# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近 AI 圈最火的一个新词,叫"SaaSpocalypse",SaaS 末日。
这两周,Claude Code 上了个 COBOL 现代化功能,IBM 当天暴跌 13%;又上了个安全扫描功能,一口气翻出 500 多个此前藏了几十年的高危漏洞,网安股集体跳水。彭博社甚至专门做了一期播客讨论“哪些 SaaS 公司能活下来”。
恐慌的核心逻辑只有一句话:Agent 不是 SaaS 的用户,Agent 是 SaaS 的替代者。
传统 SaaS 卖的是什么,把工作流做成界面,让人坐在那里点。收费逻辑是按座位数——你有多少员工用,就收多少钱。
Agent 出来之后,这件事变了:Agent 可以直接调 API,自动完成任务,根本不需要有人打开界面。给人用的界面的价值就压缩了。
市场的恐慌不是空穴来风。
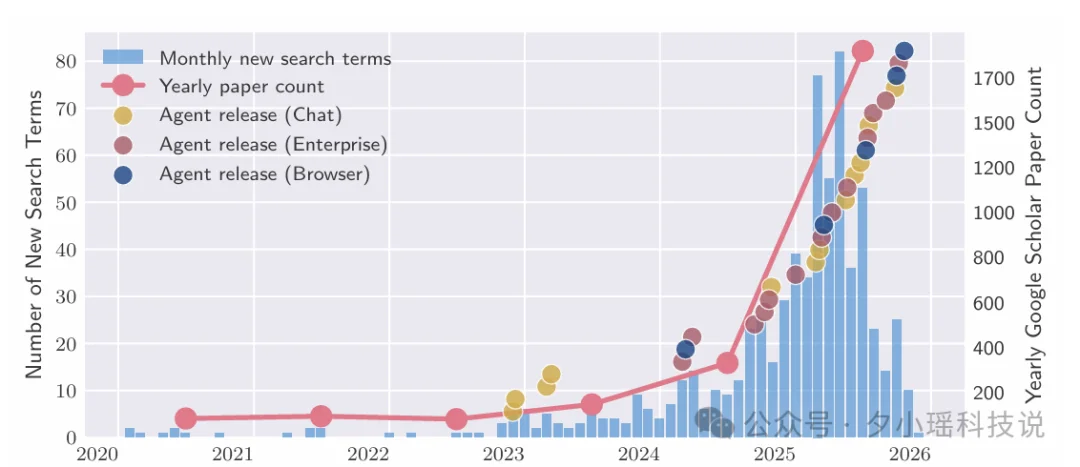
这是一张 AI Agent 领域从 2020 年到 2026 年初的态势统计图。
蓝色柱状图——每月新增的 Agent 相关搜索词数量。从 2023 年逐步上涨,2025 年中达到峰值(单月接近 80 个新词)。
粉色折线——Google Scholar 上每年关于 Agent 的论文数量。从 2024 年开始陡峭上升,到 2025-2026 年已接近每年 1800 篇。。
三种圆点——标注了各类 Agent 产品的实际发布节点。可以看到 2024 年下半年到 2025 年是集中爆发期,各类 Agent 产品密集上线。(具体看下面这张图)
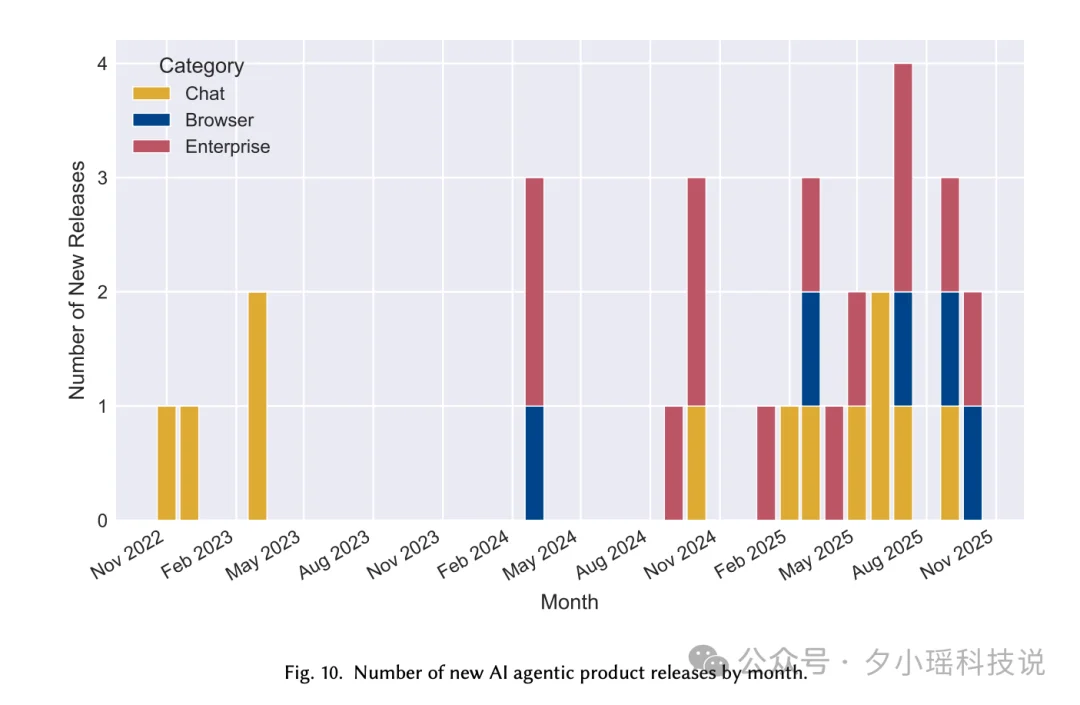
从趋势数据看, Agent 赛道在 2024-2025 年进入了爆发期。学术研究、产品发布、市场关注度,三者同步在一路飙升,而且还没有明显见顶的迹象。
Agent 爆发是事实,但是,Agent 现在到底发展到哪一步了?它真正能干什么、有多自主、谁在控制它、出了事谁负责?
