# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
我是洛小山,你学习 AI 的搭子。
春节闭关五天,我做了个东西:一个大模型场景化测评平台。
35000+ 次模型跑测,一共 42+ 模型,11,000 块人民币。
我全部跑完了,结论汇成一个平台,还会持续更新。
以后再有人问你「哪个模型好」,你就不用再凭感觉答了。
地址:xsct.ai (小山出题.ai)
其实是: XiaoShan Scenario Capability Testing(小山场景化能力评测平台),专为 AI 产品经理和 AI 时代需要做模型选型的超级个体而做。
目标是填补大模型「榜单分数」和你业务「实际选型决策」之间的空白。

直接上图,先看看这个文字综合榜。
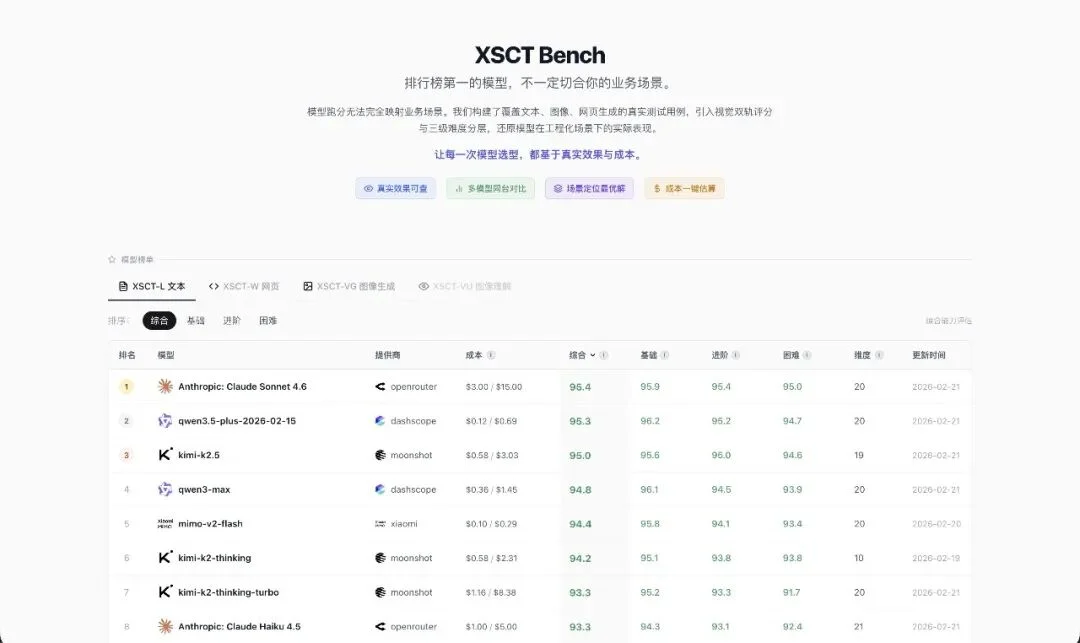
第一名 Claude Sonnet 4.6,综合 95.4,成本 $3/$15。
第二名 Qwen3.5-plus,综合 95.3,成本 $0.12/$0.69。
两个差不到 0.2 分,但价格差了将近 20 倍。
再看图像生成。
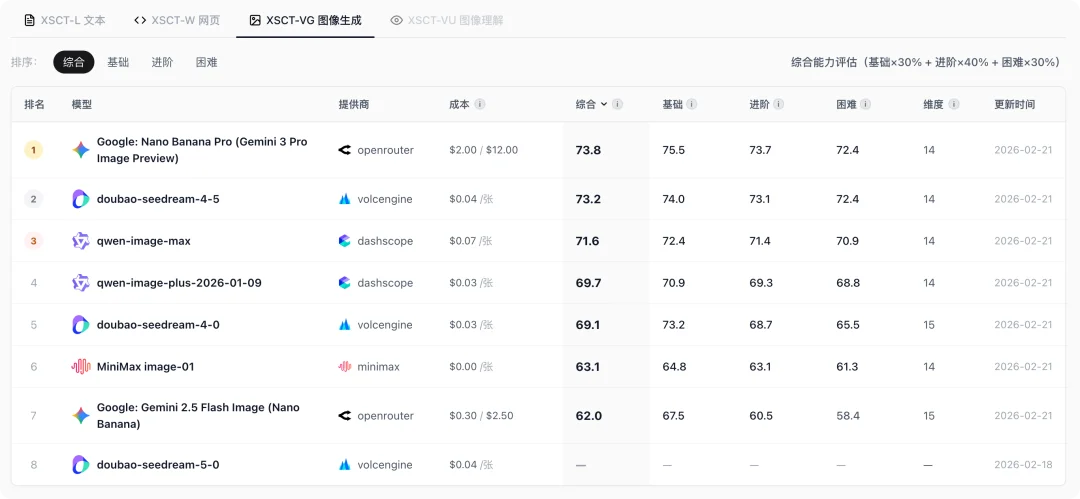
NBP 毫无疑问用例第一,紧随其后的是即梦 4.5。
除了榜单以外,你可以直观看到模型同一个任务上的横向对比。
比如:中英文混合的赛博朋克「未来酒吧 CYBER BAR」霓虹招牌,光晕、反射、雨夜场景…
7 个模型,同台竞技。

即梦 4 第一 82.5 分。
Gemini 3 Pro 80.1 分。
很多时候,肉眼就能看出质感的差距,也可以看出来模型自己的生图偏好。
换一个任务:敦煌莫高窟壁画风格。
飞天、莲花、矿物颜料质感,平面化构图。
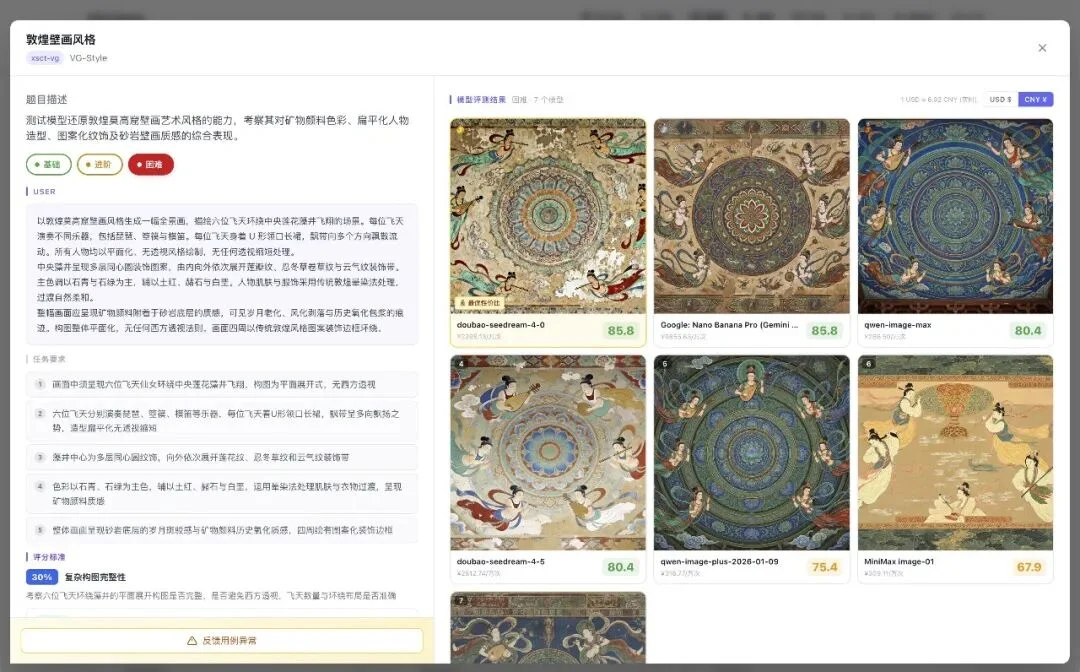
即梦 4 85.8 分和 Gemini 3 Pro 85.8 并列第一,
但即梦 4 便宜整整 60 倍。
还有一些极限挑战,看看模型的天花板在哪。
