度的剧烈波动导致轨迹漂移。
千问前脚刚把Qwen-Image-2.0甩出来,后脚就又放大招,冲着牛马党学生党的「痛处」下手了——就在这两天,重磅发布了AI PPT生成工具:Qwen AI Slides(幻灯片),据说从内容结构到视觉配图,一套全包……

BUBBLE 2026 — ISSUE #18 家人们, 马上没几天快过年了,明显各个厂商已经开始疯狂卷了。 上周到现在,让我们来算算有多少东西了, 5.3 Codex,4.6 Opus, 可灵3.0

今天,阿里巴巴发布了新一代图像生成基础模型Qwen-Image 2.0,这一模型支持长达一千个token的超长指令、2k分辨率,并采用了更轻量的模型架构,模型尺寸远小于Qwen-Image 2.0的20B,带来更快的推理速度。

AI生成一张图片,你愿意等多久?在主流扩散模型还在迭代中反复“磨叽”、让用户盯着进度条发呆时,阿里智能引擎团队直接把进度条“拉爆”了——5秒钟,到手4张2K级高清大图。