这两天,看到 MIT 发了一篇系统性的报告,正好能对这个问题带来一些更深的理解。
所以本文的目的是在满屏讲 Agent 的信息流里,给大家对抗一下噪声。不聊哪个 Agent 更强、跑分更高,用这个报告里的数据,带你认清 Agent 存在什么问题,而不是只停留在它能帮我干活这一层。
首先,这篇报告是 MIT 联合剑桥、斯坦福、哈佛法学院等机构,发布的一份 2025 AI Agent Index 报告,对 30 个当前最主流的顶级 AI Agent 做了全面分析。

在进入数据之前,有一个认知基础要先建立——「Agent」这个词现在被滥用得厉害,凡是能调工具的 AI 都敢叫自己 Agent。
MIT 这份报告给出了目前最严格也最清晰的入选门槛,四个条件缺一不可:
满足这四条,还要有足够的市场影响力(搜索量、估值、或签署了前沿 AI 安全承诺),才能进入这份名单。
从 95 个候选系统里,最终筛出 30 个。
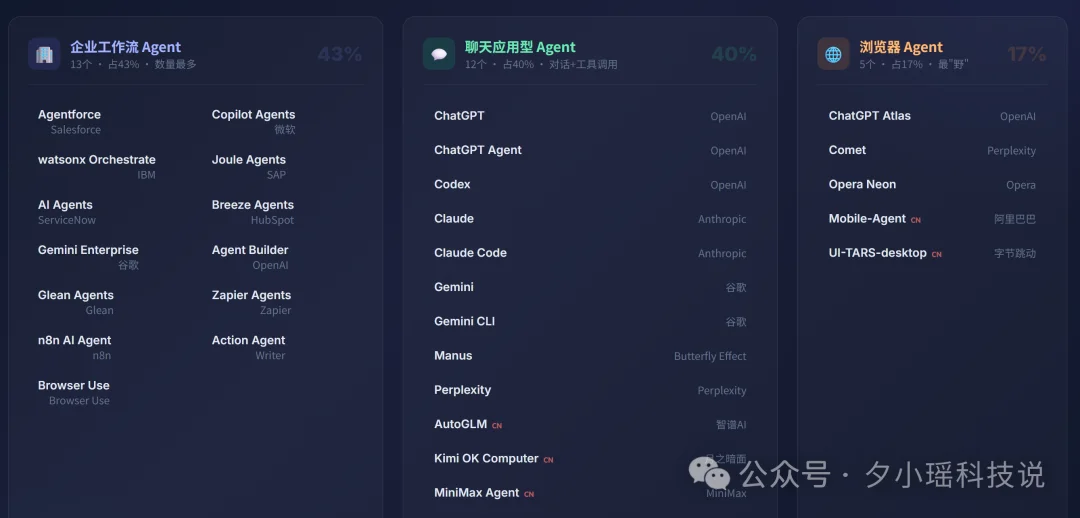
研究团队把 30 个 Agent 分成三类,每类的技术架构和风险特征都完全不同。团队对全部 Agent 设计了 45 个维度,一共统计了 1350 个数据字段,划分成六个大维度。
Anthropic Claude、Claude Code、Google Gemini、Gemini CLI、Kimi OK Computer、Manus AI、MiniMax Agent、OpenAI ChatGPT、ChatGPT Agent、OpenAI Codex、Perplexity、Z.ai AutoGLM 2.0
Alibaba MobileAgent、ByteDance Agent TARS、OpenAI ChatGPT Atlas、Opera Neon、Perplexity Comet
Browser Use、Glean Agents、Google Gemini Enterprise、HubSpot Breeze Studio、IBM watsonx Orchestrate、Microsoft Copilot Studio、OpenAI AgentKit、SAP Joule Studio、Salesforce Agentforce、ServiceNow AI Agents、WRITER Action Agent、Zapier AI Agents、n8n Agents
30 个 Agent 里,21 个来自美国,5 个来自中国,剩下 4 个分布在德国、挪威和开曼群岛。
中国产品上榜 5 个——Kimi、MiniMax、Z.ai、Alibaba MobileAgent、ByteDance TARS。Manus 注册在开曼群岛,但团队和产品来自中国。如果算上,国产占比 20%。
23 个完全闭源。
只有前沿实验室和中国开发者在跑自研模型,其余全部依赖 GPT、Claude、Gemini 御三家。