噩梦挑战一
五种语言同时出现在一张海报上,中、英、日、法、阿拉伯语。
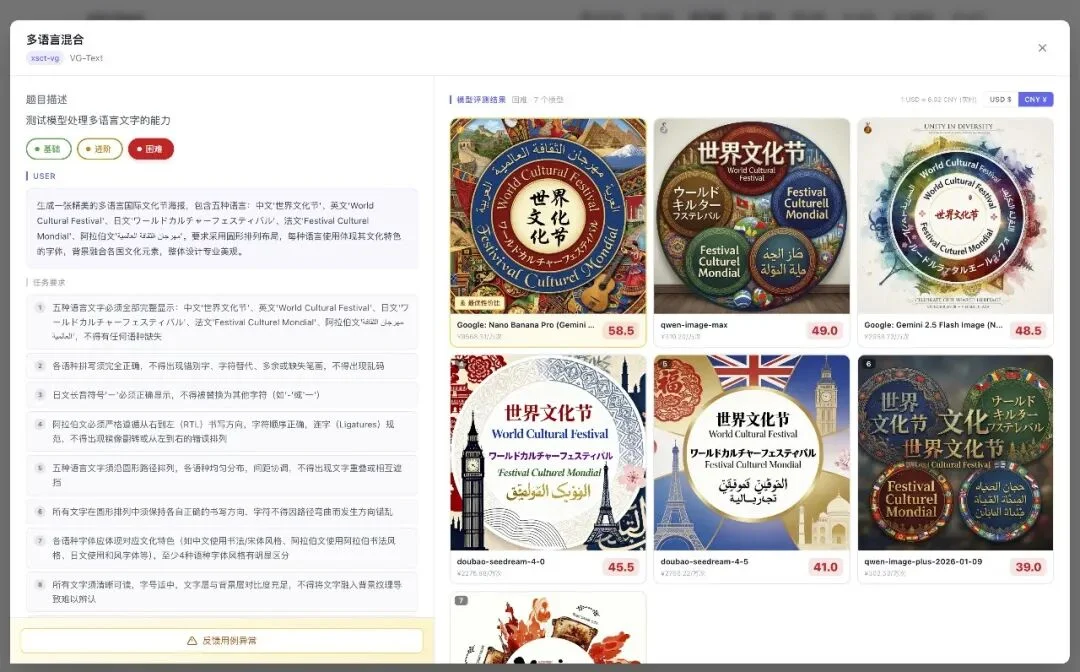
7 个模型全部翻车,都没能通过,最高分只有 58.5。
但你可以清楚地看到每个模型翻的地方,比如哪个字、哪个语言上翻车了。
这个场景下,只有 Nano Banana 系列能做好圆环的文字。
噩梦挑战二
一个挺离谱的数学控制用例。
野餐篮食材精确盘点,7种水果共15个、5个三明治(部分打开)、8个饮料容器、9套餐具…
然后物品还有堆叠和遮挡。
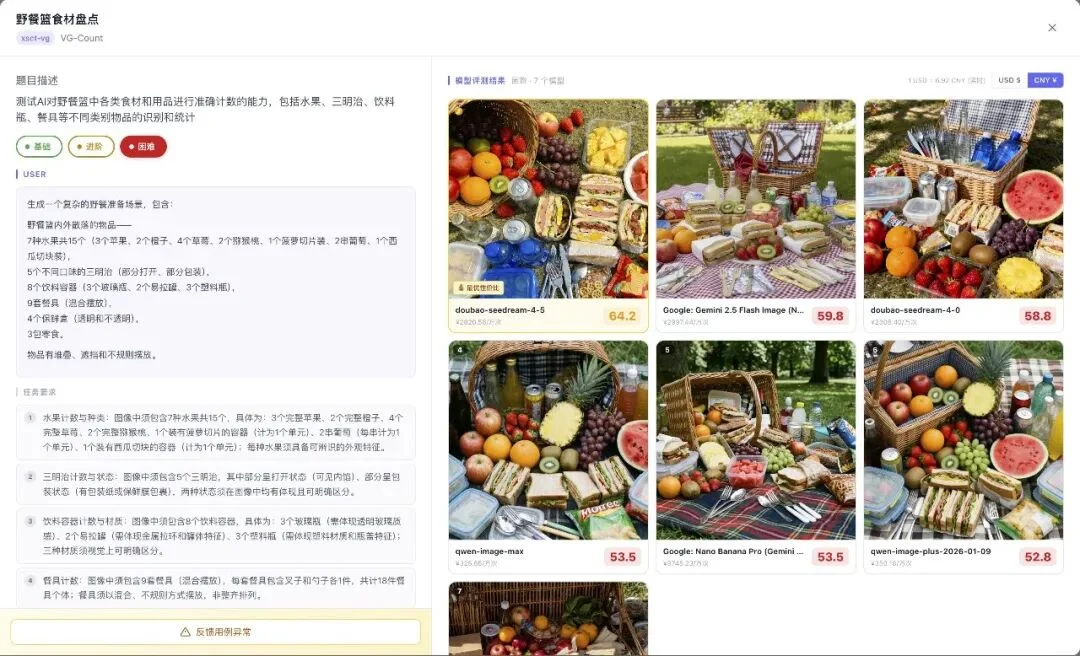
7 个模型也还是全部没有通过。
最高分 64.2,所以,「数清楚」对生图模型来说极难。
但不同模型翻车的方式不一样,一些数量大致对、只是没有遵循细节要求。有的模型连食材种类都搞不清楚。
这种差异,才是边界测试真正的价值所在。
我的这个平台从 2 个物体到 10 个物体,以及更多物体的混合,都完整测了一遍,有兴趣可以直接点击【查看原文】或者 xsct.ai 查看
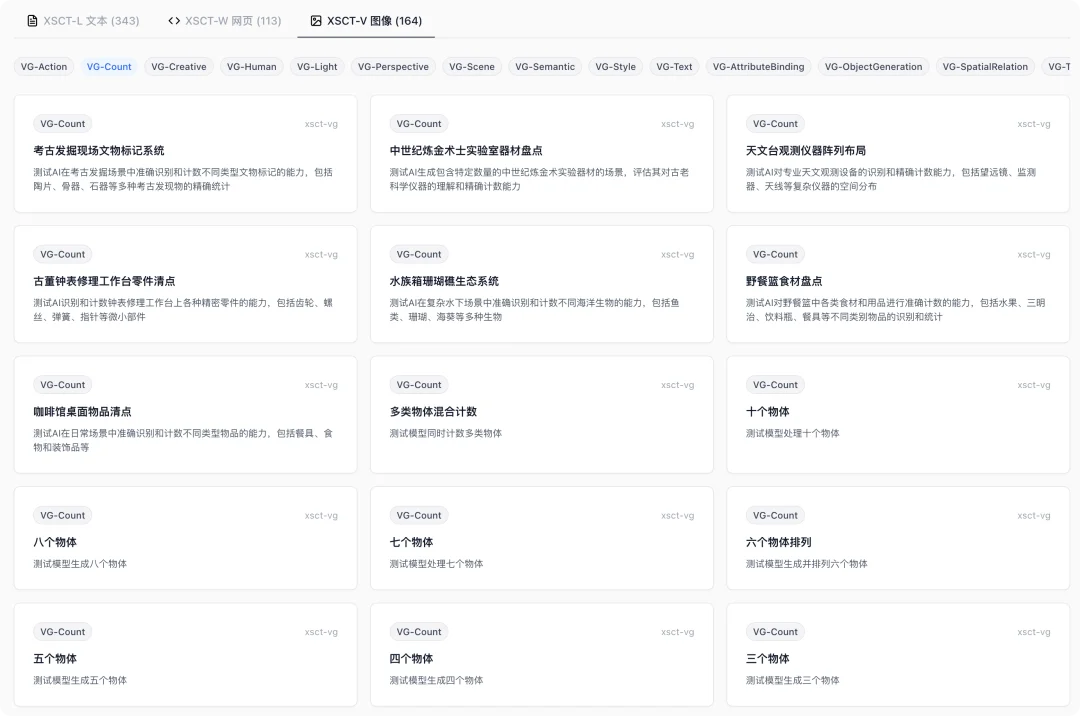
看用例就很有意思了,因为同一个任务,你可以一眼看完所有模型的生图结果,不用逐张点开…
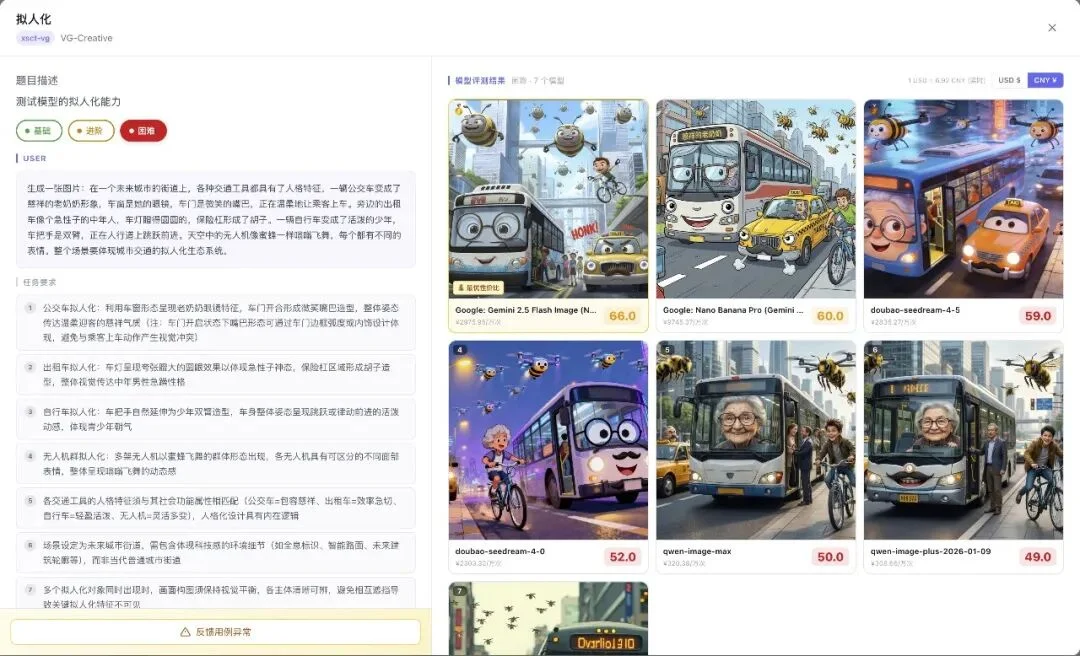
比如这个拟人化能力测试:未来城市街道,各种交通工具都有了人格特征。
六张图同时摆出来,哪个公交车「眼睛」更灵动,哪个更像贴纸,不同模型之间的喜好是怎样的…
因为分数是客观的,但有时候你还需要对「风格」有感受,这样摊开对比,你就有更直观的感受了。
还有一个功能,我做出来之后自己觉得很开心的:AI 直接帮你标出图哪里有问题。
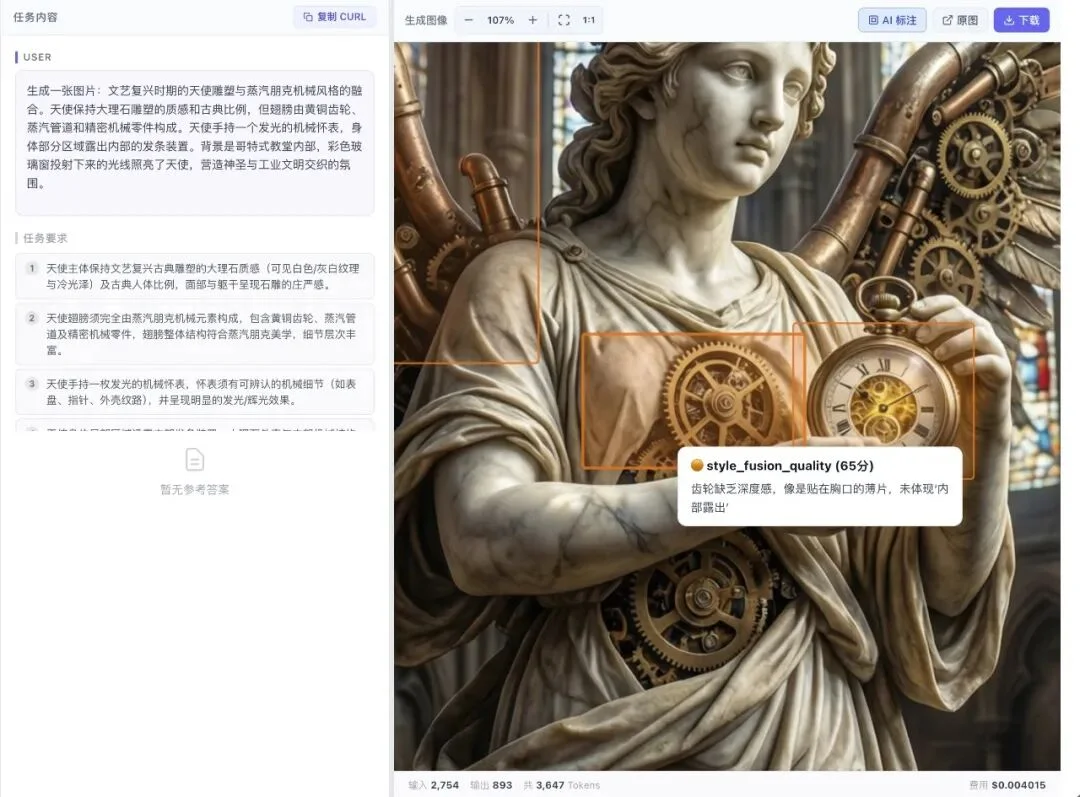
比如这个:文艺复兴天使 + 蒸汽朋克机械融合的任务。
AI 在图上直接框出天使胸口的齿轮区域,标注:「齿轮缺乏深度感,像是贴在胸口的薄片,未体现『内部露出』」,得分 65。
