# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
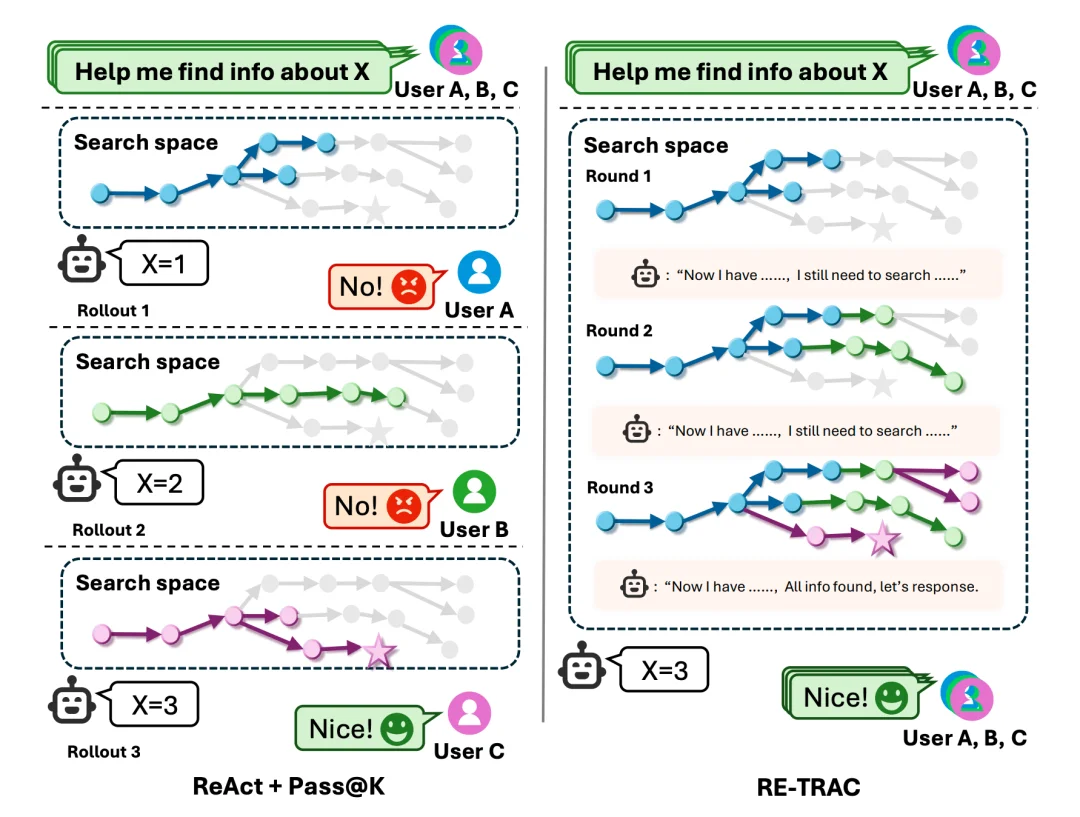
想象一下,你让 AI 助手结合搜索工具探索一个复杂问题。它第一次探索时走错了方向,但第二次、第三次,它依然重复同样的错误探索路径。虽然你可能可以从最终得到的多次探索结果中挑选出一个勉强满意的答案,但是这既低效,也需要人工干预。这就是当前大多数深度搜索智能体面临的困境——它们无法「记住」之前的探索经验,每次都是从头开始,导致大量冗余搜索和资源浪费。
现有的深度搜索智能体大多基于 ReAct 框架构建,采用线性推理方式:「思考→调用工具→观察→再思考」。这种设计在简单任务上表现良好,但在需要多轮探索的深度搜索任务中,往往陷入局部最优、重复探索和低效搜索的困境。
来自东南大学、微软亚洲研究院等机构的研究团队提出了一种全新的解决方案——Re-TRAC(REcursive TRAjectory Compression),这个框架让 AI 智能体能够「记住」每次探索的经验,在多个探索轨迹之间传递经验,实现渐进式的智能搜索。

ReAct 框架的核心问题在于其线性设计。每个探索轨迹都是独立的,模型无法回顾先前尝试的状态。在长上下文场景下,早期制定的计划逐渐被遗忘,关键线索被埋没。
研究团队通过深入分析发现,现有深度搜索模型即使经过大量强化学习训练,其 Pass@K 性能仍远高于 Pass@1。这意味着模型本身具备解决问题的推理能力潜能,问题在于受限于上下文长度限制,单次探索难以生成足够多样的探索路径,无法覆盖足够宽广的搜索空间。
Re-TRAC 的核心思想是将探索从一系列独立尝试转变为渐进式学习过程。具体而言,在每个探索轨迹结束时生成一个结构化的状态表示,针对深度搜索任务,记录以下三个维度的信息:
这个结构化状态将被添加到下一轮探索的输入中,确保智能体在每轮新尝试开始时,都能清楚地了解什么已被验证、什么仍未解决,以及应该将探索重点放在哪里。
研究团队在五个具有挑战性的搜索导向基准上评估了 Re-TRAC:BrowseComp、BrowseComp-ZH、XBench、GAIA 和 HLE。
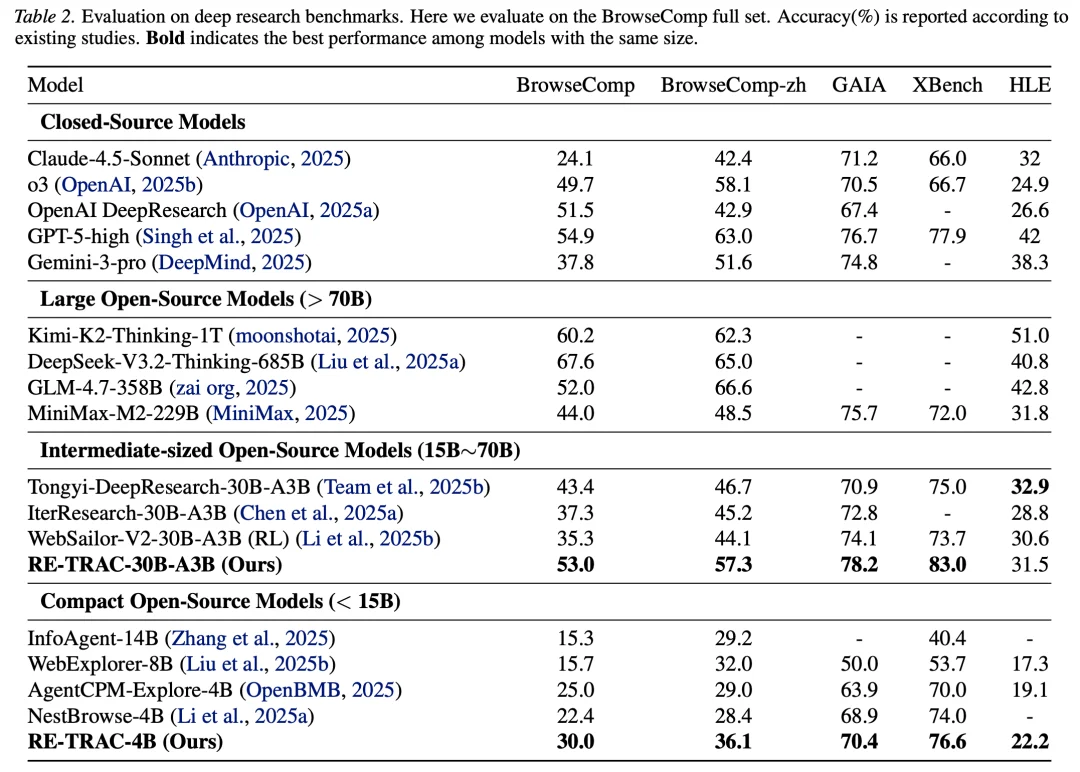
RE-TRAC-4B 在所有小于 15B 参数的基线中表现最佳:
更令人惊讶的是,这个仅 4B 参数的模型在多个基准上超越了更大规模的模型。
RE-TRAC-30B 同样表现出色,在除 HLE 外的所有基准上都击败了 MiniMAX-M2-229B。
这些结果说明,通过轨迹压缩与跨轮次信息传递,小模型在资源受限场景下也能获得接近甚至超过更大模型的效果。
Re-TRAC 不仅可以通过训练提升小模型性能,还可以作为无需训练的测试扩展直接应用于前沿模型。
研究团队在 o4-mini、o3、GPT-5、DeepSeek-V3.2、GLM-4.7 和 MiniMax-M2.1 上实现了 Re-TRAC 框架,并与多数投票(Majority Voting)、加权投票(Weighted Voting)和最佳选择(Best-of-N)等方法进行了对比。
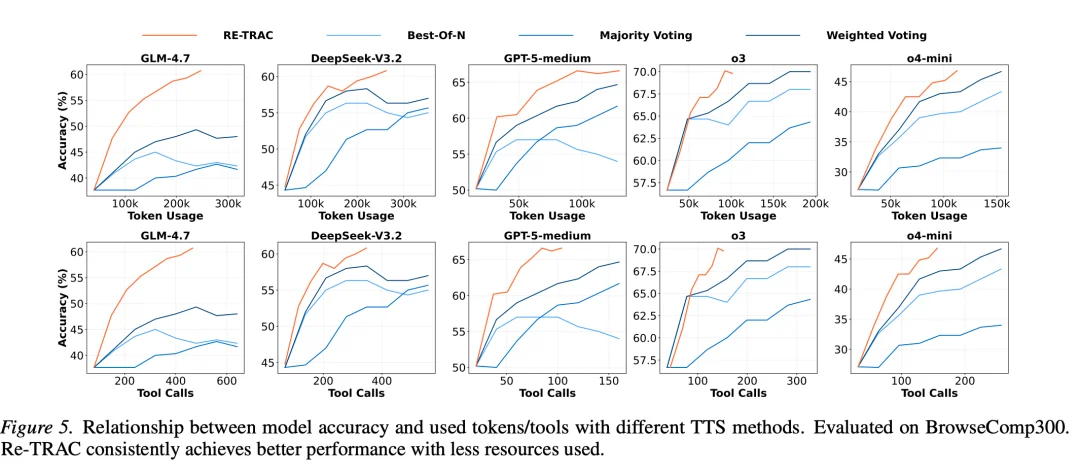
结果显示,Re-TRAC 在所有模型上都达到了最佳或具有竞争力的性能。在 BrowseComp300 子集上:
在传统框架中,由于轨迹相互独立,资源使用量通常随扩展近似线性增长。Re-TRAC 会继承之前轮次的状态,使搜索空间逐步收敛,从而减少冗余工具调用与重复探索,提升探索的效率。