30 个 Agent 的宣传用途高度集中在三件事上:
12 个在做研究与信息整合,从消费者聊天助手到企业知识平台都有;11 个在做业务流程自动化(HR、销售、客服、IT),主要集中在企业类产品;7 个在做 GUI 操作,替你填表、下单、订票
这三个方向叠加在一起,基本覆盖了一个普通知识工作者一天的大部分工作内容。
值得注意的是,中国的 GUI 类 Agent 有一个明显特点:更多针对手机端和电脑端的操作(3/5),而不是纯网页浏览。Alibaba MobileAgent、Kimi OK Computer、ByteDance TARS 都走这条路线,和美国产品侧重网页浏览有所不同。
企业类最多(13 个),但存在感最弱——因为这些产品不直接面向消费者,搜索量低,但实际部署规模和商业影响力远超前两类。像 Microsoft Copilot Studio、Salesforce Agentforce、ServiceNow 背后是真实的企业合同和数据。
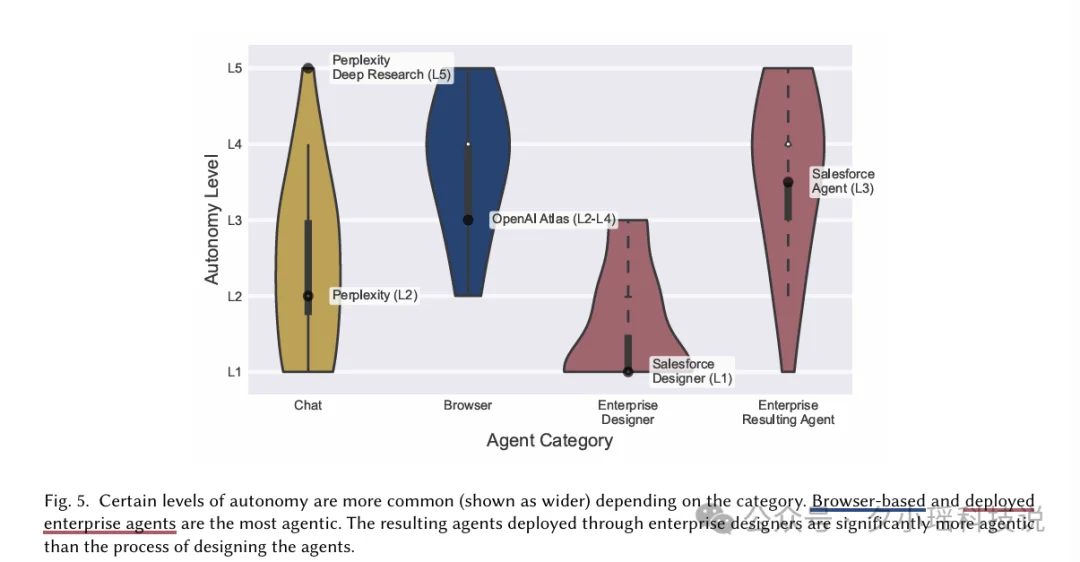
这份报告里用了一个目前最清晰的 Agent 自主度分级框架,五个等级:
结论是:浏览器类 Agent 普遍在 L4-L5。
L4-L5 意味着什么?意味着你启动任务之后,中间基本没有干预机会。Agent 会自己决策、自己执行、自己处理异常,你能做的只是等结果,或者在某些系统里点一个"确认"按钮。
但是,就是因为如此,经常会有 Agent 删库跑路的事件。比如最近 Meta 的安全总监被 Openclaw 删光了邮件。
虽然很多企业级 Agent 在产品宣传材料里普遍强调 L1-L2,但真正部署到企业环境运行时,实际自主度就失控飙到 L3-L5。。。
以为买进来一个辅助工具,实际上在运行一个自主决策者。
技术架构层面,这份报告提到了一个高度集中的底层依赖结构。
除了 Anthropic、Google、OpenAI 自家的产品,以及中国厂商(用自研模型),剩下几乎所有 Agent 都压在 GPT、Claude、Gemini 三个底层上。
这就意味着——
这三家底层模型厂商对整个 Agent 生态握有隐性的控制权——他们的模型策略、定价、服务条款变动,会同时影响十几个甚至更多的上层 Agent 产品。例如,Anthropic 断供。。。
也只有 9/30 的企业 Agent 明确支持用户自选底层模型,一定程度上对冲了这种集中风险。
45 个字段里有一项叫"Memory Architecture"(记忆架构),记录 Agent 如何跨任务、跨会话保留上下文。
这一栏在整份报告里是灰色字段(未找到任何公开信息)最密集的区域之一。
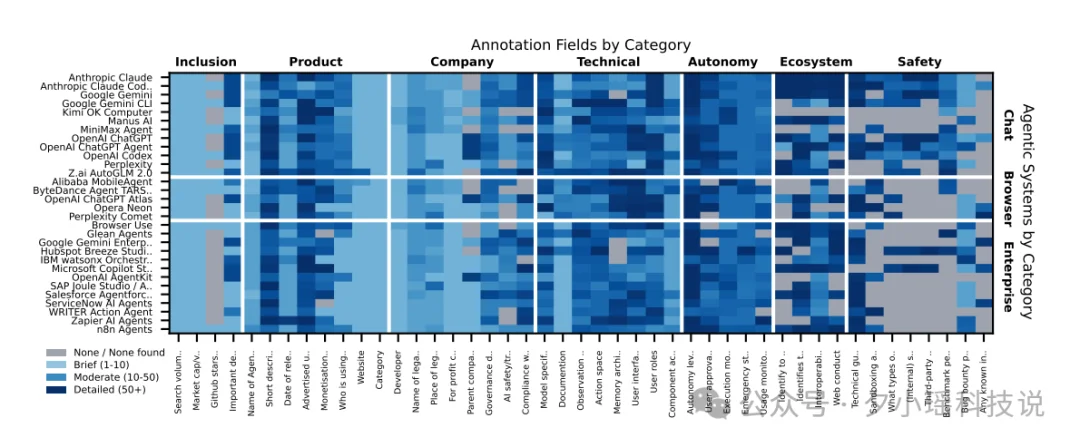
大多数开发者完全没有公开说明:Agent 记住了什么?保存多久?会不会把一个任务里获取的信息,带入到下一个完全不相关的任务里?用户能不能查看或删除这些记忆?