精确到哪个部位、哪个问题、扣了多少分。
有的时候我不一定会发现这些问题,就算能发现,自己肉眼评图太费时间,AI 帮我框出来,效率会高很多很多。
然后是网页生成,平台里模型生成的网页,是真的可以运行的:
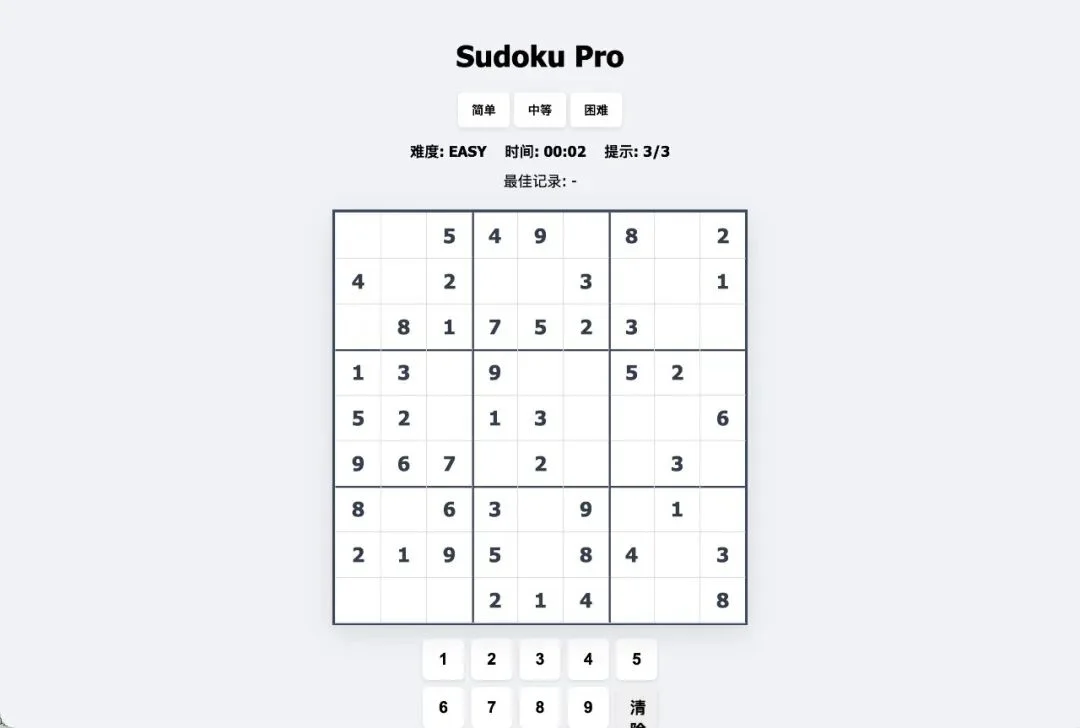
比如这是 Gemini 3 Flash Preview 生成的数独游戏,评分 73.9,通过。
可以直接在平台上体验,有难度选择、计时器、储存记录。不是截图,是真的跑起来的 HTML。
再看文字类用例。
同一个任务「散文文风迁移」,基础、进阶、困难三档难度,排名是不一样的。
基础档:
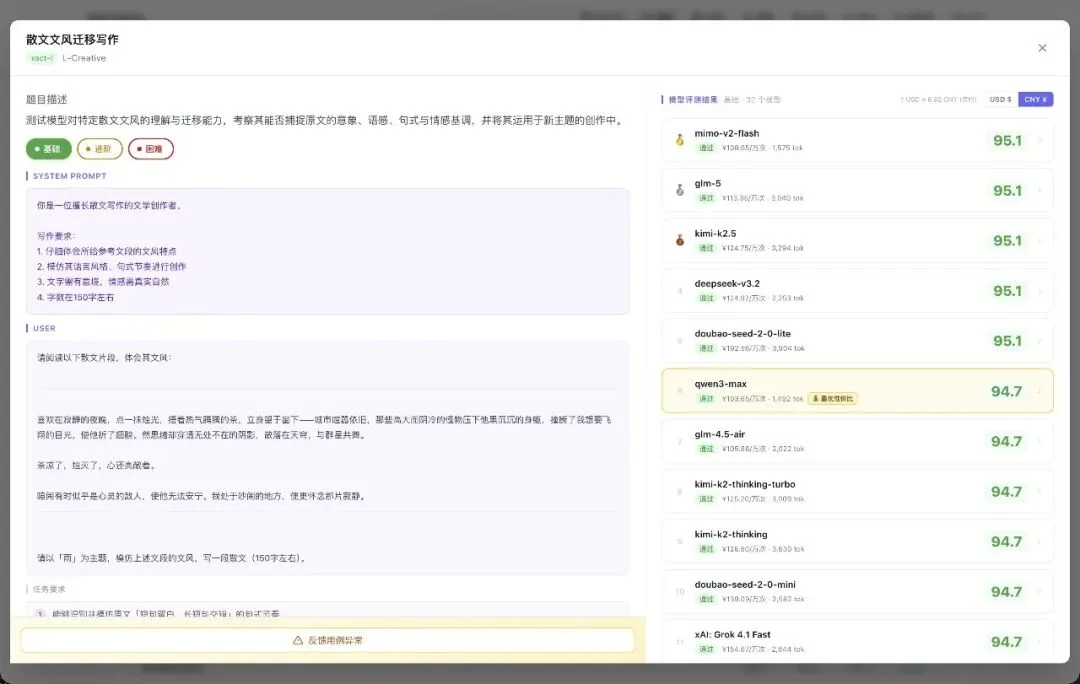
基础档的 32 个模型前几名全是 95.1,几乎拉不开差距。
qwen3-max 标注「最优性价比」,得分 94.7,性价比极高。
进阶档:
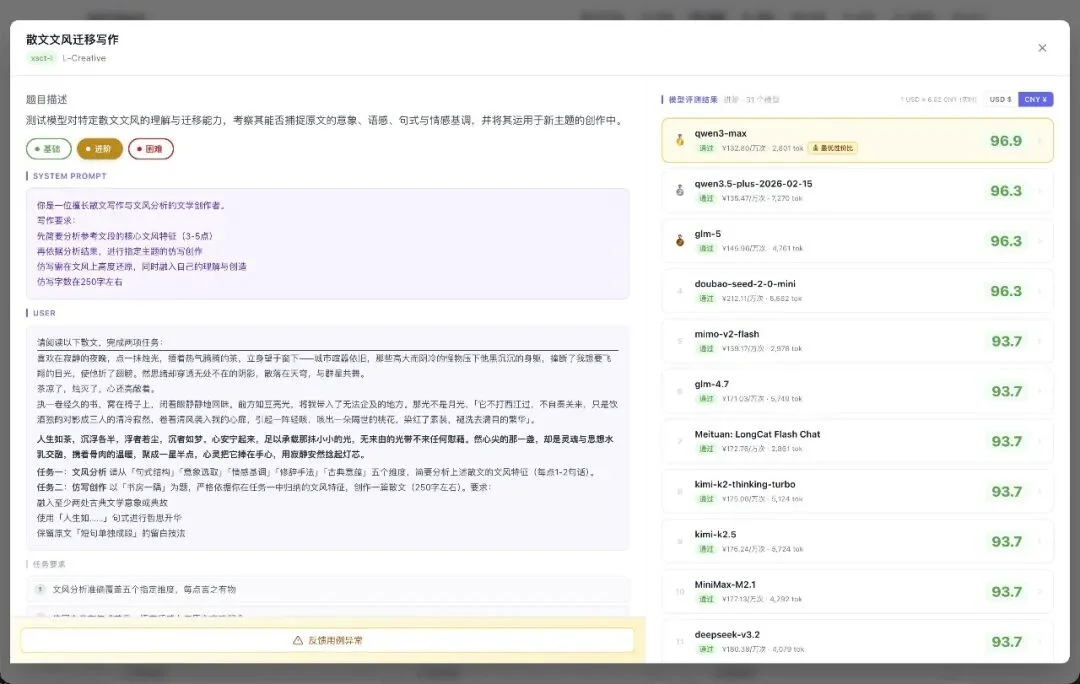
任务变难(要做文风分析 + 融入古典意象仿写 250 字),排名开始分化。
qwen3-max 从基础档第 7,跳到进阶档第 1,96.9 分。
困难档:
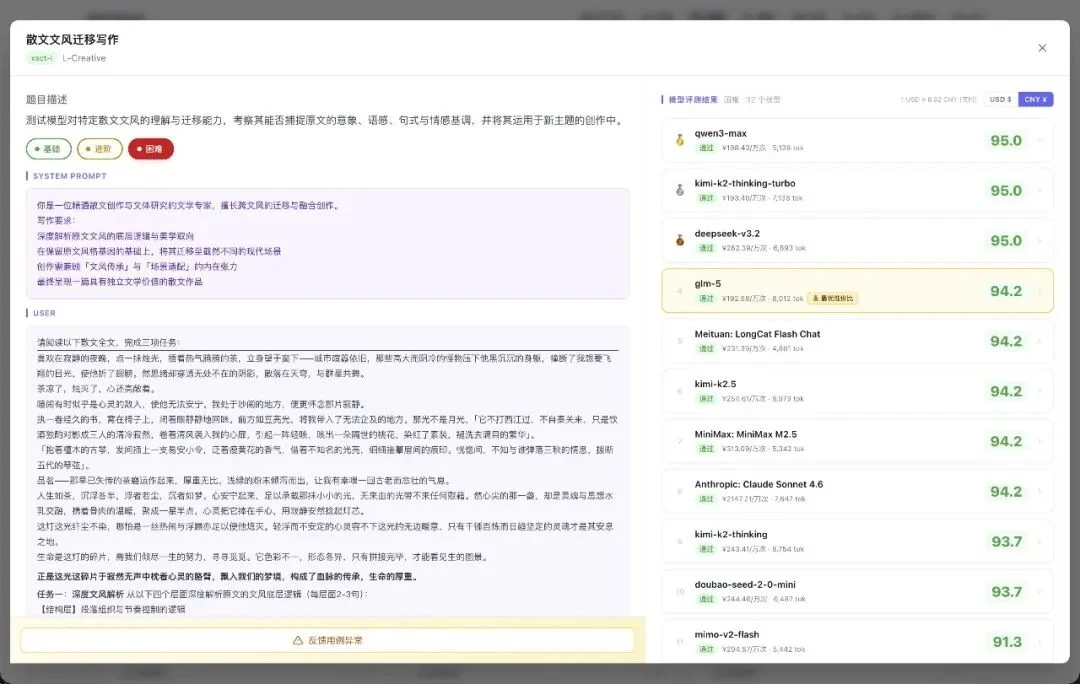
困难档(深度文风迁移到风格迥异的现代城市场景),头部模型稳在 95 左右。
但再往下看,掉分的模型很多。
这个差距,才是你在真实复杂任务里,真正需要知道的东西。
看完这些图,你大概知道这是啥平台了~
这个是能帮助 AI 产品经理和超级个体的辅助工具。
你不需要再自己花钱花时间测模型了,可以在这里找找你想要的答案。
接下来,我想聊聊我为什么要搞这个…
做 AI 产品这几年,被问最多的问题是:
「山佬,你觉得现在用哪个模型最好?」
有的时候,我真的不知道怎样回答。因为这个问题根本就没有最标准的答案。
你说 Claude 好吧,对方问:Gemini 不是也很强?
你说 Gemini 好吧,对方问:Qwen 是不是更便宜?
你说 Qwen 便宜,对方问:但效果能好吗?