研究团队开发了一种后训练方法,构建了基于结构化状态表示的监督微调(SFT)数据。训练数据通过实体树方法构建:从维基百科收集大量实体作为树根,然后递归搜索相关实体作为子节点,直到树达到预定义深度。
通过选择从根到叶节点的路径并将边转换为子问题,团队合成了 33K 个问答对。然后,收集 GLM-4.7 在这些合成问题上的 Re-TRAC(4 轮)轨迹,经过过滤后得到 104k 个训练样本,用于训练 RE-TRAC-4B 和 RE-TRAC-30B 模型。
实验结果显示,经过 SFT 训练后,Qwen3-4B-Instruct 在 BrowseComp 上的准确率从 2.7% 大幅提升到 30.0%,在 BrowseComp-ZH 上从 6.9% 提升到 36.1%,在 GAIA 上从 24.4% 提升到 70.4%,在 XBench 上从 45.0% 提升到 76.6%。
这表明通过简单的 SFT 训练,配合 Re-TRAC 框架,可以产生强大的搜索智能体,实现与通过大规模强化学习训练的模型相当甚至更好的性能。
Re-TRAC 可以看作是针对深度搜索任务优化过的 ReAct 框架:在原有「思考→调用工具→观察→再思考」的范式上,引入了跨轮次的轨迹压缩和结构化状态表示,让智能体在开放网络检索、复杂信息汇总等场景中不再「从零开始」,而是像人一样复用既有证据、总结失败教训并规划未来方向。
更重要的是,这种有针对性的框架设计让小模型也能跑出大模型级别的效果,为资源受限场景(如边缘设备、本地部署)提供了一条「用小模型做大事」的现实路径。
文章来自于微信公众号 "机器之心",作者 "机器之心"


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