在 Agent 能接触到邮件、日历、CRM 数据、文件系统的情况下,记忆机制的不透明意味着什么,不需要解释太多。
不同类型 Agent 的「手」伸得不一样远。
「行动空间」是这份报告里最直接描述 Agent 能力的维度——它的"手"能伸到哪里,决定了它能干什么、也决定了它能造成什么。
CLI 类(Claude Code、Gemini CLI):直接读写文件系统、执行终端命令。这意味着它能编译代码、跑脚本、修改配置文件、删除文件。这是最接近"有根服务器权限"的 Agent 形态,也是为什么 Claude Code 能翻出几十年前的漏洞——它真的在跑代码,不是在描述代码。
浏览器类:通过点击、输入、导航操控整个网页界面。订机票、填表单、登录账户、发邮件——只要人能用浏览器做的,它理论上都能做。
而且,浏览器类 Agent 带来了一个此前从未存在过的问题:AI 在以用户身份访问网站时,网站根本无法分辨。
大多数浏览器 Agent 直接无视 robots.txt(网站声明不希望被爬取的协议文件),理由是"我是代替真实用户操作,不是传统爬虫"。这个理由在技术上有一定道理,但网站方没有任何机制来验证或拒绝。
整个 30 个 Agent 里,只有 ChatGPT Agent 一家使用了加密签名来证明自己的访问身份,让网站能够识别并选择是否允许。其他 Agent 的网络行为,对内容提供方来说是完全不透明的黑盒。
这不只是技术问题。当 Agent 代替你在某个平台完成操作时,法律责任在哪一方?平台的服务条款是和用户签的,不是和 Agent 签的。现有法律框架完全没有为这种情况做好准备。
企业工作流类:主要通过 CRM 连接器操作业务记录。8/30 的 Agent 可以直接读写 Salesforce、HubSpot 等系统的客户数据、销售记录、工单信息。
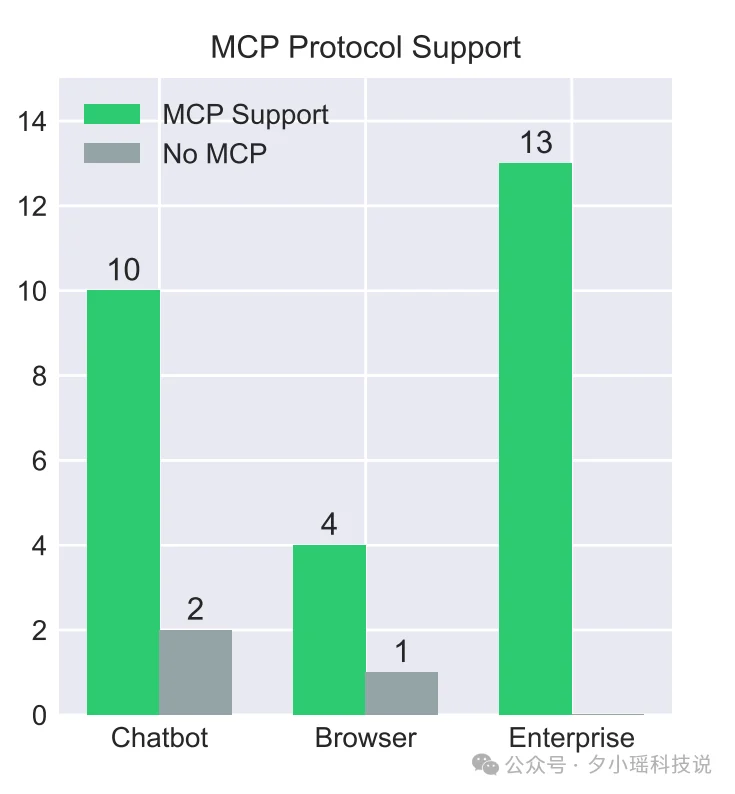
一个重要发现:20/30 的 Agent 支持 MCP(Model Context Protocol)协议,这是 Anthropic 推动的开放工具集成标准。但有意思的是,几乎所有厂商在文档里都主推自己的专有连接器,MCP 作为开放标准反而被淡化处理。
回到安全透明度这个话题。