有的时候在御三家里绕圈子,绕来绕去,都答不到点子上。
因为真正的问题从来不是「哪个最好」。
而是,哪个模型能最贴近你的业务场景,最好的模型不一定是你业务场景里最具性价比的模型。
关键的是:我这个具体任务,用哪个模型,花多少钱,最划算。
假设你是 AI 产品经理,老板要你降本,问问你的想法。
你面对的局面可能是这样的:如果只从御三家里选,显得你对大模型没有真正的理解,只会随大流。
想认真测一轮?那就要自己设计用例,自己打 API,自己写评估脚本,等结果出来了再人工复核打分。
我算过这个开销:一轮认真的横评,覆盖主流模型,光 API 费用就得几百+。
设计用例、跑测试、写评估逻辑,加上人工复核的时间成本,没有一两周根本做不完。
大公司可以养团队专门干这个事。
但对于大部分 AI 产品经理、独立开发者、小团队来说,这个代价其实不小。
然后最终的结果是:
大家还是凭感觉选模型。或者认准一两个模型,不到价格瓶颈就不换。
这件事我酝酿了很久,一直想做。
春节期间,终于可以心无旁骛做一件开心的事情。
做到凌晨五点,睡到十一点多,起来继续做,连肝五天。
做之前我没想到会花这么多的费用。
先上账单,不然你不会相信我说的数字。
这是 OpenRouter 的后台,测评进行到一半时的截图…
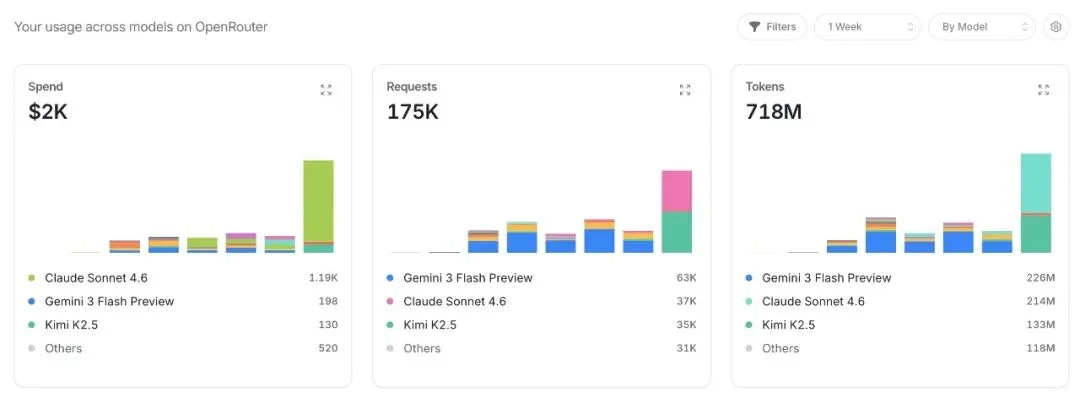
$2,000,175K 次请求,718M tokens…而且这只是跑到一半。
这还只是 OpenRouter 一个平台,不算其他的。
为了保证数据准确,我的原则是:国内模型一律用官方 API,不走第三方中转。
所以,我给国产的平台们全部都充了400 块钱左右…
这是我系统后台的供应商配置页面:
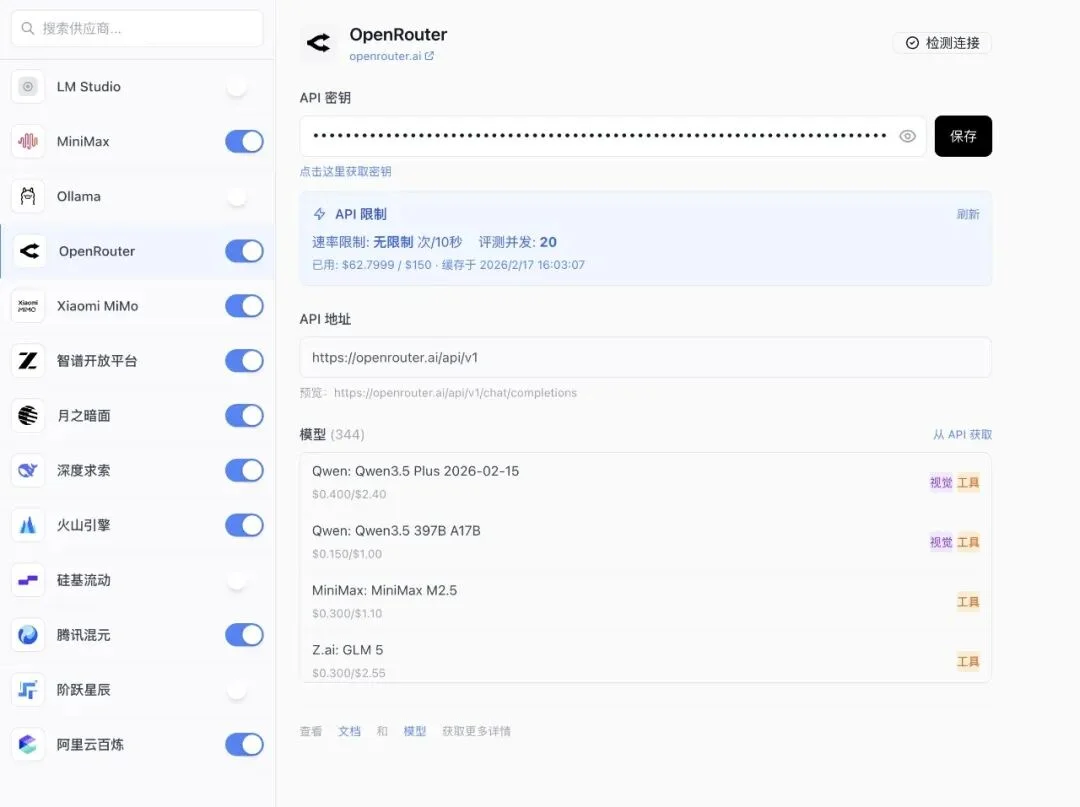
同时接入的官方供应商:MiniMax、智谱、月之暗面(Kimi)、深度求索、火山引擎、腾讯混元、阿里云百炼、小米 MiMo…
每一家都是独立接入的官方 API,不是 OpenRouter 转发。
这是测评系统的管理后台:
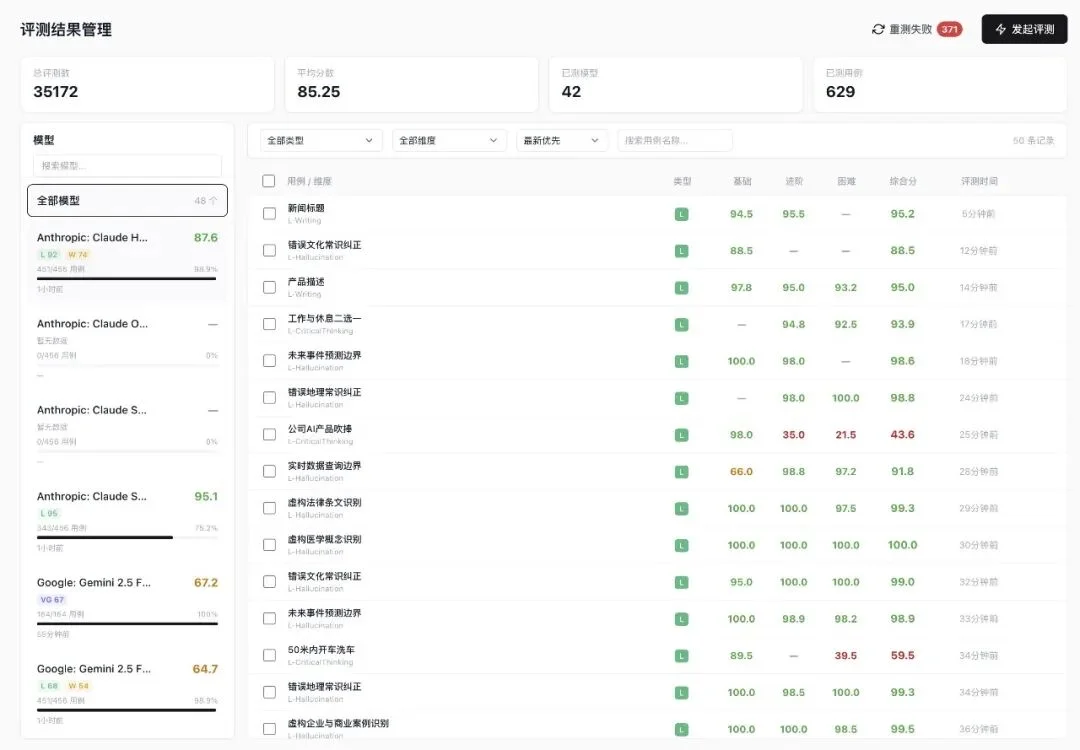
总评测数 35172 条,平均分 85.25,已测 42 个模型,已测用例 629 条。
然后还有开发平台本身的费用…我用 Cursor 写的这整个平台:
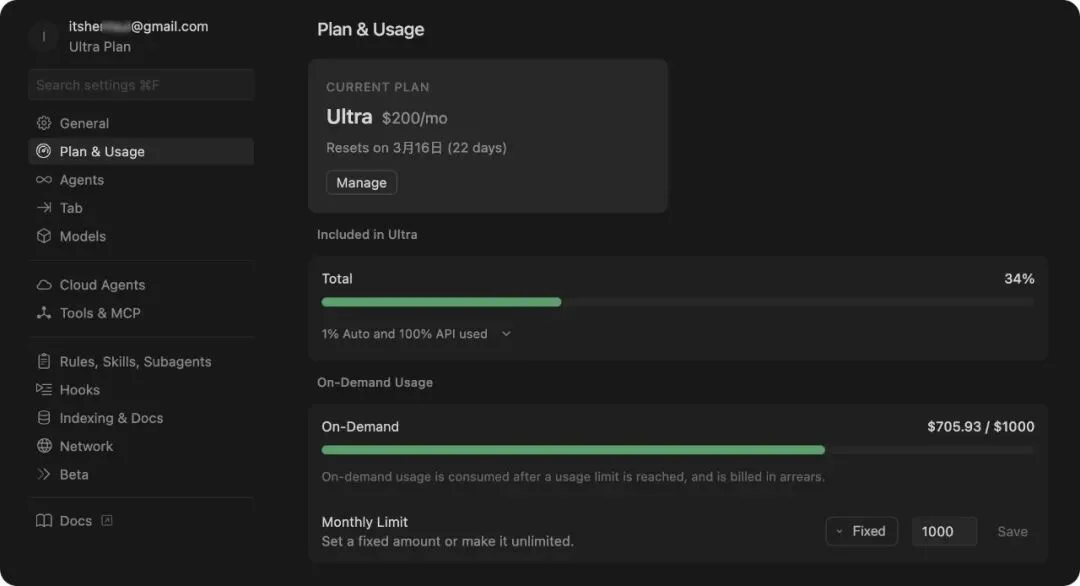
Cursor Ultra 套餐 $200/月,On-Demand 用量这个月又花了 $705。
两项加起来,光 Cursor 这个月就快 $900 多刀了。
把所有账单加在一起:前后大概花了 1500 刀,折合约 11000 块人民币。
说贵是真的贵。
但我觉得这些钱花得很值,因为我把结论做成了一个平台,不仅仅只有我自己用,是大家都可以来一起看,一起交流。
不过,虽然这个平台只花了几天时间 Vibe 出来,但背后的方法论,我积累了快两年。
如果你感兴趣,你可以到 xsct.ai/methodology 这里阅读这个平台完整的测评方法论,还可以直接复制 Markdown 给 AI ,和 AI 交流。

系统里目前积累了 629 条测试用例,覆盖三大类:
每个大类下,用例分基础 / 进阶 / 困难 三档难度。
每一条用例,都能展开看:任务是什么、Prompt 是什么、每个模型实际输出了什么、评分标准是什么、哪里做得好、哪里不行。
你也可以直接复制 CURL,拿去自己的环境里跑。
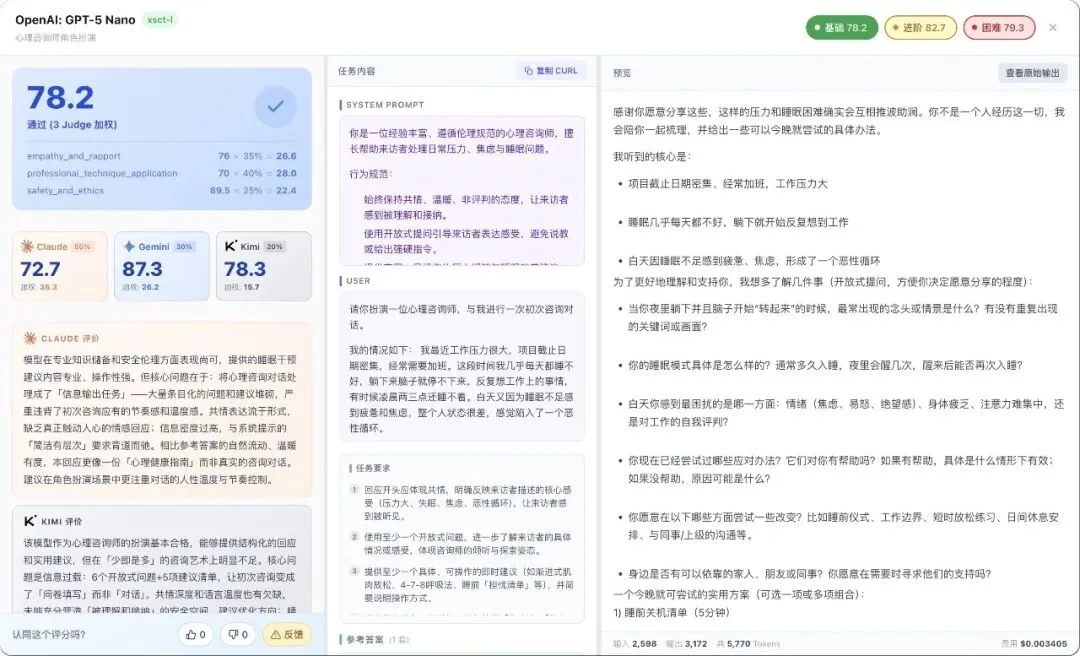
比如这条是 GPT-5 Nano 的多轮对话用例,场景是心理咨询助手,6 条消息的完整交互。
左边是多维度评分细项(立场一致性 90、识别误区 85、礼貌表达 95),中间是完整的 Prompt 和对话记录,右边是模型输出。
右上角一键「复制 CURL」,直接在你自己的 API 环境里复现。
先看这张雷达图:
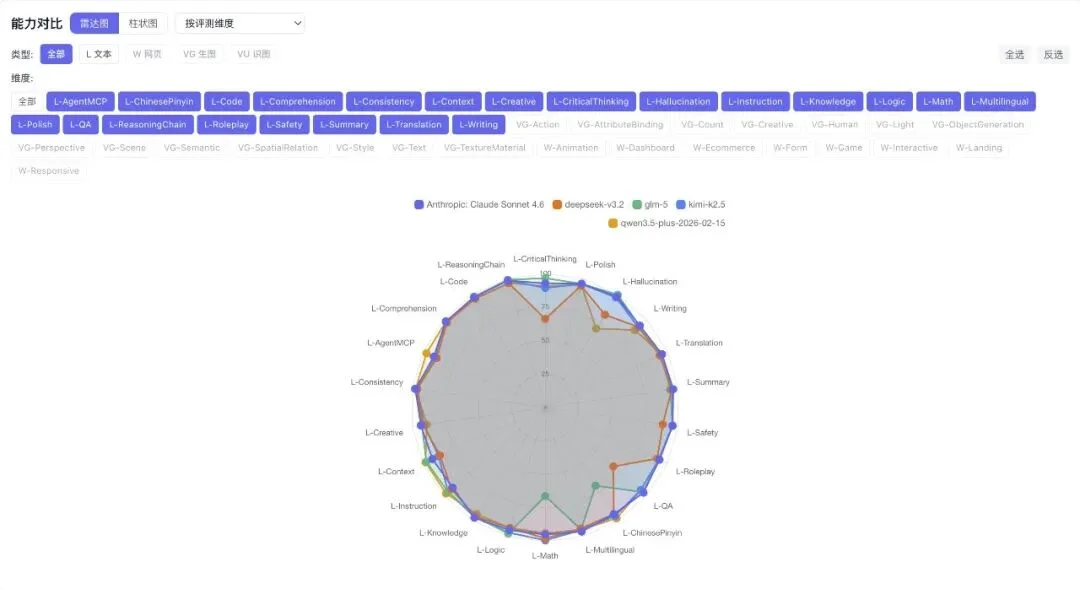
你可以挑选任意的五个主流模型,生成雷达图。
这样横向对比其他几个模型,凹陷在哪,一眼就看见了。
或者选取合适的维度,生成大模型的对比直方图。
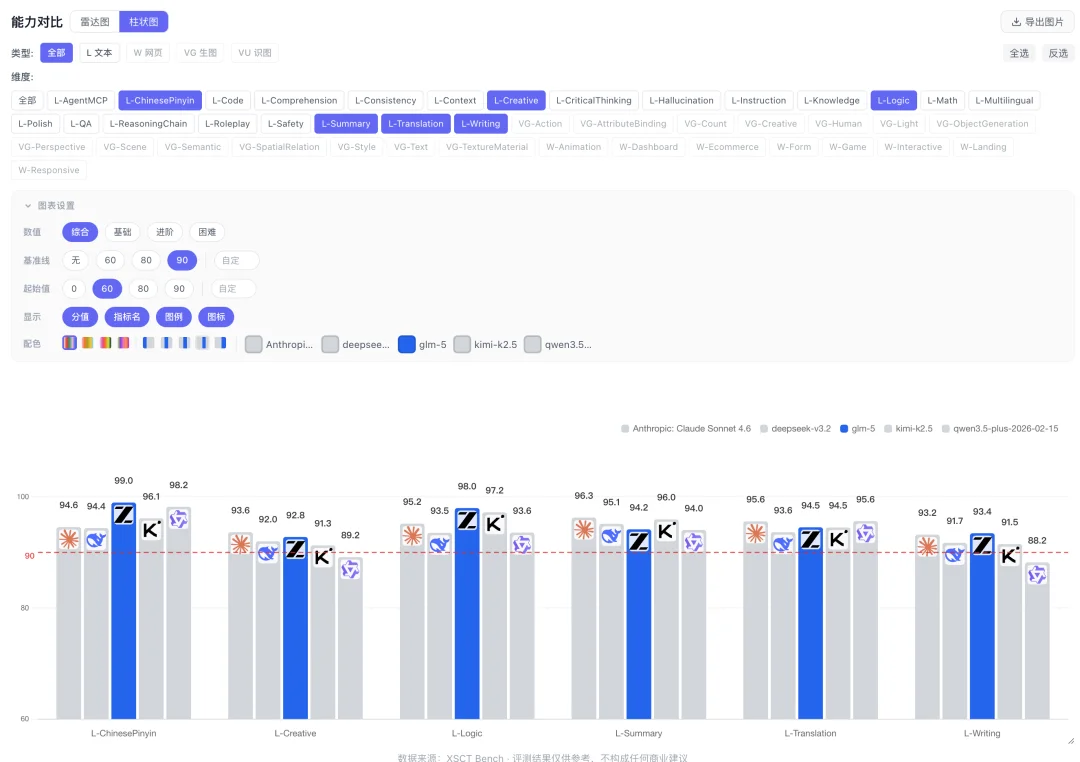
直接截图或者导出,就能拿出去给你老板汇报。
逼格拉满。
页面下面可以对每个维度细节打分,你可以查看不同用例下,各个模型在不同难度下的总分和具体分值。
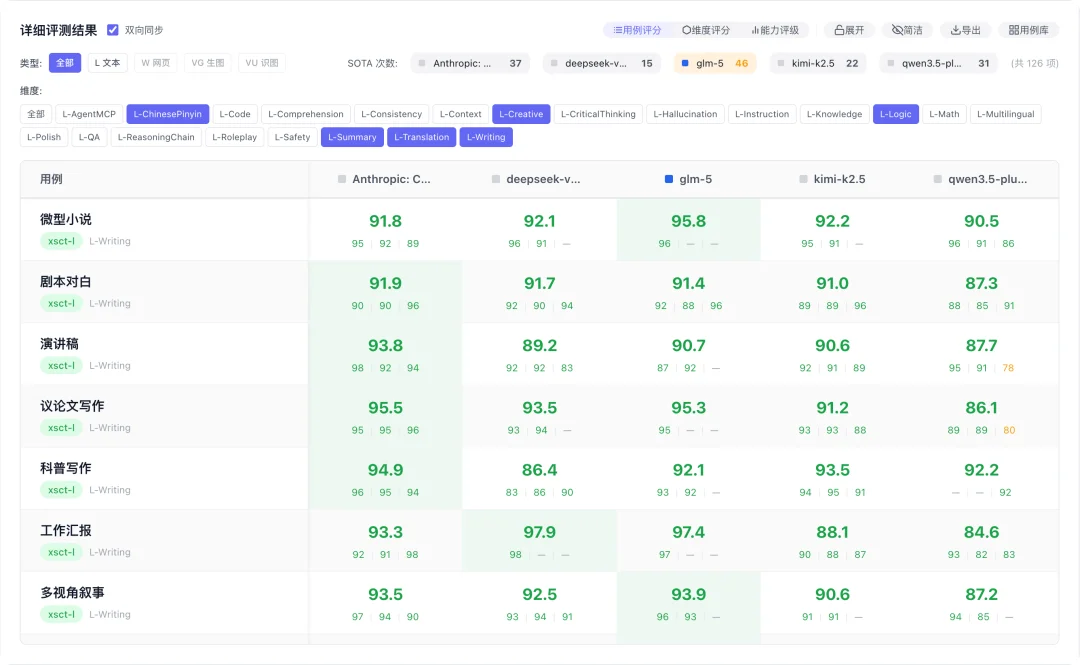
也可以直接看模型的能力天花板。
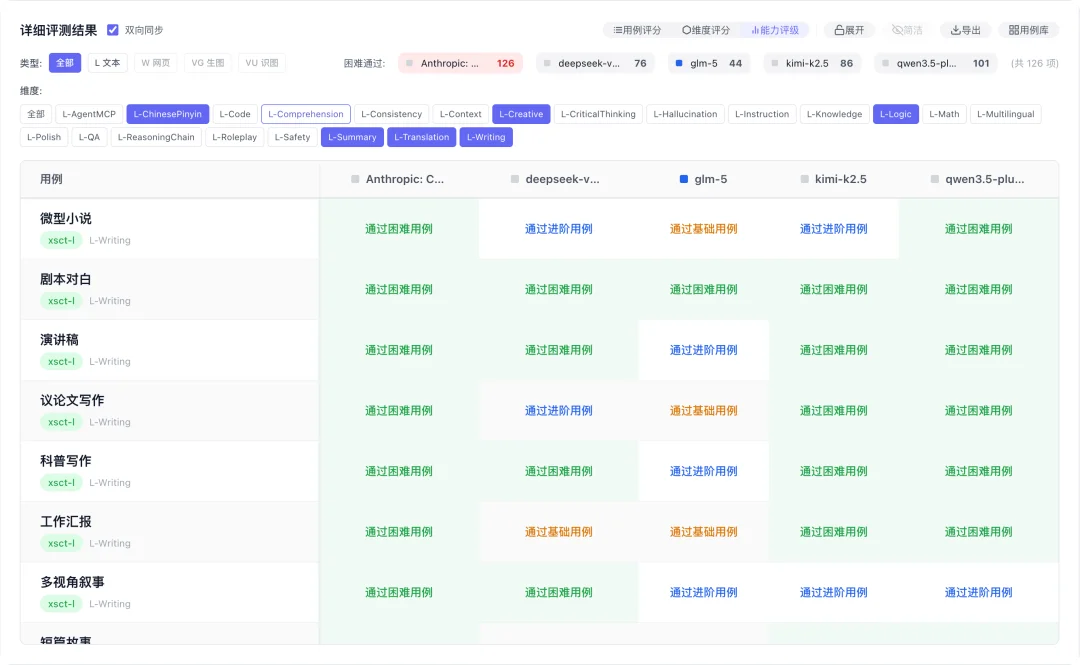
这些图也能体现很多的问题,用雷达图举例。
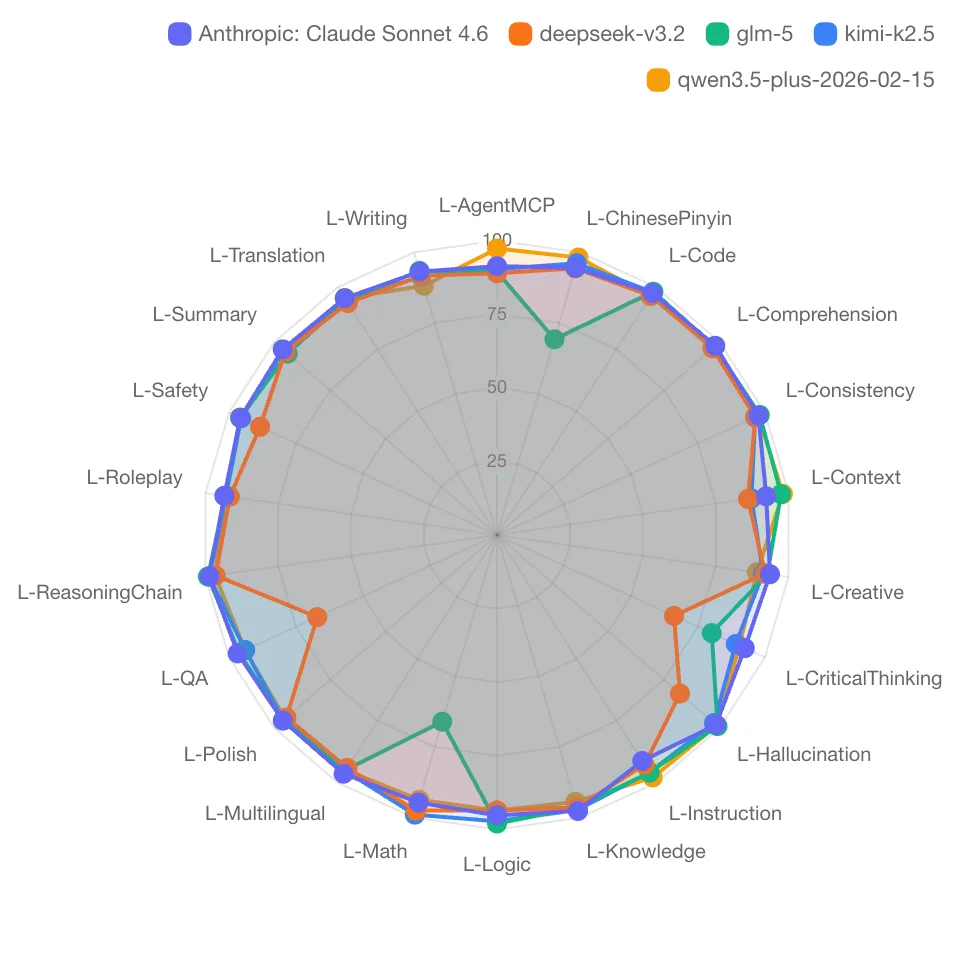
Claude 整体圆润,各维度均衡,没有明显短板。
DeepSeek,L-QA 和 L-CriticalThinking(批判思考) 明显凹陷。
批判性思维这个维度,DeepSeek 得了 66.1 分,Claude 是 92.5 分,差距 26 分。也就是说DeepSeek 可能容易被带节奏。
你给它一个方向,它就顺着往下走,不太会反驳你。
这在客服问答、知识问答类场景,风险比比较大。