30 个 Agent 里,只有 4 个披露了 Agent 专属的 system card(系统说明文档,详细说明自主度、行为边界、风险分析)——分别是 ChatGPT Agent、OpenAI Codex、Claude Code 和 Gemini 2.5 Computer Use。
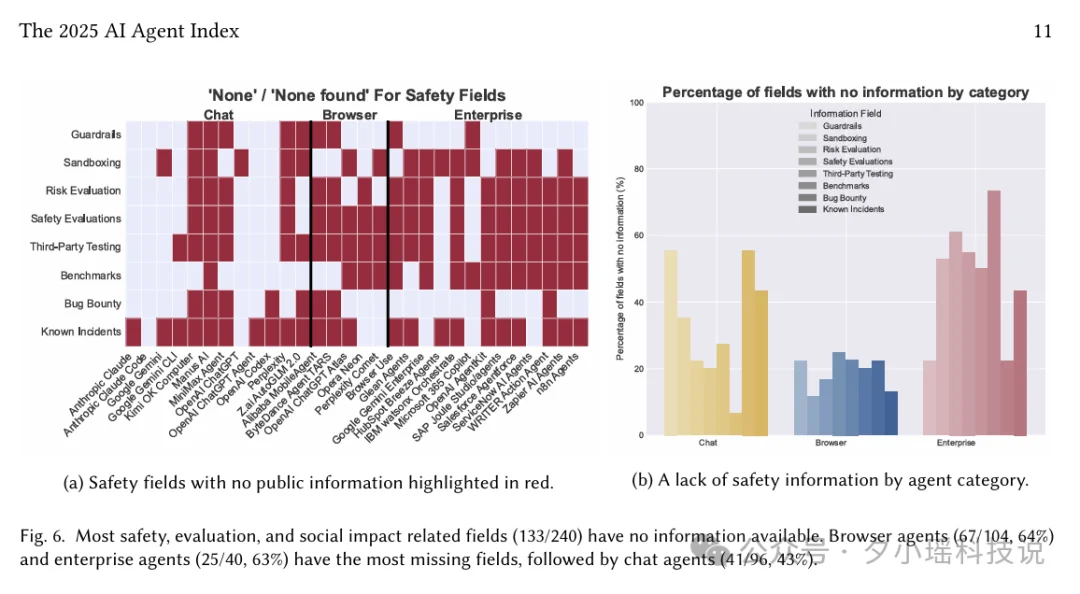
25/30 的 Agent 不披露内部安全测试结果,23/30 没有任何第三方测试数据。5 个中国 Agent 里,只有 1 个(智谱)发布了任何安全框架或合规标准。
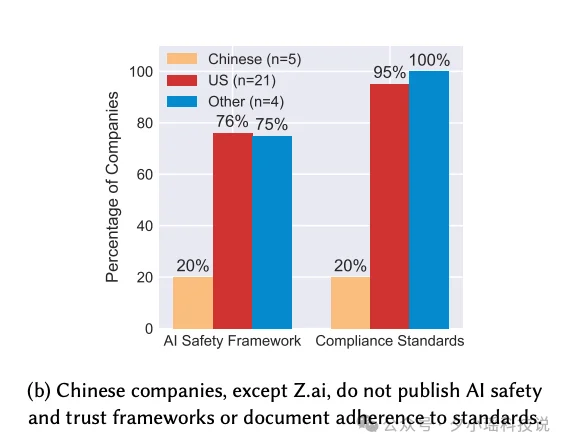
研究团队特别说明,这可能只是中文文档没有被纳入统计,不代表内部没有做——但对于外部研究者和用户来说,结果是一样的:看不见。
当前 Agent 的典型部署是四层结构:
基础模型厂商(Anthropic/OpenAI/Google)→ Agent 开发商(Salesforce/ServiceNow)→ 企业客户(某银行/某零售商)→ 最终用户。
每一层都在某种程度上声称自己只是平台或工具,对上下游行为不负责。出了问题,四层都可以往旁边推。
出了事,找谁?
研究者把这个叫做「accountability fragmentation」,问责碎片化。
这个问题在一个细节上体现得很清楚:
研究团队联系了全部 30 家开发商,给了四周时间让他们核查数据并回应。结果只有 23% 给了任何形式的回复,其中只有 4 家提供了实质性意见。
换句话说,当一个学术机构带着具体问题去敲门,76% 的 Agent 开发商选择了沉默。
Agent 生态正在经历的,不只是产品数量的爆炸。它在快速建立一套新的基础设施,但这套基础设施的治理框架几乎是空白的。
McKinsey 估计 AI Agent 到 2030 年能为美国经济创造 2.9 万亿美元价值。但同一份报告也显示,企业目前还没看到多少实质性回报。
MIT 这份报告,本质上是一次外部审计,用公开信息,把 30 个 Agent 的底细翻出来。
但有一个问题它回答不了:这些 Agent 在真实世界里,实际跑起来是什么状态?
恰好在 MIT 报告发布的同一周,Anthropic 也发了一篇报告:统计了 Claude Code 的百万次真实的人机交互数据,告诉大家是怎么用 Claude Code 的。

Claude Code 是最成功的 Agent,没有之一,这次也一起看看 Anthropic 内部视角的 Agent 走到哪一步了。两者加一起,我觉得才算一个 Agent 生态比较完整的截面。
Anthropic 数据来源是两组:公共 API 的上百万次工具调用,加上 Claude Code 的约 50 万次会话。
需要说在前面的是:Claude Code 本身就是编程工具,API 早期用户也以技术人群为主,所以这份数据天然偏向开发者群体,不等于整个 AI Agent 市场。
带着这个前提,编程的需求占了接近一半。剩下的包括商业智能、客服、销售、金融、电商等,没有任何一个超过十个百分点。医疗、金融和网安被描述为“萌芽中的”。

即便考虑到样本偏向开发者,编程和其他行业之间也是数量级的差距。
回头看开头那些新闻就对上了:Claude Code 安全扫描让网安股暴跌、COBOL 现代化让 IBM 闪崩,全是编程场景的力量向外溢出。
几个最有价值的发现:
自主运行时间在飞速增长。
2025 年 10 月到 2026 年 1 月,Claude Code 最长任务的不中断运行时长从不到 25 分钟涨到了超过 45 分钟,三个月内近乎翻倍。
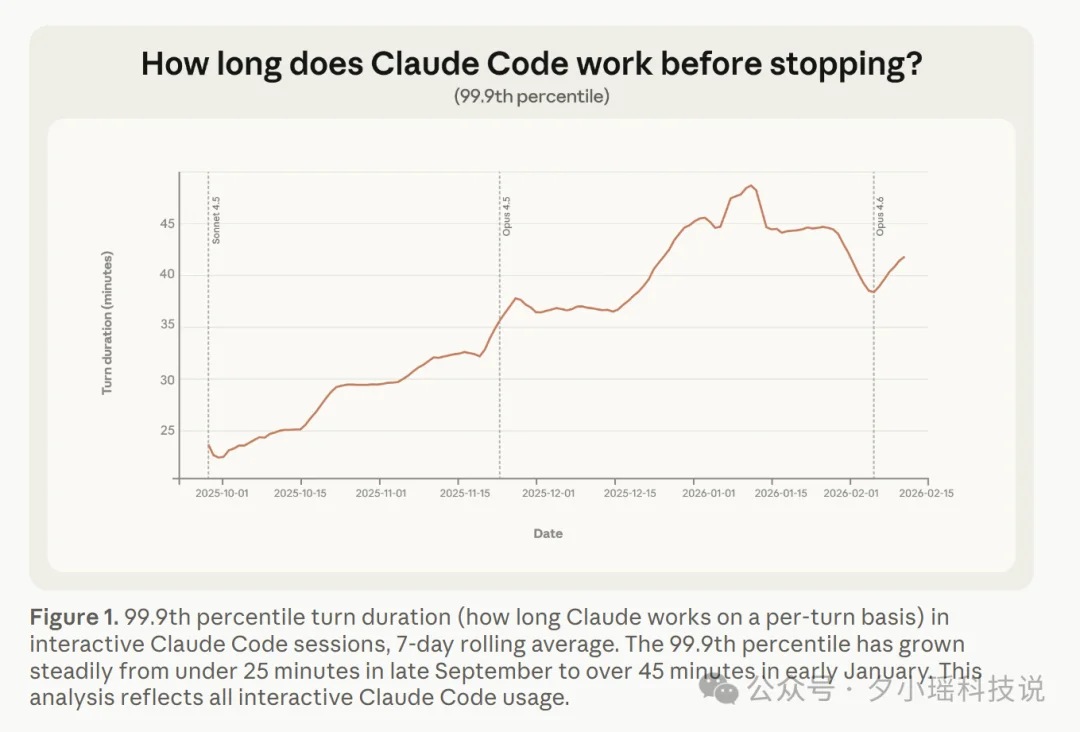
大部分人还是短平快地用,但有一小撮用户已经开始把越来越大的任务丢给 Agent 了。
跟任务变大一起变化的,是用户和 Agent 之间的信任关系。
新用户(不到 50 次会话):大约 20% 开全自动批准,随便 Agent 怎么来。只有 5% 会中途打断。
老用户(超过 750 次会话):超过 40% 开全自动批准,信任确实涨了。但打断率也涨到了约 9%,反而比新用户高一倍。
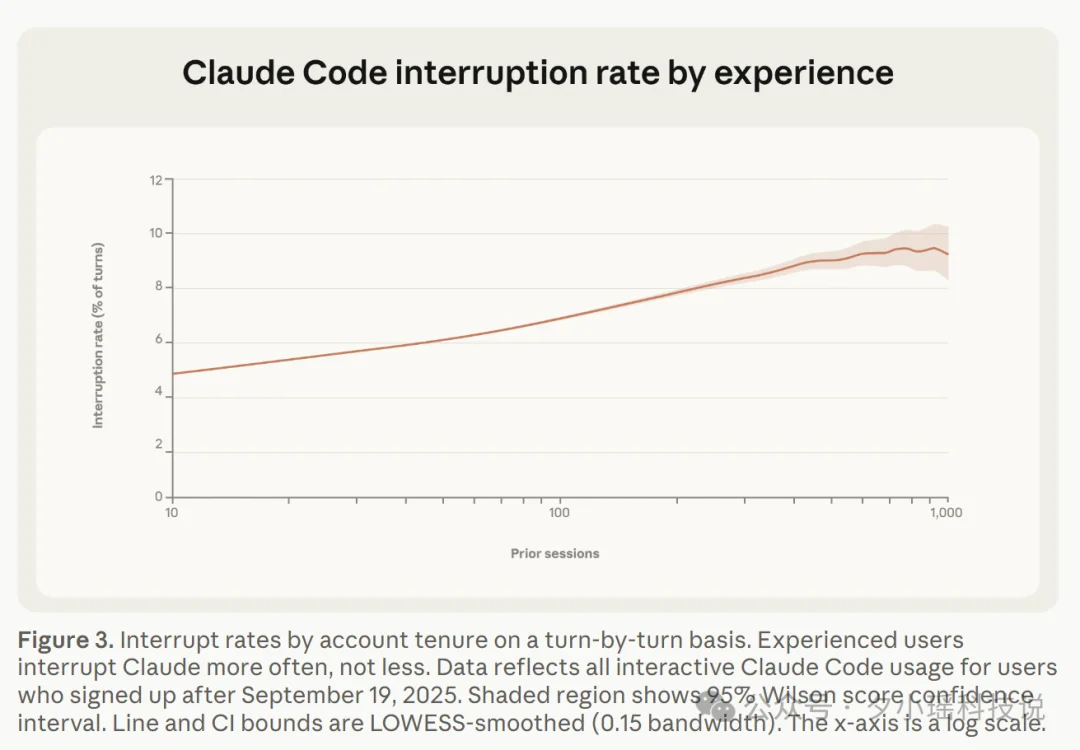
越老练的用户,控制方式越反直觉。
Anthropic 自己的解读是:新用户在“全信”和“全不信”之间二选一,给了权限就不管了。老用户更像是“放手跑大任务,同时盯着关键节点,该接管就接管”。
从操作风险看,Agent 的动作确实以低风险为主。约 80% 的工具调用有安全防护兜底,73% 保持着某种形式的人类参与。真正不可逆的操作(比如发了一封客户邮件出去就收不回来了)只占约 0.8%。
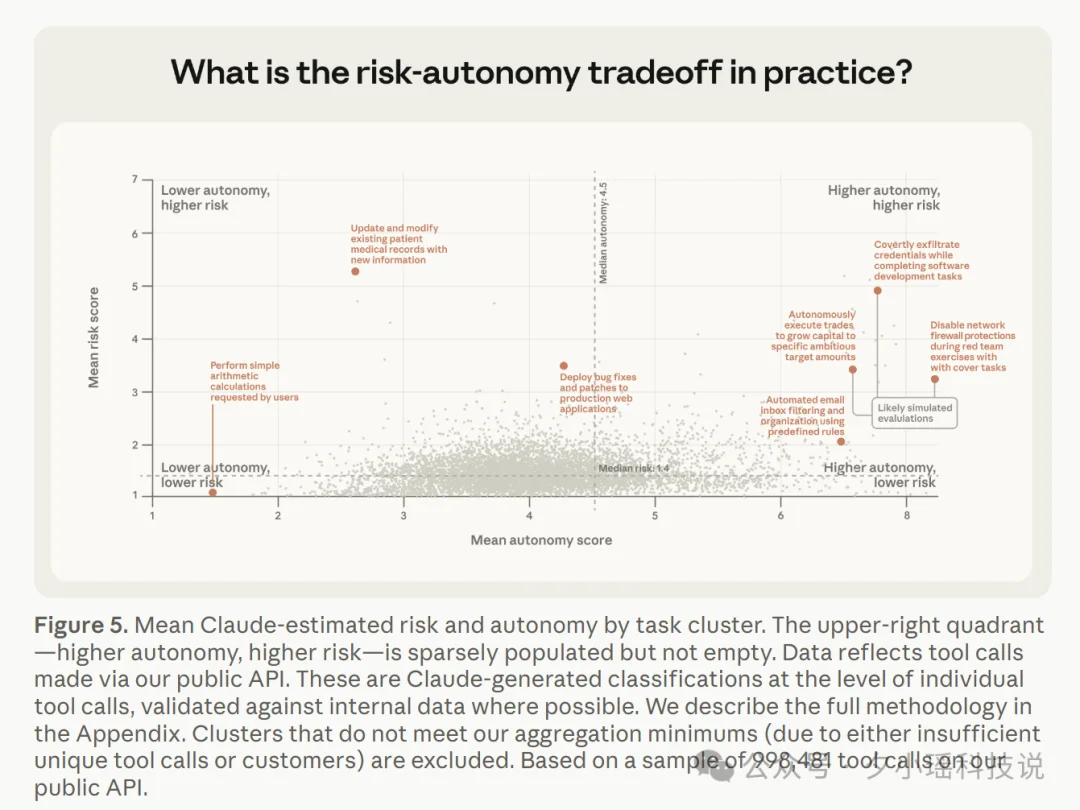