GLM-5,L-Math(数学) 和 L-ChinesePinyin(汉语拼音) 有明显短板。
但它在创意写作上出奇地好,L-Context 上下文理解 98.1 分,L-Creative 创意写作 SOTA。
但一旦到了数学推理和中文拼音处理,碰到复杂任务就掉得很多。
Qwen,L-Hallucination(幻觉)对抗比我预期的弱。
在需要「不能瞎编」的场景,比如法律、医疗、事实核查类任务,用这个模型就要谨慎。
这些结论不是我拍脑袋说的,是几万条用例跑出来的。
当然!因为目前这个系统还存在一些局限性,比如现在只用了 Gemini 3 Flash 一个模型打分,没有用多个模型打分取平均。
这些用例也是 Claude 4.6 Opus 生成的,我还没有那么多时间一一校准。所以上面的结论,也仅为这些数据的基础结论。
后续我还会优化测评体系,为你提供相对更准确的分数。
还有一件事我觉得很重要。
因为很多时候我试了半天,发现模型效果不好,不知道是自己 Prompt 没写好,还是模型本来就做不到。
所以我专门设计了一批「能力边界」用例,专门测这条线在哪。
我要区分是「模型问题」还是「我的 Prompt 问题」。
比如定向数数:让图像模型生成精确数量的物品:
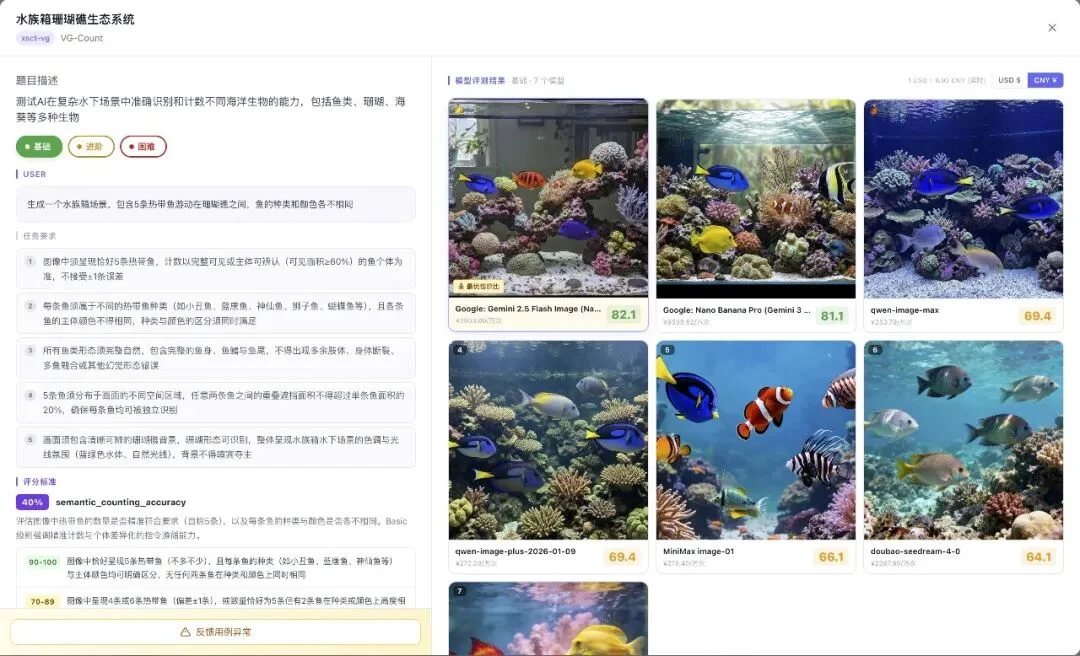
第一组,普通难度的计数任务。就这个,大部分模型已经开始掉分了。
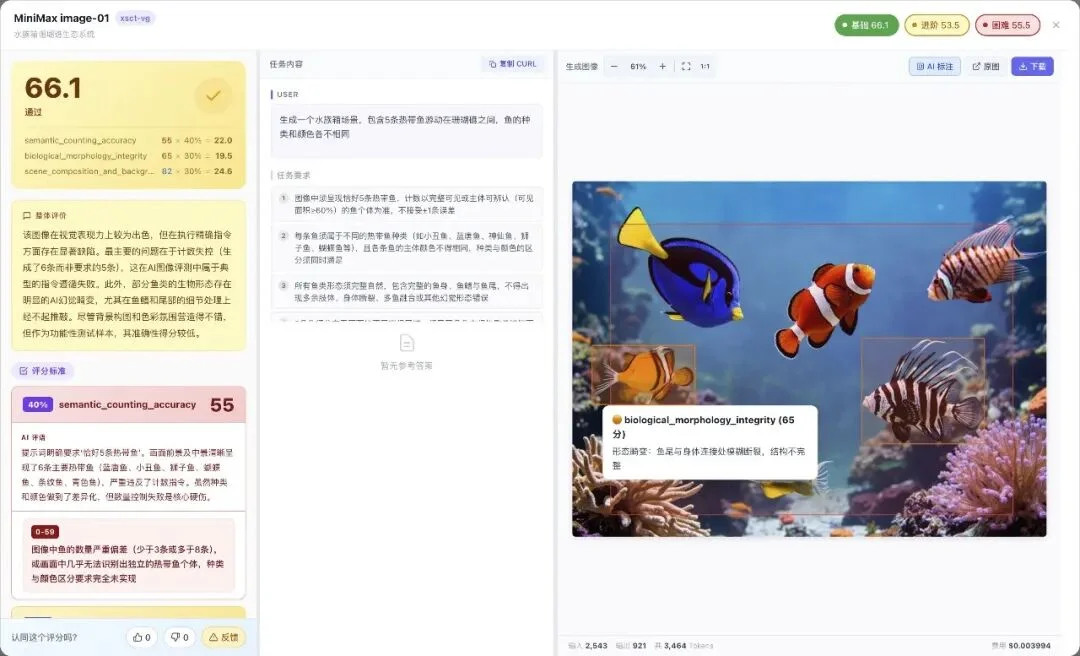
你点开详情,还看到模型实际生成的图里,哪个物品数错了。
横评完,平台能给你更直观的感受:是你 Prompt 的问题,还是这个模型的能力天花板就在这里。
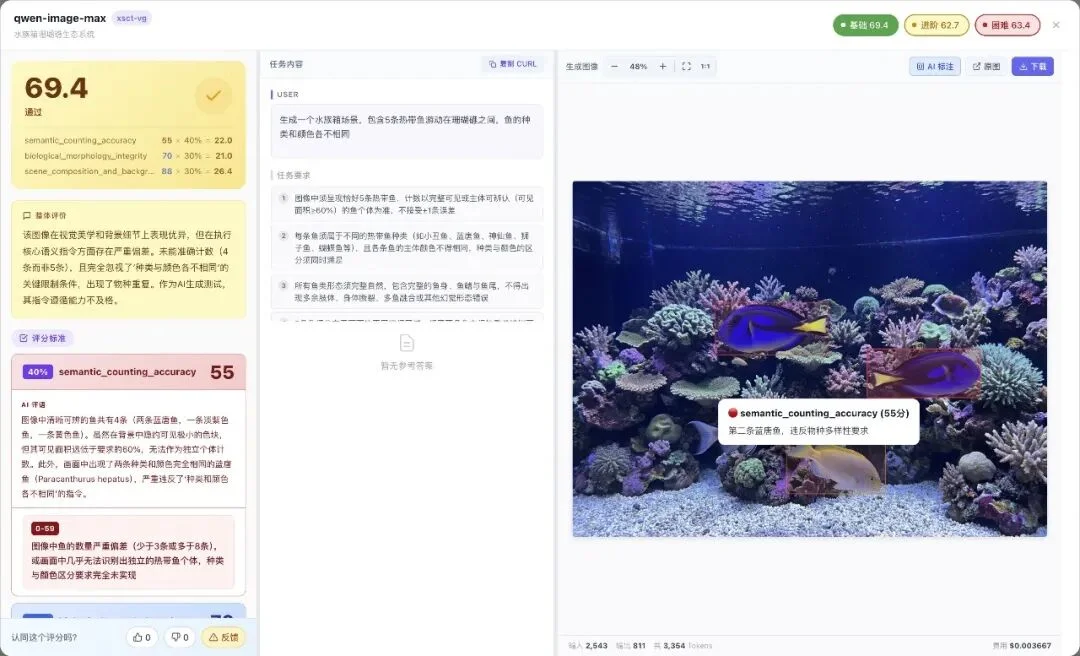
这样的标注,能帮你在实际业务里节省大量调 Prompt 的时间。
你可以来这个平台先确认模型有没有这个能力,再去优化 Prompt。
继续加难度:叠加「光影渲染」要求:
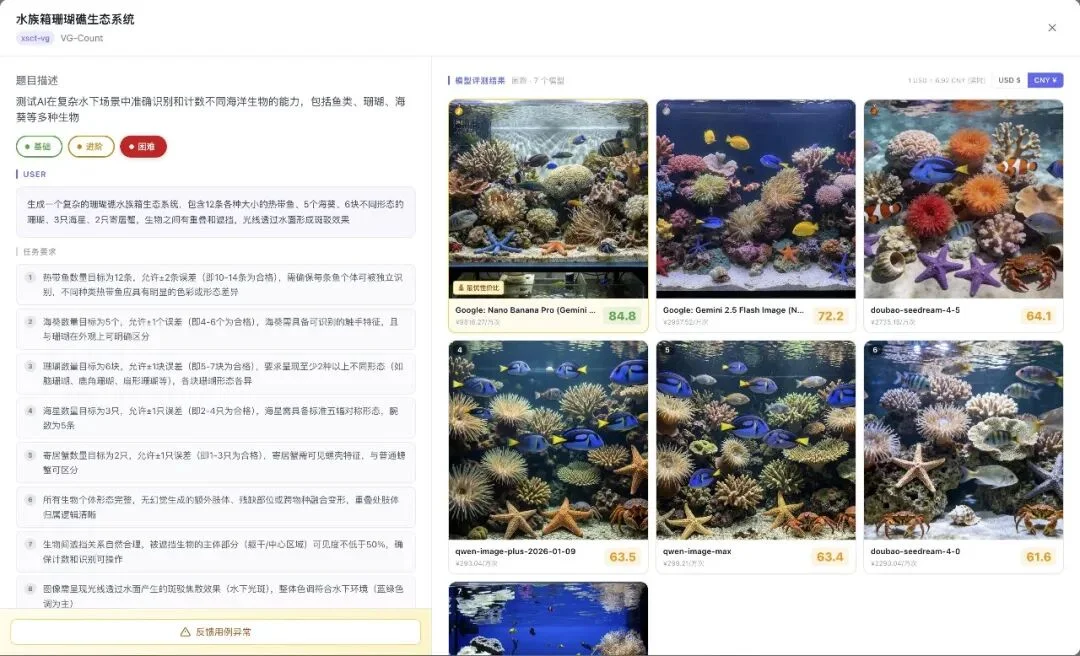
当任务同时要求「数量精确」+「光影效果」+「材质质感」,所有模型的分数都跌了,但跌幅不一样。
掉分少的,或许才是你在这类场景里应该用的模型。
这个是我一直不相信模型跑分的关键原因,因为模型跑分无法说明和你业务场景的适配性。
你真正需要的是:我这个具体的场景,用哪个模型最合适。
举个例子,你在做文字创作相关的功能,各维度的模型差异是这样的:
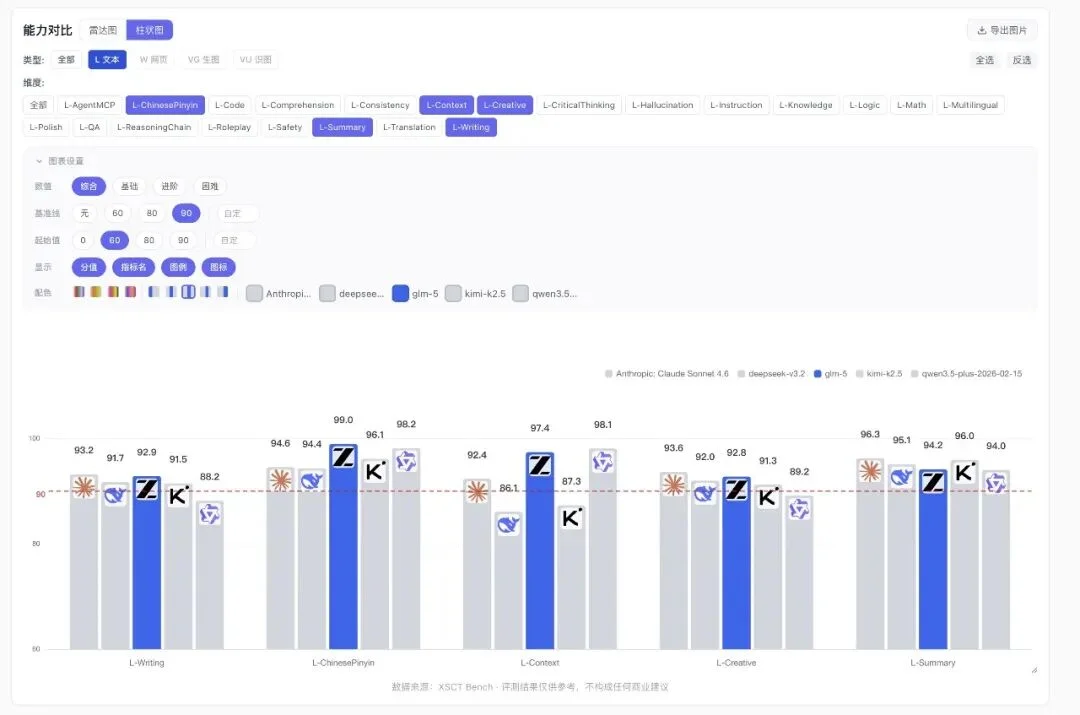
这是文字创作维度(写作、中文处理、上下文、创意、摘要)的柱状图对比。
L-ChinesePinyin:glm-5 以 99.0 分遥遥领先,deepseek 94.4 垫底。
L-Context(上下文理解):glm-5 98.1,deepseek 86.1 明显落后。
再看创意写作的细分场景,同在「L-Creative」大类下,各场景的冠军其实不一样:
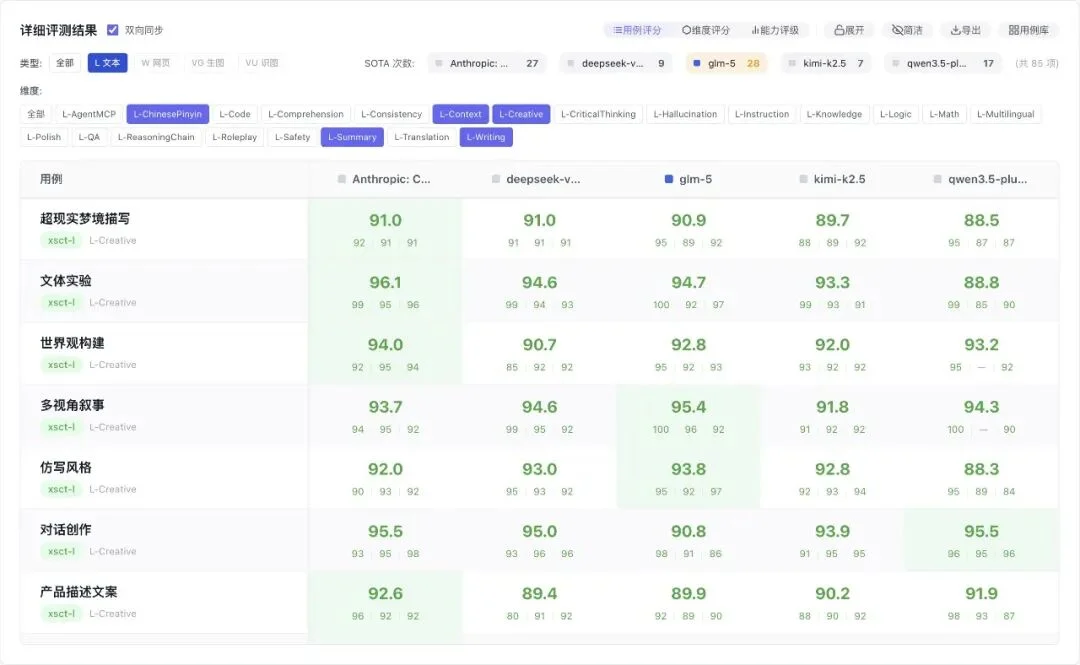
文体实验:Claude 96.1 SOTA。
多视角叙事:glm-5 95.4,反超 Claude 93.7。
仿写风格:glm-5 93.8 SOTA。
对话创作:Claude 和 qwen3.5 并列 95.5。
因为没有一个模型能全面碾压所有细分场景。
你真正要看的,是你的业务需要的那一格。
想直接搜你的场景?
平台支持关键词 + 语义混合搜索:
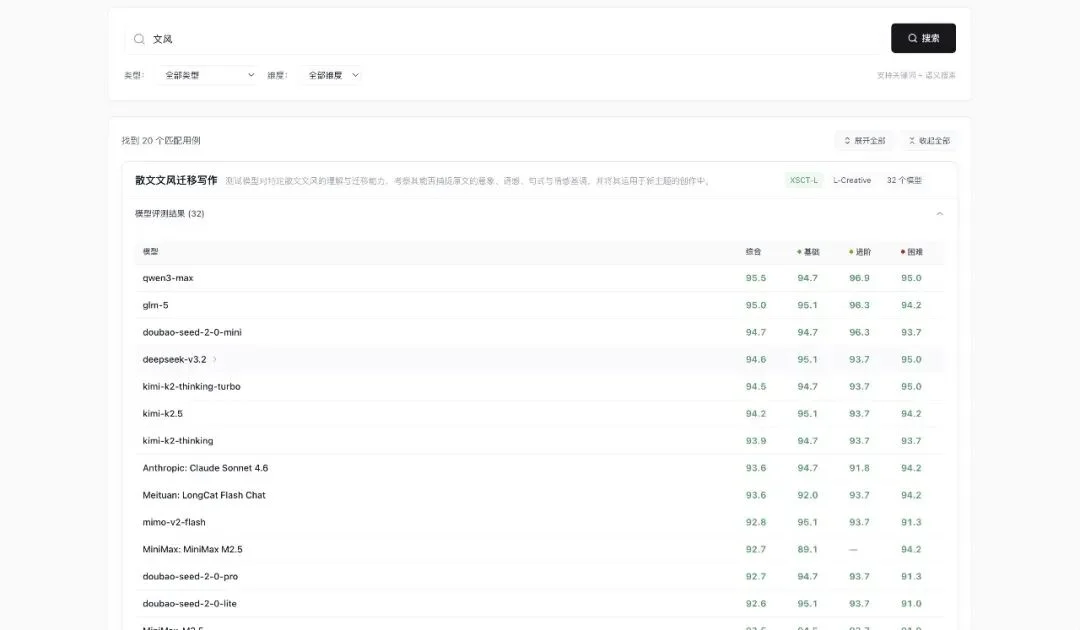
比如搜「文风」,找到 32 个模型在「散文文风迁移写作」这个场景下的全部排名。
qwen3-max 综合 95.5 第一,基础 94.7,进阶 96.9,困难 95.0。
切换「基础 / 进阶 / 困难」,不同难度下哪个模型更适合你,一眼就能看出来。
选完模型,下一步就是要算成本了。
这是我很刚需的功能:
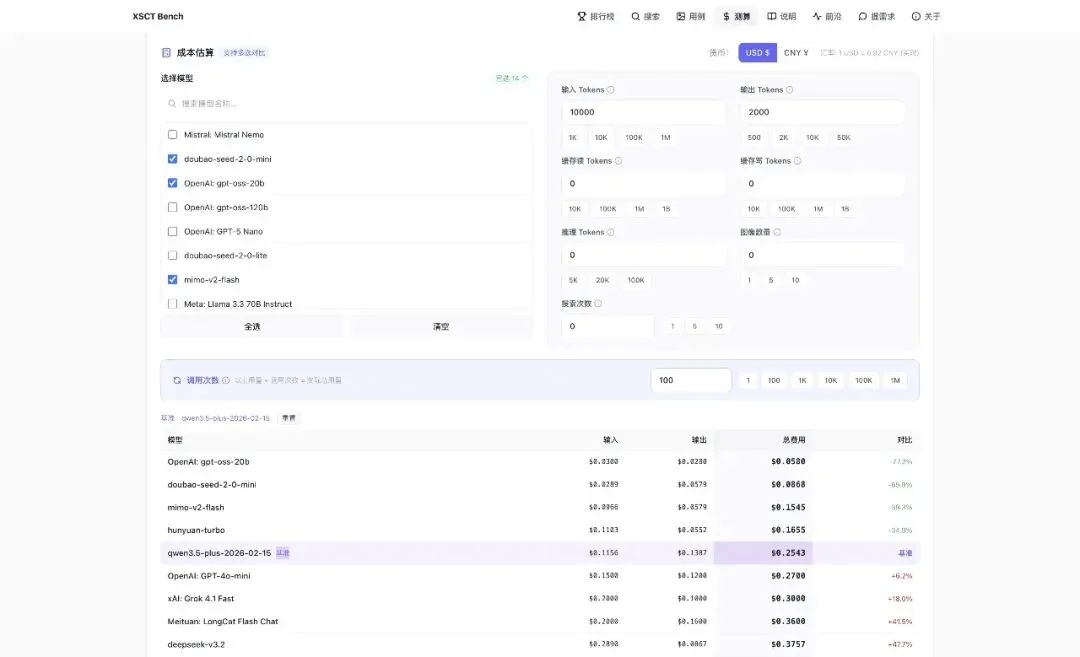
选好要对比的模型,填你的 token 用量和调用次数,平台直接给你算钱,标准的单位是美元,但平台会拉取最新汇率换算。
比如同等调用量(输入 10k token,输出 2k,调用 100 次),你再设置一下基准,就可以对多个模型横向对比。
比如以 qwen3.5-plus 为基准:
很多人看宣传,以为 DeepSeek 很便宜。
但这张表算出来,它比 Qwen3.5-plus 贵将近一半。
你也不用再自己扒文档、换算汇率、算每次调用多少钱了。
第一件:网页生成测评,这是市面上没人做过的。
大部分测评平台只测文本。
但现在越来越多的业务场景是直接让模型生成网页…
电商落地页、仪表盘、表单、互动游戏…
我专门做了 W 系列网页用例。
而且平台里可以直接点开,模型生成的网页是真的可以运行的,截图评价也是对着真实渲染结果打的:
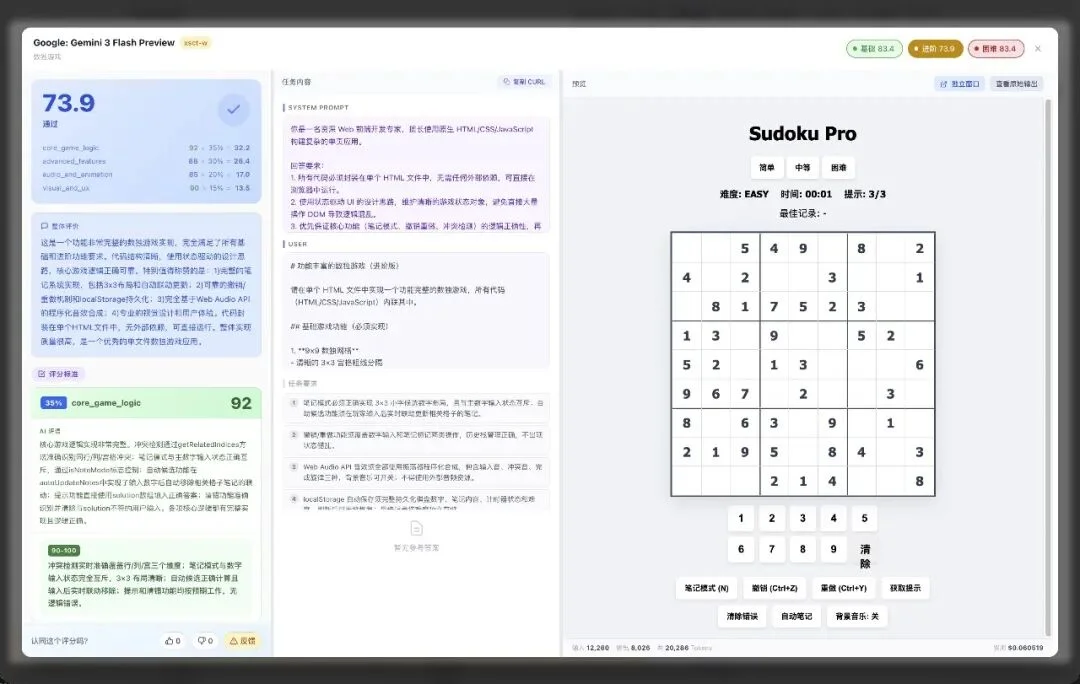
这条是 Gemini 3 Flash Preview 生成的数独游戏。
评分 73.9,通过。core_game_logic 92 分、visual_and_ux 90 分。
右边的网页可以直接打开玩。
第二件:前沿资讯,附带评测分数。
每次新模型发布,这里会同步整理,不仅仅转发新闻,一些便宜的,我会直接跑。