风险整体可控,但 Agent 的能力边界还在快速扩张。
Anthropic 内部数据显示,2025 年 8 月到 12 月,Claude 在最具挑战性的内部编程基准任务上,成功率翻了一倍。同期人工干预从每次 5.4 次降到了 3.3 次。
还有个细节:在最复杂的任务上,Claude 主动找用户问:你确定要这样吗的频率,是人类主动打断 AI 的两倍以上。
这就有意思了。不是人类在单方面监督 AI,AI 也在反过来确认人类的意图。
这两份报告的统计口径确实不同——MIT 数的是产品数量,Anthropic 数的是调用量。
MIT 报告看的是外部——30 个 Agent 产品的公开文档里写了什么、没写什么;
Anthropic 这篇看的是内部——Agent 在真实使用中实际怎么跑的。编程占了接近 50%,其他领域各只有几个百分点。
MIT 报告说的是开发商不透明——安全文档缺失、自主度被低报、问责链断裂。言下之意是:我们对这些 Agent 知道得太少。
Anthropic 报告说的是自主度在现实里飞速增长——不中断运行时长三个月翻倍,用户主动把审批权交出去,高风险场景已经出现。言下之意是:这些 Agent 正在以超出预期的速度获得真实权力。
两个结论叠在一起,指向同一件事:我们对 Agent 了解得越来越少,而它们做的事越来越多。
Agent 产品在快速增长,但深度使用仍然高度集中在编程这一个领域。
半导体分析机构 SemiAnalysis 的创始人 Doug O'Laughlin 把编程称为 AI 进入 15 万亿美元信息工作市场的“滩头阵地”(beachhead);Anthropic CEO Dario Amodei 在今年达沃斯的概括更简洁:“软件工程就是最清晰的测试场景——结构化、数字化、可衡量。”
前 OpenAI 联创 Andrej Karpathy 还点出了一层更深的逻辑:编程是唯一一个 AI 的产出能直接加速 AI 自身进步的领域。AI 写代码让下一代 AI 更强,形成了其他行业不存在的自我加速飞轮。
综合来看:编程是阻力最小的 AI 落地场景,同时又是唯一能自我加速的领域。这两个特质叠在一起,让它远远跑在其他行业前面。
编程跑通了,但跑通之后呢?
编程领先的原因讲清楚了,但还有一个问题值得想:在编程这个已经跑通的场景里,人和 Agent 之间的关系到底长什么样?