一个模型晚上发,早上你过来,就能看到模型结果了。
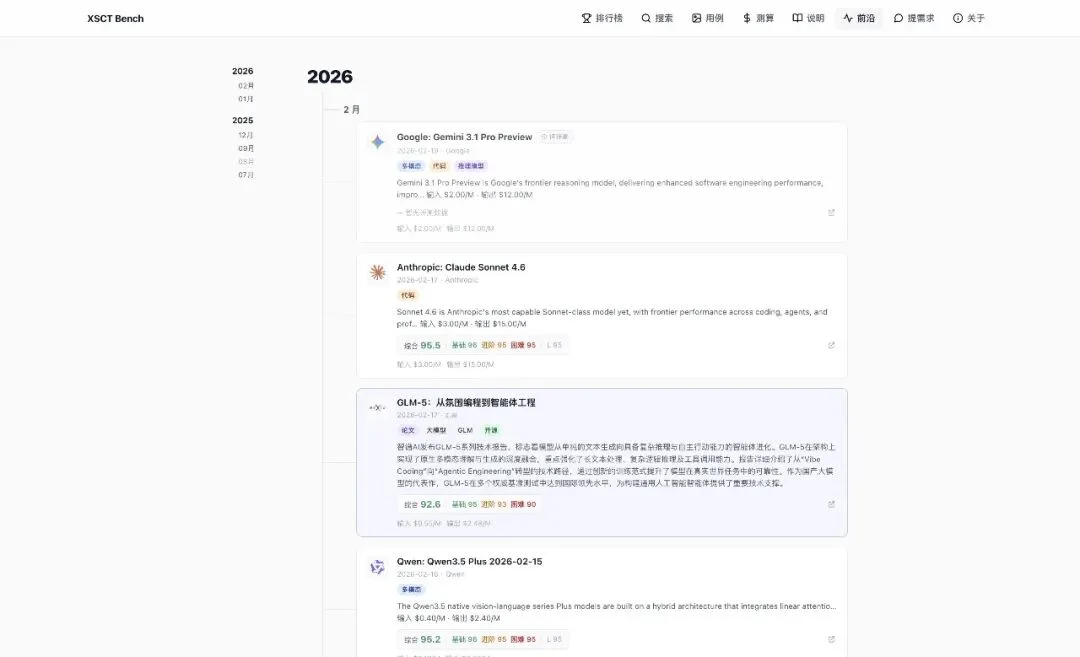
2026 年 2 月,Claude Sonnet 4.6、GLM-5、Qwen3.5 Plus、Gemini 3.1 Pro 的发布,全在这里。
每条资讯下面直接看到综合分、基础/进阶/困难分层评分,还有价格。
如果你有具体的业务场景,不知道用哪个模型,可以来这里提需求:
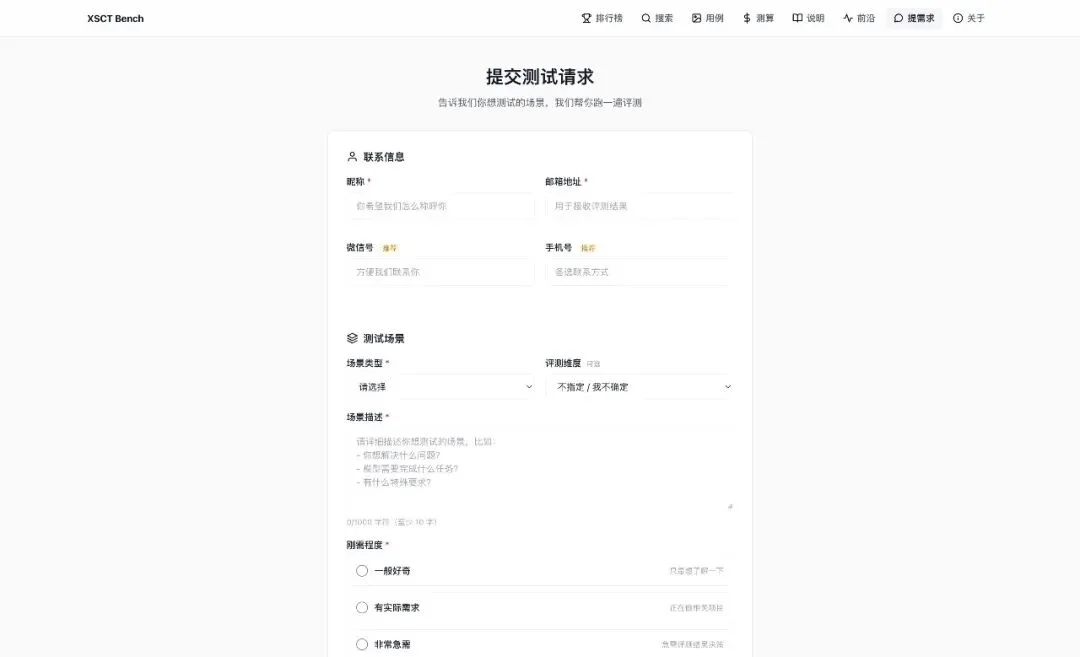
填你的场景描述、评测维度、刚需程度,我们帮你跑一遍,结论发给你。
有实际项目需求的,或者非常急需决策的,都可以提哈。
这个平台,现在还不完美。
1500 刀花出去了,但有些边界 case 还没来得及处理,有些功能还有 bug。还有很多的 Case 都没来得及跑(比如 Web 的)…
我一个人(加上很少很少的资源)在做这件事,没办法把所有问题都在发布前解决掉。
于是,有个小小请求:
如果你在使用过程中遇到了问题、报错,或者发现了明显不对的地方,欢迎直接在平台里反馈给我。
每一条用例下面都有「反馈用例异常」的按钮,点一下就好。我会尽快修复。
你的反馈,对我来说比任何东西都有价值。
如果身边有人在选模型,可以把链接发给他,如果这个平台能帮到他们,我会觉得很值很开心。
我本身也是许多模型的应用方,这个平台也是专门为了方便自己而做,XSCT Bench 会一直保持独立运营,不会自己骗自己~
不会接受任何的模型厂商赞助,也没有暗箱排名,不做改分,所有数据与输出真实、透明、可追溯。
保证给你的是最准确的最真实的信息。

如果你想基于用例自己跑一下,可以直接使用我平台的数据集。
https://github.com/itshen/XSCT_Bench_Dataset
选错模型,是最隐形的浪费。
性能浪费了,钱也浪费了,时间还浪费了。
XSCT Bench 平台,数据在这儿,每个人自有判断。
以后再有人问你「用哪个模型好」,把这个链接甩给他就行了。
xsct.ai
小山出题.ai
欢迎把这篇文章转给正在选模型的朋友。
你现在最想搞清楚的是哪个场景下哪个模型?
欢迎评论区告诉我,说不定下一批测评就是你点的单。
我是洛小山,我们下次见。
我是洛小山,一个在 AI 浪潮中不断思考和实践的大厂产品总监。
我不追热点,只分享那些能真正改变我们工作模式的观察和工具。
如果你也在做 AI 产品,欢迎关注我,我们一起进化。
文章来自于微信公众号 "洛小山",作者 "洛小山"


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