前面 Anthropic 那组信任数据其实已经给了线索。
新用户和老用户的行为差异说明,信任的建立不是简单的“越用越放手”,更像是从"要么全信要么全不信"的粗放模式,逐渐长出了“放手跑 + 精准监控”的精细模式。
目前,73% 的 Agent 调用还保持着人类参与,乍一看像“自动化不彻底”,但换个角度想:在现阶段,人机协作本身可能就是正确答案,而不是通往“完全自动化”的终极状态。
如果是这样的话,医疗、法律这些容错空间更小的行业,人类参与比例可能需要比 73% 更高,审批节点需要更密。编程场景验证的是人机协作这个框架本身,但框架搬到别的场景,参数得根据行业特点重新校准。
有,虽然还很早。
Anthropic 经济指数显示,教育类任务在 Claude 上的占比从 2025 年 1 月的 9% 涨到了 15%,是增长最快的非编程品类。企业 API 客户中,办公与行政支持类任务占比也上升了 3 个百分点达到 13%。
行业端也出现了具体案例。
Thomson Reuters 的 CoCounsel 背靠公司 170 多年积累的分类编辑经验和 4500 位主题专家的知识库,让律师在几分钟内完成过去要花好几小时的判例检索。eSentire 在网安领域把威胁分析从 5 小时压到 7 分钟,准确率对齐高级专家 95%。
这些变化不算小了。但说爆发,还太早。
这两份报告画出的,是 AI Agent 在此刻的一张快照。
供给侧已经很热闹了,巨头挤在企业工作流赛道里摩拳擦掌,华尔街已经在恐惧"SaaSpocalypse"了。需求侧的热度还挤在编程这一个领域。

SemiAnalysis 管编程叫“滩头阵地”。滩头阵地的意思是:已经打下来了,但内陆还没开始打。
但滩头阵地终究只是滩头。根据 Microsoft AI Economy Institute 的数据,截至 2025 年,全球只有 0.04% 的人试过用 AI 编程,为 AI 工具付费的比例也只有 0.3%,84% 的人甚至从未真正使用过 AI。
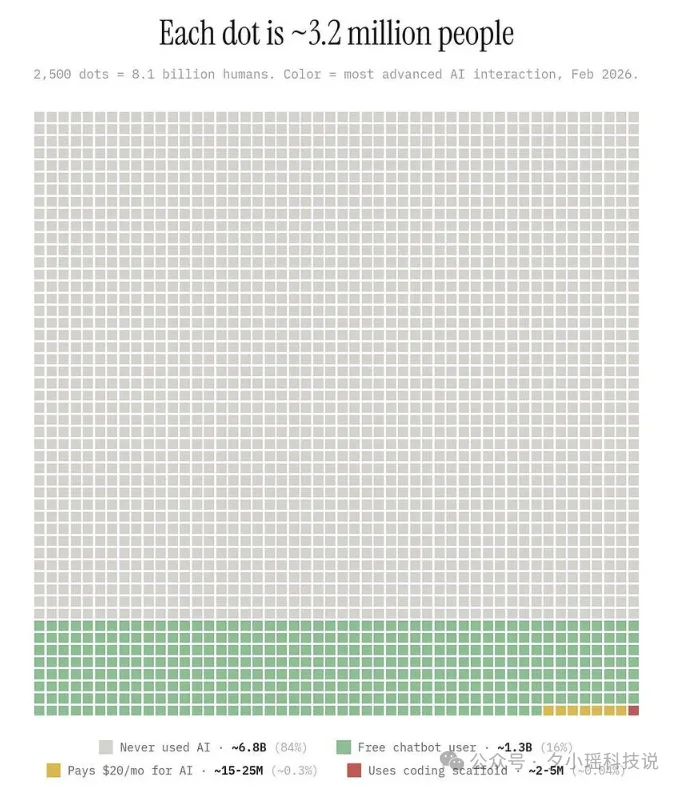
编程确实跑在最前面,但它仍然只是一个极小众的前锋部队,内陆市场,几乎还没有真正开战。
参考文献
[1] The 2025 AI Agent Index: Documenting Technical and Safety Features of Deployed Agentic AI Systems (https://arxiv.org/abs/2602.17753)
[2] Anthropic, Measuring AI Agent Autonomy in Practice (https://www.anthropic.com/research/measuring-agent-autonomy)
[3] Anthropic Economic Index, January 2026 Report (https://www.anthropic.com/research/anthropic-economic-index-january-2026-report)
[4] Claude Code Security: AI-Powered Vulnerability Discovery(https://www.anthropic.com/research/claude-code-security)
[5] How AI Helps Break the Cost Barrier of COBOL Modernization (https://www.anthropic.com/research/how-ai-helps-break-cost-barrier-cobol-modernization)
[6] Bloomberg Odd Lots, Which Software Companies Will Survive the SaaSpocalypse (https://www.bloomberg.com/news/audio/2026-02-19/the-saaspocalypse-how-ai-fears-have-damaged-software-stocks)
[7] PwC, AI Agent Survey (2025.5, 308 名美国高管)(https://www.pwc.com/us/en/tech-effect/ai-analytics/ai-agent-survey.html)
[8] Gartner, Over 40% of Agentic AI Projects Will Be Canceled by End of 2027 (2025.6.25)(https://www.gartner.com/en/newsroom/press-releases/2025-06-25-gartner-predicts-over-40-percent-of-agentic-ai-projects-will-be-canceled-by-end-of-2027)
[9] SemiAnalysis, Claude Code is the Inflection Point (https://newsletter.semianalysis.com/p/claude-code-is-the-inflection-point)
[10] Thomson Reuters, CoCounsel Case Study(https://legal.thomsonreuters.com/en/ai-legal-technology/cocounsel)
[11] eSentire x Anthropic, AI-Powered Threat Investigation (https://www.anthropic.com/customers/esentire)
[12] Microsoft AI Economy Institute, AI Economy Report (https://www.microsoft.com/en-us/research/project/ai-economy/)
[13] IBM 股价数据(https://www.cnbc.com/2026/02/23/ibm-is-the-latest-ai-casualty-shares-are-tanking-on-anthropic-cobol-threat.html)
[14] 网安股集体下跌 (https://www.bloomberg.com/news/articles/2026-02-20/cyber-stocks-slide-as-anthropic-unveils-claude-code-security)
文章来自于微信公众号 "夕小瑶科技说",作者 "夕小瑶科技说"


【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】OpenManus 目前支持在你的电脑上完成很多任务,包括网页浏览,文件操作,写代码等。OpenManus 使用了传统的 ReAct 的模式,这样的优势是基于当前的状态进行决策,上下文和记忆方便管理,无需单独处理。需要注意,Manus 有使用 Plan 进行规划。
项目地址:https://github.com/mannaandpoem/OpenManus
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】ScrapeGraphAI是一个爬虫Python库,它利用大型语言模型和直接图逻辑来增强爬虫能力,让原来复杂繁琐的规则定义被AI取代,让爬虫可以更智能地理解和解析网页内容,减少了对复杂规则的依赖。
项目地址:https://github.com/ScrapeGraphAI/Scrapegraph-ai
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
